《水滴筹》专题
-
StackExchange.Redis 流水线和多路复用
本文向大家介绍StackExchange.Redis 流水线和多路复用,包括了StackExchange.Redis 流水线和多路复用的使用技巧和注意事项,需要的朋友参考一下 示例
-
php给图片加文字水印
本文向大家介绍php给图片加文字水印,包括了php给图片加文字水印的使用技巧和注意事项,需要的朋友参考一下 注释非常的详细了,这里就不多废话了 以上所述就是本文的全部内容了,希望大家能够喜欢。
-
关闭管道中间的水流
当我执行这段代码时,它会在流管道中打开许多文件: 我得到一个例外: 问题是流。当完成对流的遍历时,count不关闭流。但我不明白为什么不应该,因为这是一个终端操作。对于其他终端操作,如和,也是如此<另一方面,代码>平面图关闭它所包含的流。 文档告诉我在必要时使用try with resources语句来关闭流。在我的例子中,我可以用以下内容替换计数行: 但这是嘈杂和丑陋的,在某些情况下,对于大型复
-
口水规则有什么问题?
我有很长时间使用JBOSS Drools的经验。我正在处理的当前项目使用Drools 4。 这是我在项目中的一条规则 想法是从没有关联目标对象的工作内存中收回此类项目。我正在使用工作内存中的这些对象对其进行测试: 项目{itemId=7305,itemTYpeId=Item\u TYPE\u A,targetId=-1023}目标{targetId=-1023} 在这种情况下,规则不应该开火,但它
-
水平和垂直滚动GridView Android
我正在使用GridView创建一个组件来创建像Excel这样的表。在这里,我最初创建了一个2x2网格,稍后当用户单击按钮时,会添加额外的行和列。 这是我添加新专栏的做法:- 这可以正常工作并添加额外的列。问题是当添加列时,以前的列会收缩以适应新列,从而使每次添加新列时列看起来更小。我想一次只在屏幕上显示2列,然后让用户水平向前滚动以查看更多列。现在网格只能垂直滚动。同样,我希望在添加新行时发生这种
-
 心率峰值的口水法则
心率峰值的口水法则我最近才开始流口水,我需要处理心率数据。我需要在drools fusion中创建一个规则,当心率数据中出现3个或更多峰值,超过过去一小时的平均值60或更多时,就会触发该规则。下面的图片是我喜欢在心率中发现的一个例子。 我的心率事件有以下字段: 我知道滑动时间窗口,但您只能使用基本函数,如min、max、avg等。有人能解释一下我如何创建这个规则吗?
-
在AWS胶水中追加负载
我需要对S3 bucket执行附加加载。 每天都有新的. gz文件被转储到S3位置,胶水爬虫读取数据并在数据曲库中更新它。 Scala AWS Glue作业运行并仅过滤当前日期的数据。 上面过滤的数据按照一些规则进行转换,并创建一个分区的动态数据帧(即年、月、日)级别。 现在,我需要将这个动态数据帧写入到S3 bucket中,其中包含所有前一天的分区。事实上,我只需要将一个分区写入S3存储桶。目前
-
PySpark/Aws胶水的性能问题
我有一个数据帧。我需要将每个记录转换为JSON,然后使用JSON负载调用API将数据插入postgress。我在数据框中有14000条记录,要调用api并获得响应,需要5个小时。有没有办法提高性能。下面是我的代码片段。 注意:我知道通过做"json_insert=df_insert.toJSON()。收集()"我正在失去数据帧的优势。有没有更好的方法来完成。
-
AWS胶水-是否使用履带
对于要在拼花格式的S3存储桶中的数据上运行的作业,有两种方法: > 使用 由于我的数据方案不会及时更改,使用爬虫程序是否有任何优势(性能方面或其他方面)?在这种情况下,我为什么需要爬虫?
-
MPAndroidChart自定义水平条形图
这是柱状图的图片。正如您所看到的,存在对齐问题,条形图没有与标签对齐,尤其是在中间部分。此外,我希望底部轴显示10的条形图,而不是1.2、1.4、1.6等,因为不会有任何小数,所以它没有用处。我还希望每个条的值在末尾显示为一个数字,以显示每个条的总计数。 图表https://imgur.com/gallery/ThHx1eJ图片 样式设置
-
如何对水壶进行测试
本文向大家介绍如何对水壶进行测试相关面试题,主要包含被问及如何对水壶进行测试时的应答技巧和注意事项,需要的朋友参考一下 参考回答: (同快手对水杯的测试) 功能 (1)水倒水壶容量的一半 (2)水倒规定的安全线 (4)水壶容量刻度与其他水壶一致 (5)盖子拧紧水倒不出来 (6)烫手验证 性能 (1)使用最大次数或时间 (2)掉地上不易损坏 (3)盖子拧到什么程度水倒不出来 (4)保温时间长 (5)
-
Apache Flink中带有TumblingWindow的水印
我试图了解Apache FLink中Windows和Watermark生成之间的依赖关系,我在下面的示例中出现错误: 这里的时间戳是一个长的,我们可以从Kafka源中检索到,应该是:a,4 C,8,其中C是类别,5是时间戳。 每当我发送事件时,数据流都会打印,但不会使用窗口打印这些事件(打印(“Windows”)。此外,如果我收到一个事件A,12,然后生成了一个水印(在10秒内),那么我有C,2,
-
Flink如何设置初始水印
我正在使用Flink 1.3.2和scala构建一个流媒体应用程序,我的Flink应用程序将监视一个文件夹,并将新文件流到管道中。文件中的每条记录都有一个相关的时间戳。我想使用此时间戳作为事件时间,并使用AssignerWithPeriodicWatermarks构建水印,我的水印生成器如下所示: 但是,由于我的文件夹中有一些旧数据,我不想处理它们。旧文件中记录的时间戳是
-
Node.js结合猫鼬和帆水线
我正在Node上做一个基于开源微服务的项目。js。 有些微服务非常薄,只与MongoDB交互,所以我没有在那里使用Sails,而是更喜欢直接使用Mongoose。因此,我为需要在mongo中持久化的每个对象实现了mongoose模式。 我还将在其他一些微服务中使用Sails.js,因此我必须为我想要持久化的对象实现Waterline类型的模式 问题是模式的重复,我觉得这没用。 我希望在所有服务中使
-
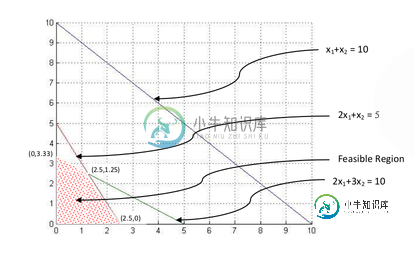 优化:种植小麦和水稻
优化:种植小麦和水稻这是问题陈述 一位印度农民有一片农田,比如说1平方公里长,他想种小麦或水稻,或者两者兼有。农民有有限的F公斤肥料和P公斤杀虫剂。 每平方公里的小麦需要F1公斤化肥和P1公斤杀虫剂。每平方公里的水稻种植需要F2公斤化肥和P2公斤杀虫剂。假设S1是出售从一平方公里收获的小麦获得的价格,S2是出售从一平方公里收获的水稻获得的价格。 你必须通过选择种植小麦和/或水稻的地区来找到农民可以获得的最大总利润。