《巨人网络》专题
-
使用VTD-XML解析巨大的XML文件
为了在巨大的xml文件中执行XPATH查询,我阅读了许多喜欢VTD-xml的文章,因此我复制了这些文章中的代码: 但当我运行它时没有结果,所以这意味着XML文件没有映射到内存中。。。我的问题是如何在VTD-xml中强制映射xml文件?
-
在巨大的事件流中发现差距?
问题内容: 我在PostgreSQL数据库中有大约一百万个具有以下格式的事件: 大约有50,000个唯一流。 我需要找到所有两个事件之间的时间间隔都超过特定时间段的所有事件。换句话说,我需要找到在特定时间段内没有事件的事件对。 例如: 在这种情况下,我想找到对(f,g),因为这些是紧挨着缺口的事件。 我不在乎查询是否慢,即在一百万条记录上花费一个小时左右就可以了。但是,数据集将保持增长,因此,如果
-
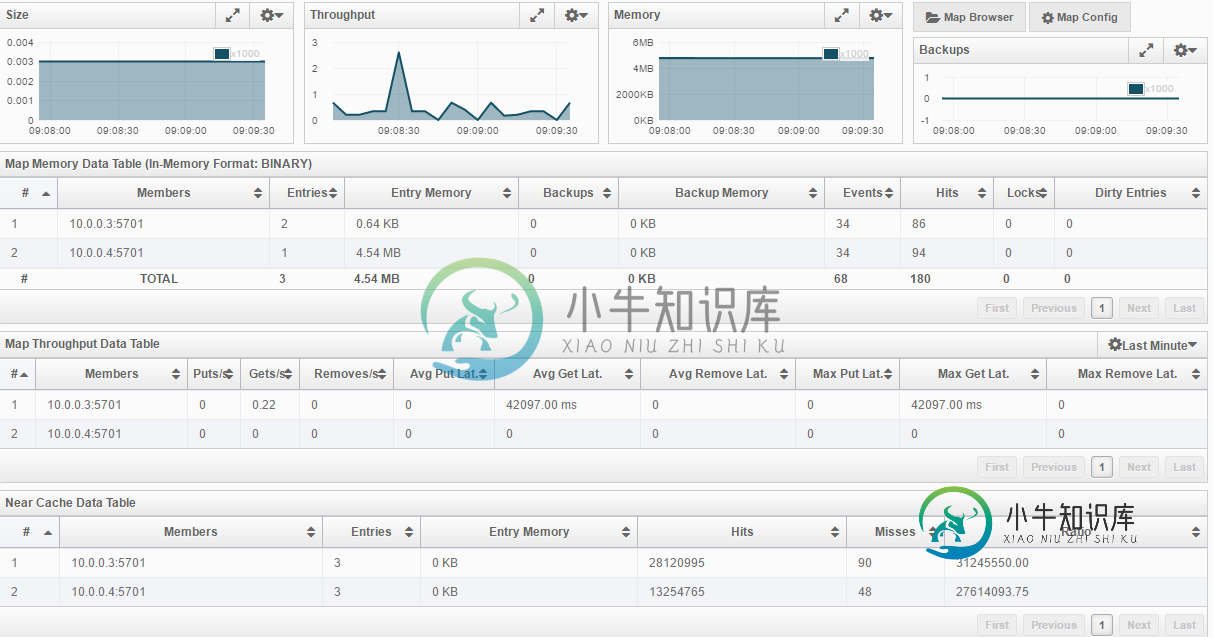 Hazelcast附近缓存-巨大的获得延迟
Hazelcast附近缓存-巨大的获得延迟我的地图中存储了3个对象——每个都有几个MB。它们不会改变,所以在节点本地缓存它们是有意义的。这就是我在意识到平均获取延迟很大之前所做的,这大大减慢了我的计算速度。请看hazelcast控制台: 这让我想知道它是从哪里来的。我认为最初发生的是90和48次失误吗?这些计算是并行运行的,所以我认为它们都可以在条目被缓存之前发出一个reguest来获取,因此所有这些都不会从近缓存中受益。那么它是某种预加
-
用java读取巨大的Excel文件(500K行)
我正在尝试读取一个大的XLSX文件。Excel文件大约有500k行,我需要读col 2。 它一直打印到第39723行,然后抛出以下异常 main.java:484=If(!cell.getStringCellValue().ToString().trim().IsEmpty())如果我删除该行并只打印行号,就可以正常工作。我需要帮助如何获得col2的字符串值。
-
找人
热门用户 最新用户 推荐用户(按标签及后台推荐) 搜索用户 后台推荐用户 get /user/recommends 输入 每次最多查询200个推荐 Response Status: 200 OK [ { "id": 2, "name": "wayne", "bio": null, "sex": 0, "location": null, "cr
-
AWS API网关自定义授权人授权配置异常
对于Kinesis流,我使用AWSAPI网关创建了一个代理API。我为代理添加了一个使用python Lambda的自定义授权器。在发布lambda函数和部署API之后,我能够使用网关测试功能成功地测试API。我可以在cloudwatch中看到日志,其中包含来自自定义auth lambda函数的详细打印。成功身份验证后,API网关将记录推送到我的Kinesis流 但是当我从Chrome Postm
-
从0到1搭建个人网站 八-django 中集成 ckeditor
安装ckeditor django集成ckeditor已经有人帮我们做了,我们直接参考https://github.com/django-ckeditor/django-ckeditor安装,方法如下: pip install django-ckeditor 然后修改shareditor/settings.py中的INSTALLED_APPS,添加如下项: ? ? 'ckeditor', ?
-
从0到1搭建个人网站 六-路由的使用
指定标签的文章列表页 上一节完成的首页部分每个标签有对应的一块展示区域,我们希望点击标题可以进入到这个标签的文章列表页。我们来定义如下路由规则,修改shareditor/urls.py,为urlpatterns增加如下一行: url(r'^bloglistbytag', views.blog_list_by_tag, name='blog_list_by_tag') 这个意思是说对于url路径为
-
从0到1搭建个人网站 三-数据库与 model
创建和链接数据库 首先,我们需要有一个mysql的服务,你可以选择自己安装启动一个mysql服务,我选择了阿里云的云数据库RDS(和本地搭建没有区别,收费但不贵),我创建了一个数据库名叫db_shareditor(如果本地搭建的mysql,执行命令是create database db_shareditor) 下面我们配置我们的网站工程来连接这个数据库,修改shareditor/settings.
-
 网易三面 | 后端开发(实习) | 人工智能部门
网易三面 | 后端开发(实习) | 人工智能部门之前分享了网易的一面二面面经,本来以为凉了,没想到在回复牛友评论的时候收到了三面的通知(https://www.nowcoder.com/discuss/487543831529857024?sourceSSR=users)。今天来分享一下三面的面经~ 谈谈JVM虚拟机 JVM虚拟机是有哪些部分组成的 JVM虚拟机的内存结构 方法区存放哪些信息 常量存放在哪个区域 一般用什么方法来创建一个线程池
-
Docker主机网络与网桥网络
本文向大家介绍Docker主机网络与网桥网络,包括了Docker主机网络与网桥网络的使用技巧和注意事项,需要的朋友参考一下 可用于Docker网络的单主机网络有两种类型:“主机”和“桥”网络。单主机网络意味着它们的影响对于每个单独的主机都是局部的。 在主机网络的情况下,特定的Docker容器可以直接使用主机的网络来发送和接收数据包。对于网桥网络,它需要端口映射才能进行通信。 为了更好地理解它们,让
-
电报机器人:来自网络钩子的错误响应:404错误请求
我在赫洛库上部署了我的电报机器人。Bot曾经工作正常,但在某些时候,它只是在接收命令时停止发送消息。以下是获取网络钩子信息的答案: {"ok":true,"结果":{"url":"https://telegram-rainbow-bot.herokuapp.com:443/api/message/update","has_custom_certificate":false,"pending_upd
-
你觉得自己是互联网达人吗?为什么?请结合具体数据和案例来展示你是一个互联网达人。
本文向大家介绍你觉得自己是互联网达人吗?为什么?请结合具体数据和案例来展示你是一个互联网达人。相关面试题,主要包含被问及你觉得自己是互联网达人吗?为什么?请结合具体数据和案例来展示你是一个互联网达人。时的应答技巧和注意事项,需要的朋友参考一下 工作上:平均一天大约40%时间都在用电脑查资料,写各种文档,团队协作,写专业作业,当然还有求职实习当中。 生活上:90%的时间都会花在聊天交流上,外卖支付中
-
使用StAX和XPath读取巨大的XML文件
问题内容: 输入文件包含数千个XML格式的事务,大小约为10GB。要求是根据用户输入选择每个事务XML,并将其发送到处理系统。 文件的样本内容 希望(技术)用户提供输入标签名称,例如。 我们希望提供更通用的解决方案。文件内容可能会有所不同,用户可以使用XPath表达式(例如“ ”)来选择单个事务。 这里我们需要考虑的技术问题很少 该文件可以位于共享位置或FTP 由于文件很大,因此我们无法在JVM中
-
如何有效地打开巨大的Excel文件
问题内容: 我有一个150MB的单张excel文件,使用以下命令在功能非常强大的计算机上打开大约需要7分钟: 有什么办法可以更快地打开excel文件吗?我愿意接受甚至非常古怪的建议(例如hadoop,spark,c,java等)。理想情况下,如果这不是白日梦,我正在寻找一种在30秒内打开文件的方法。另外,上面的示例使用的是python,但不一定必须是python。 注意:这是来自客户端的Excel