《中车集团》专题
-
JBoss集群中的节点特定配置
我在一个集群中有两个节点;我允许用户有节点特定的配置,如日志级别,本地缓存设置等;有时,管理这些设置变得非常困难,因为用户必须知道或记住应用在特定节点上的配置--在找到该特定节点之前移动一个又一个节点;是否有任何标准或已知的方法可以从单个地方管理这些节点?比如,从httpd服务器本身还是将一个节点作为主节点并记住其他节点?
-
定义Ivy中“最新集成”的行为
我很难理解latest.integration是如何工作的。 我有一个例子,没有给出输出中提到:http://ant.apache.org/ivy/history/latest-milestone/tutorial/defaultconf.html 也就是说,无论发布时间如何,本地解析器都优先于其他解析器。 我的常春藤.xml是这样的: 这里我声明我有一个nexus url存储库和一个对默认本地的
-
检查kubernetes集群中的存储容量
此外,根据kubernetes文档,节点的容量是不同的,pvc分配绑定到pv上,而pv就像节点一样是一个完全独立的集群资源。 在这种情况下,我需要检查什么存储来查找是否有任何可用空间,比如说一个x gb动态PVC?还有,我怎么检查?
-
MockMvc peform在集成测试中返回nullPointerException
我正在尝试为我的Spring项目运行集成测试,它是一个简单的get方法,用于从DB返回给定id的字符串输出。但是在Mockmvc中,我一直在Mockmvc上得到一个NullPointerException。在我的测试范围内执行。 以下是测试: 这里是控制器-输出控制器: 完全错误是:
-
集成测试中MockMvc和RestTemplate的区别
MockMvc和RestTemplate都用于与Spring和JUnit的集成测试。 问题是:它们之间有什么区别?我们什么时候应该选择它们? 以下是两个选项的示例:
-
最近在Mongo DB中添加的集合
在Mongo数据库中,如何获取最新添加/更新的集合? 我的应用程序会添加一个新集合,或者可能会更新现有集合。如何在数据库中检索最近更新的或新添加的集合? 我在互联网上查找的方法适用于一个集合,例如,这里显示的答案从mongodb集合获取最新记录
-
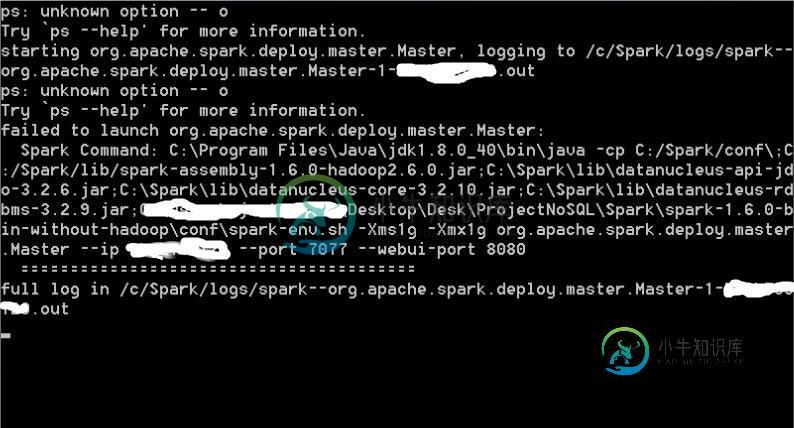 在Spark中手动启动群集失败
在Spark中手动启动群集失败来自log的信息(c:\spark\logs\spark--org.apache.spark.deploy.master.master-1-xxxxxx.out: Spark命令:C:\program files\java\jdk1.8.0_72\bin\java-cp C:\Spark/conf\;C:\spark/lib/spark-assembly-1.6.0-Hadoop2.6.0.jar
-
如何将jasper集成到jhipster项目中
我已经创建了这个控制器 报告consultas.jrxml位于folded resources上 当我运行te应用程序并运行endpoint时,我会出现以下错误: 你能帮我吗?
-
带有集中式Avro模式的Apache Kafka
我们使用Apache Kafka(不是confluent Kafka)0.10。我们想用Kafka设置AVRO模式。我有如下的avro模式。 序列化消息, 这正像预期的那样起作用。 但是,希望在主题级别设置一个Avro模式,这样,如果消息不符合Avro模式,主题将拒绝消息。 不管怎么说,我可以用阿帕奇Kafka0.10做到这一点。
-
使用zookeeper在集群中调度任务
我们使用Spring来运行调度任务,这在单节点上运行良好。我们希望在由N个节点组成的集群中运行这些计划任务,以便任务在一个时间点由一个节点执行。这是针对企业用例的,我们预计最多会有10到20个节点。 我研究了各种选择: 使用Quartz,这似乎是在集群中运行计划任务的流行选择。缺点:我想避免数据库依赖。 使用zoowatch,并且总是只在领导/主节点上运行计划的任务。缺点:任务执行负载没有分布 在
-
Cassandra如何在表中添加集群键?
卡桑德拉有一张桌子 如何在“排序”列中添加聚类键。不重新创建表
-
sybase ASE中密集_秩的替代方案
有没有办法重建Sybase ASE中的函数? 所以我需要每个元组(foo,bar)有一个唯一的数字。 表: 结果: 没有函数怎么做? 非常感谢!
-
Apache ActiveMQ Artemis集群中的消息顺序
我试图在Apache Artemis集群中实现消息排序。连接到集群的生产者/消费者实现了高可用性。因此,在某个时间点,将有两个相同应用程序的实例连接到主题或队列。到目前为止,我可以发现以下两种方法可用于在Red Hat AMQ/Artemis集群中实现排序: 消息组(根据文档,只有当集群中每个节点有一个使用者时才是可靠的) 独占队列(仅在单个节点上保留消息顺序)。 我完全理解使用集群和期望消息排序
-
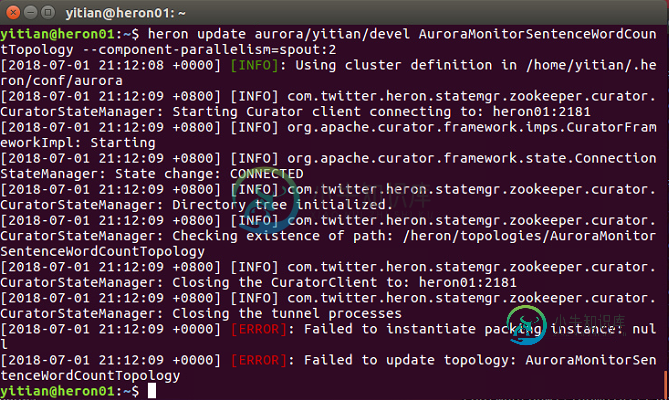 在Heron集群中更新拓扑失败
在Heron集群中更新拓扑失败这个拓扑运行正常,不知道是什么原因导致这个问题。
-
选择/排除pandas中的列集[副本]
我想根据列选择从现有数据帧创建视图或数据帧。 例如,我想从dataframe创建一个dataframe,该dataframe保存除两个列以外的所有列。我试着做了以下的操作,但没有奏效: