《开立医疗》专题
-
用Kafka建立数据模型?主题和分区
在使用新服务(如非RDBMS数据存储或消息队列)时,我首先想到的一件事是:“我应该如何构造我的数据?”。 我看了一些介绍材料。特别地,以Kafka为例:一个用于日志处理的分布式消息传递系统,它写道: “主题是与消息关联的容器” “最小的并行单位是主题的分区。这意味着属于主题的特定分区的所有消息都将被使用者组中的使用者使用。” 了解了这一点,说明如何使用主题和分区的好例子是什么呢?什么时候某件事应该
-
zipkin无法建立到RabbitMQ服务器的连接
我在Windows10机器上尝试将RabbitMQ(3.6.11版本与Erlang 20一起安装)连接到ZipKin,但我得到了以下错误: 原因:org.springframework.beans.factory.unsatisfieddependencyException:创建名为“server configurator”的bean时出错,该bean在zipkin2.server.interna
-
如何修复iText中的孤立标点符号
但是,结果是写在第3行和第5行都以标点符号开始的地方,如PDF输出的图像所示 我可以简单地在适当的地方添加一些新的行,以使它看起来正确,但这将意味着,如果文本在内部重新翻译,我的修复可能不再起作用。有人知道如何确保iText不会以这些标点符号开始一行吗?
-
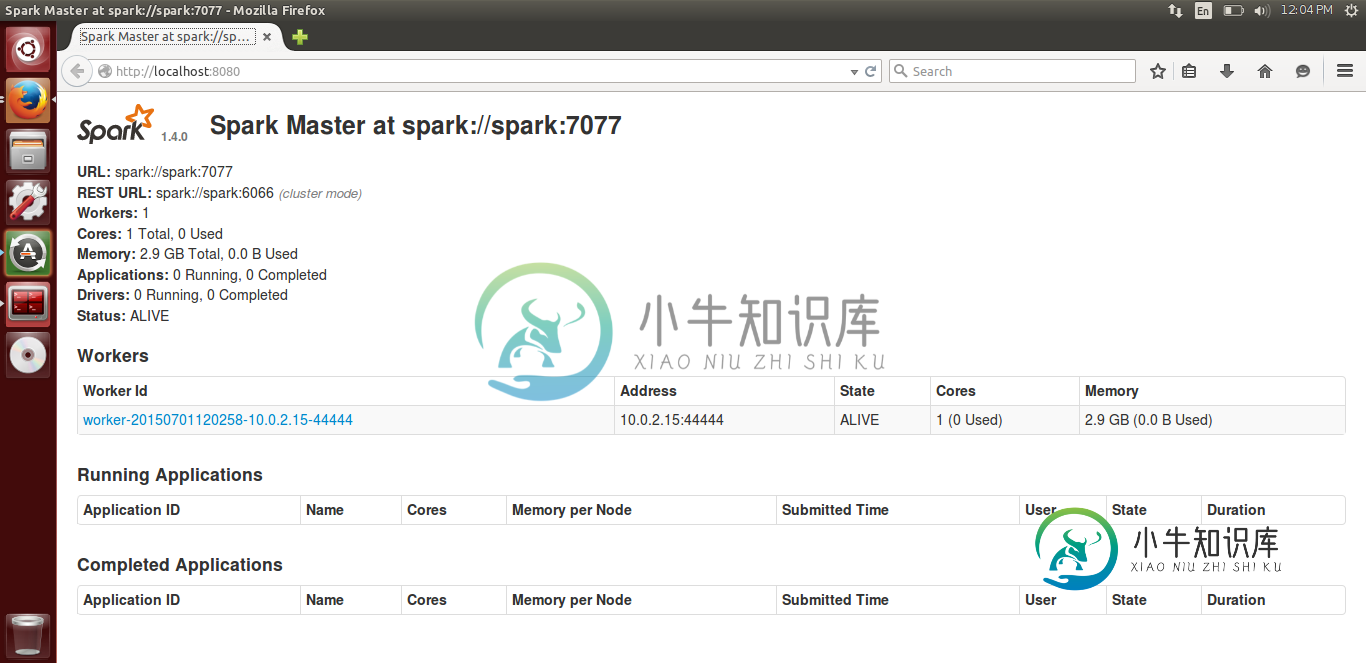 Spark独立集群-从机未连接到主机
Spark独立集群-从机未连接到主机我正试图按照官方文档设置一个Spark独立集群。 我的主人在一个运行ubuntu的本地vm上,我也有一个工作人员在同一台机器上运行。它是连接的,我能够在大师的WebUI中看到它的地位。 以下是WebUi图像- 我已经在两台机器上的/etc/hosts中添加了主IP地址和从IP地址。我遵循了SPARK+独立集群中给出的所有解决方案:无法从另一台机器启动worker,但它们对我不起作用。 我在两台机器
-
PDFBox:“你没有在打印后立即关闭PDFDocument”
我使用以下Java代码打印PDF文档: 控制台上的输出是: 为什么我会收到这个警告?
-
C++OpenGL、GLFW绘制一个简单的立方体
所以,我试图在openGL和GLFW中绘制一个简单的立方体。
-
如何用Quarkus建立多模块分级项目?
在根中应用Quarkus插件的多模块gradle项目在步骤失败,出现: 根如下所示: 但是,将行移动到子项目的中,生成将成功。看来quarkus构建步骤是在插件声明的地方运行的,而不是在插件实际应用的地方。 理想情况下,我希望在根项目中声明一次插件,然后仅将其应用于子项目,而不是在根项目中执行它,在根项目中显然没有什么可构建的。 有什么想法吗?
-
读取主题后立即异步提交消息
我正试着在从主题读到它之后提交一个信息。我通过这个链接(https://www.confluent.io/blog/apache-kafka-spring-boot-application)使用Spring创建一个Kafka消费者。通常情况下,它工作得很好,消费者得到消息,然后等待另一个人进入队列。但问题是,当我处理这些消息时,它会花费很多时间(大约10分钟),kafka队列认为消息没有被消耗(提
-
在独立应用程序中创建JNDI对象
柴图
-
5.18 特殊小节:建立自己的计算机
下面几个问题要暂时离开高级语言编程,打开计算机,看看其内部结构。我们介绍机器语言编程和编写几个机器语言程序。要让这些知识更有价值,我们建立一个计算机(通过软件模拟技术),在其中执行我们的机器语言程序。 5.18(机器语言程序)下面要建立一个 Simpletron 计算机。顾名思义,这是个简单机器,但以后会发现它也是个强大的机器。Simpletron只能运行用Simpletron Machine L
-
E立方Excel服务器平台导航面板
利用系统提供的导航面板设计功能来快速设计出非常专业的导航,而且这种导航会直接嵌入在程序中,这样做不但使用方便而且可以大大提升模板系统的档次。 1、看看导航面板是怎么样的,填报精灵登录后 导航面板 如上图所示,左边列出了当前你有权限使用的导航,你点击其中一个,右边就会显示对应的导航图,如上图所示。 如果我们点击“商品表”图标,系统就会以填报的方
-
E立方Excel服务器数据校验公式
很多时候,在保存数据前需要检查当前的数据是否符合某些特定的要求,如果不符合要求就给出提示信息,并停止保存,例如,我们在保存凭证之前就需要保证借贷必须相等,否则就应该提示“记帐凭证必须借贷平衡”。在E立方中怎么实现呢?答案就是使用“数据校验公式”。 下面我们就以“记账凭证”为例进行说明。 1、我们先按常规步骤建立“记账凭证”模板,如下图所示: 2、 接着设置“数据校验公
-
E立方管理平台支持多账套吗?
支持。不过要使用E立方管理平台的高级版。 高级版支持同时使用多个数据库,可以把非常敏感的数据在物理上把它们保存在独立的数据库上,然后在登录使用的时候指定数据库即可,如下图所示: 与标准版相比,这里多出了“数据库”这一项,输入你要登录到的数据库,如上图的“一分公司”,这样就可以登录到指定的数据库了,登陆以后,在Excel的左下角会显示当前登录的数据库,如下图所示: 登录以后,其他操作跟标准企业版一致
-
os.path — 平台独立的文件名操作工具
解析路径 # ospath_split.py import os.path PATHS = [ '/one/two/three', '/one/two/three/', '/', '.', '', ] for path in PATHS: print('{!r:>17} : {}'.format(path, os.path.split(path)
-
 保利威(立方科技)前端实习 笔试
保利威(立方科技)前端实习 笔试一.不定项选择(10 * 5) 1.生命周期相关 2.Cookie、LocalStorage、SessionStorage区别 3.跨域问题 4.var const let 5.箭头函数,普通函数区别 6.哪些一定不会引起重排四个选项:visible,color,padding,boder 7.原型原型链 8.Vue-Router history和hash 9.盒模型 10.哪些标识符是缓冲相关的