《吐槽面试》专题
-
阿帕奇水槽自动关闭
我正在使用 flume 1.8.0,它会自动关闭,任何人都可以帮助我。 在 JAVA 8 上运行 JAVA_OPTS=“-服务器 -Xms4g -Xmx4g” 配置在水槽中 使用以下命令启动 flume ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-conf-postgresql.properties --name dfm-to
-
将数据从syslog导入水槽
我试图设置一个flume代理来从syslog服务器获取数据。基本上,我在所谓的服务器(server1)上设置了一个syslog服务器来接收syslog事件,然后将所有消息转发到安装了flume代理的不同服务器(server2 ),最后所有数据将被汇聚到kafka集群。 水槽配置如下。 但是,不知何故,logsys并没有注入水槽药剂。 征求您的意见。
-
关于flink溪流水槽至hdfs
我正在编写一个flink代码,其中我正在从本地系统读取一个文件,并使用“writeUsingOutputFormat”将其写入数据库。 现在我的要求是写入hdfs而不是数据库。 你能帮我在Flink怎么办吗。 注意:hdfs已启动并在本地计算机上运行。
-
1.11.6 使用插槽分发内容
在使用组件时,我们常常要像这样组合它们: <app> <app-header></app-header> <app-footer></app-footer> </app> 注意两点: <app>组件不知道它会收到什么内容。这是由使用<app>的父组件决定的。 <app>组件很可能有它自己的模板。 为了让组件可以组合,我们需要一种方式来混合父组件的内容与子组件自己的模板。这个过程被称为内
-
基金会 - 厨房水槽(Kitchen Sink)
描述 (Description) 它包括可以顺利使用Web应用程序的Foundation元素。 下表列出了一些Foundation组件 - Sr.No. 组件和说明 1 Accordion Accordions包含垂直选项卡,用于在网站上展开和折叠大量数据。 2 手风琴菜单 它显示带有手风琴效果的可折叠菜单。 3 Badge 徽章类似于标签,用于突出显示重要注释和消息等信息。 4 Breadcru
-
 工作两年、985本社招跳槽看go机会的同学的面试辅导
工作两年、985本社招跳槽看go机会的同学的面试辅导大家好,今天来和各位同学一起复盘一个工作两年、985本看社招跳槽看go机会的同学的面试辅导过程。 2年的工作经验我觉得已经足够成为一个资深工程师了,意味着可以独立地负责从端到端的一个业务、熟练掌握工作流中的各项技术。但是今天帮一个985本两年工作经历的go开发同学做了社招跳槽的模拟面试。不谈工作水平,他的面试水平确实比不过今年的校招同学。 和很多工作了多年的程序员一样,我觉得他犯了一个很重要的错误
-
Jmeter吞吐量与线程图问题
我想通过从CSV文件向服务器发送100个请求来测试10个线程。我想每个线程按顺序发射100个请求,同时允许并行请求。我有我的主要采样器和子采样器的子组件和另一个采样器,我想比较我的结果。这种配置通常会产生7个采样器。问题是,当我尝试绘制吞吐量与线程之间的关系图时,在1个用户中,结果在y轴上显示了100多个事务/秒的值。同样的事情发生在“显示结果表”侦听器(即,对于1个用户,它显示700个样本)如何
-
Flink流-延迟和吞吐量检测
我正在尝试运行Flink流媒体作业。我想确定流处理的延迟和吞吐量。我已启动Kafka代理服务器,并收到来自Kafka的传入消息。如何计算每秒的邮件数(吞吐量)?(如rdd.count。是否有类似的方法来获取传入消息的计数) (完整的场景:我已经通过生产者发送了消息作为Json对象。我在Json对象中添加了一些信息,如名称为字符串和System.currentTimeMills。在流式传输期间,我如
-
JMeter如何确认最大吞吐量?
这些天我试图使用JMeter做负载测试。有一个非常令人困惑的点我不明白:分布式环境: 1。运行JMeter Server 2的3台8 CPU 16G服务器。4 CPU 8G服务器运行JMeter 3.这些服务器在同一个子网上。 线程组设置:线程数:2000爬升:0循环:10吞吐量为3000/s 另一个线程组:线程数:2000提升:1循环:10吞吐量为5000/s 另一个线程组:线程数:2000爬升
-
intel Intrinsic中的延迟与吞吐量
总的来说,我认为我对延迟和吞吐量之间的区别有很好的理解。但是,对于Intel Intrinsics,延迟对指令吞吐量的影响我还不清楚,尤其是在顺序(或几乎顺序)使用多个内在调用时。 例如,让我们考虑: 这有11个延迟,在Haswell处理器上的吞吐量为7。如果我在循环中运行这条指令,我会在11个循环后获得每个循环的连续输出吗?由于这需要一次运行11条指令,并且由于我的吞吐量为7,我是否用完了“执行
-
每次打开Androidapp都显示吐司
舱单:
-
单分区的CosmosDB吞吐量限制?
在幕后,Azure Cosmos DB提供了服务T请求/S所需的分区。如果T高于每个分区的最大吞吐量T,那么Azure Cosmos DB提供N=T/T分区。
-
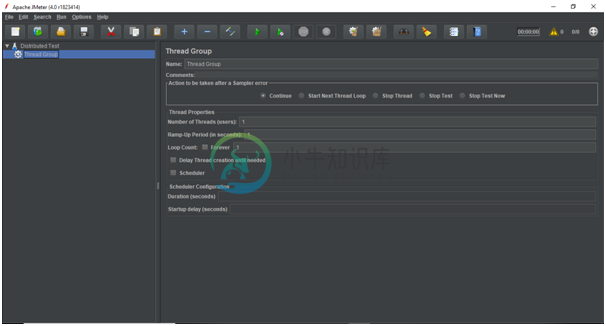 JMeter分布式负载测试(吞吐量控制器)
JMeter分布式负载测试(吞吐量控制器)主要内容:创建JMeter测试计划,添加采样器,添加监听器,保存并执行测试计划,验证输出,添加吞吐量控制器,验证输出在本节中,我们将学习如何使用吞吐量控制器在JMeter中创建分布式负载测试计划。 出于测试目的,我们将在我们网站 www.yiibai.com 的URL下的某些网页上创建分布式负载。这些网页包括: 主页: www.yiibai.com 第1页(Java): www.yiibai.com/cplusplus/ 第2页(C语言): www.yiibai.com/cprogramming
-
Jmeter远程测试挂起,吞吐量显著下降
我已经在Google云中设置了Jmeter 4.0,其中一个主服务器与12个从服务器对话以生成负载。对于非常少的线程,测试就像一个魔咒,在最后生成报告。 然而,当我将每个从属主机的线程数增加到200以上时,测试似乎挂起了,我在服务器端没有看到很多请求。在上升期之后,我看不到持续超过5分钟的活动,它在那之后慢慢变小。我可以用数据库计数来验证——上升期结束后,比率下降了很多。在30分钟测试结束时,只有
-
STD::功能和信号/插槽系统
我的测试类: 所以,我这样使用我的类: 我在signal.cpp中得到一个警告:候选函数不可行:第一个参数没有从'void(*)(int)'到'int'的已知转换; 在此代码中: 我该怎么解决?如果我想给我的“emit”方法一个对象或多个参数,我可以做什么? 谢了!