《水滴筹》专题
-
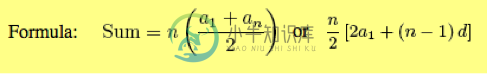 雨水收集的时间复杂性
雨水收集的时间复杂性从方法1开始,我一直在研究Leetcode问题的不同算法。如果阵列值是墙的高度,则需要计算总水域面积(列宽=1)。 第一种方法是找出每根立柱左右两侧最大墙高的最小高度,如果立柱高度小于最小值,则向给定立柱顶部加水。取最小值,因为这是收集的水能够达到的最高值。要计算每侧的最大值,需要对左侧和右侧进行n-1次遍历。 我用Python编写代码,但下面是根据Leetcode上给出的解决方案用C编写的代码。
-
水豚不与工厂女孩合作
我正在使用factory girl和capybara的minitest进行集成测试。当我不使用factory girl创建用户对象时,Capybara工作正常,如下所示: 但是一旦我尝试用工厂女孩创建一个用户,奇怪的事情就开始发生,比如访问方法和click_button方法停止工作。例如,这个测试似乎没有任何问题: 这是我的factories.rb: 下面是我得到的实际错误: 但是,如果我删除了u
-
无法单击水豚中的元素
问题:无法点击名为BT_SEARCH的元素 > click_button'Hae'返回:无法找到按钮"Hae"... click_link'Hae'返回:无法找到链接"Hae"... 查找(:xpath,“//输入[@name='BT\u SEARCH']”)。单击似乎找不到元素。 我无法修改源,也没有可用的id或类标签。此外,该页面使用ASP,我认为这是导致问题的原因。
-
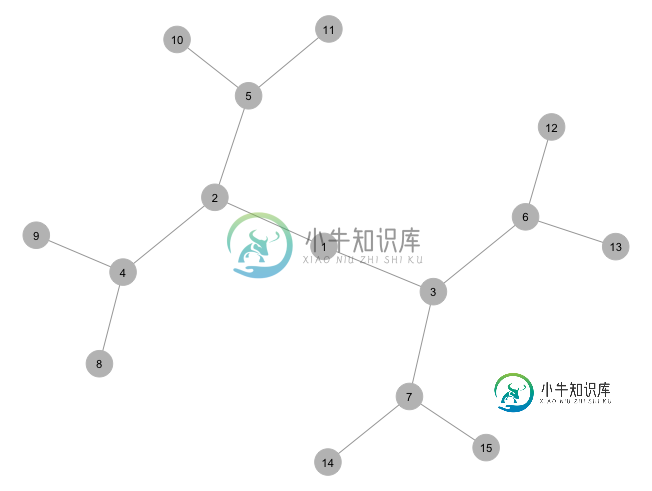 带igraph或ggnet2的水平树形图
带igraph或ggnet2的水平树形图我正在尝试使用 和 从维基百科中重现如下所示的概率树图。以下是我的开始, 它随机放置节点,以数字方式标记它们,并且边缘没有标签: 相反,我需要重新组织并标记边和节点,就像这样,只是将节点标签放在圆圈内:
-
iText向所选页面添加水印
我需要为每个有特定文本的页面添加水印,例如“删除过程”。 基于Bruno Lowagie的建议将水印直接添加到流中 迄今为止,PdfWatermark类具有: 如果我在自定义detectPages方法中将数字3添加到arrPages ArrayList中,则效果很好-它在第3页上显示所需的水印。 我遇到的问题是如何在文档中搜索文本字符串,我只能从PdfWriter writer或com访问文本字符
-
iText java-垂直和水平拆分表
我是一名iText java开发人员。我一直在处理大型表,现在我陷入了垂直拆分表的困境。 在iText In Action的第119页,尊敬的布鲁诺·洛瓦吉(我非常尊重这个家伙)解释了如何拆分一个大表,使列出现在两个不同的页面中。 我遵循了他的示例,当文档只有几行时,它工作得很好。 在我的例子中,我有100行,要求文档需要在几页中拆分100行,同时垂直拆分列。我按如下方式运行我的代码,但只显示前3
-
合法移动抽水马龙脚趾
所以我试图用Java编写一个tic tac toe游戏。大部分都完成了,但是,如果有人选择了一个已经被占用的空间,我不能归还无效的移动。 下面是我想弄清楚的代码。我认为既然空间是由数字0表示的(我的教授告诉我们的),有 在if语句中将阻止播放器重复该空格。
-
如何确定水槽拓扑方法?
我正在设置flume,但是不确定我们的用例应该使用什么样的拓扑。 我们基本上有两个web服务器,它们能够以每秒2000个条目的速度生成日志。每个条目的大小约为137字节。 目前我们已经使用rsyslog(写入tcp端口),php脚本将这些日志写入其中。我们在每个Web服务器上运行一个本地水槽代理,这些本地代理侦听tcp端口并将数据直接放入hdfs。 所以localhost:tcpport是“水槽源
-
执行水槽后Apache Flume卡住了
我需要帮助。 我已经下载了Apache Flume并安装在Hadoop之外,只是想尝试通过控制台进行netcat日志记录。我使用1.6.0版本。 这是我的confhttps://gist.github.com/ans-4175/297e2b4fc0a67d826b4b 这是我是如何开始的 但是仅在打印这些输出后就卡住了 对于简单的启动和安装有什么建议吗? 谢谢
-
水槽中的文件名和变量
现在我正在一个项目中工作,我们试图使用 flume 读取 tomcat 访问日志并在 Spark 中处理这些数据并以正确的格式将它们转储到数据库中。但问题是tomcat访问日志文件是每日滚动文件,文件名每天都会更改。像... 源代码部分的flume-conf文件如下 它在一个固定的文件名上运行tail命令(我使用了固定的文件名,只是为了测试)。如何在flume conf文件中将文件名作为参数传递?
-
水槽和HDFS集成,HDFS IO错误
我试图将FLUME与HDFS集成,我的FLUME配置文件是 我的核心站点文件是 当我尝试运行flume代理时,它正在启动,并且能够从nc命令中读取,但是在写入hdfs时,我得到了下面的异常。我尝试使用< code > Hadoop DFS admin-safe mode leave 在安全模式下启动,但仍然出现以下异常。 如果在任何属性文件中配置了错误,请告诉我,以便它可以工作。 另外,如果我为此
-
使用水槽读取IBM MQ数据
我想从IBM MQ中读取数据,并将其放入HDFs。 查看了 JMS 的水槽源,似乎它可以连接到 IBM MQ,但我不明白所需属性列表中的“destinationType”和“destinationName”是什么意思。有人可以解释一下吗? 还有,我应该如何配置我的水槽代理 flumeAgent1(在与MQ相同的机器上运行)读取MQ数据——flumeAgent2(在Hadoop集群上运行)写入Hdf
-
并行读取水槽线轴目录
由于我不允许在生产服务器上设置 Flume,因此我必须下载日志,将它们放入 Flume spoolDir 中,并有一个接收器可以从通道中使用并写入 Cassandra。一切正常。 然而,由于我在spolDir中有很多日志文件,并且当前设置一次只处理1个文件,这需要一段时间。我希望能够同时处理许多文件。我想到的一种方法是使用spolDir,但将文件分发到5-10个不同的目录中,并定义多个源/通道/接
-
如何使用RecycerView构建水平ListView
我需要在我的Android应用程序中实现一个水平的listview。我做了一些研究,发现如何在Android中创建一个水平的ListView?和Android中的水平ListView?。但是,这些问题是在RecycerView发布之前提出的。现在有没有更好的方法用RecycerView实现这一点?
-
AWS胶水执行器内存限制
我发现AWS Glue将Executor的实例设置为内存限制为5 Gb,有时在大数据集上它会因而失败。驱动程序实例。是否有任何选择来增加这个值?