
Hazelcast附近缓存-巨大的获得延迟

我的地图中存储了3个对象——每个都有几个MB。它们不会改变,所以在节点本地缓存它们是有意义的。这就是我在意识到平均获取延迟很大之前所做的,这大大减慢了我的计算速度。请看hazelcast控制台:
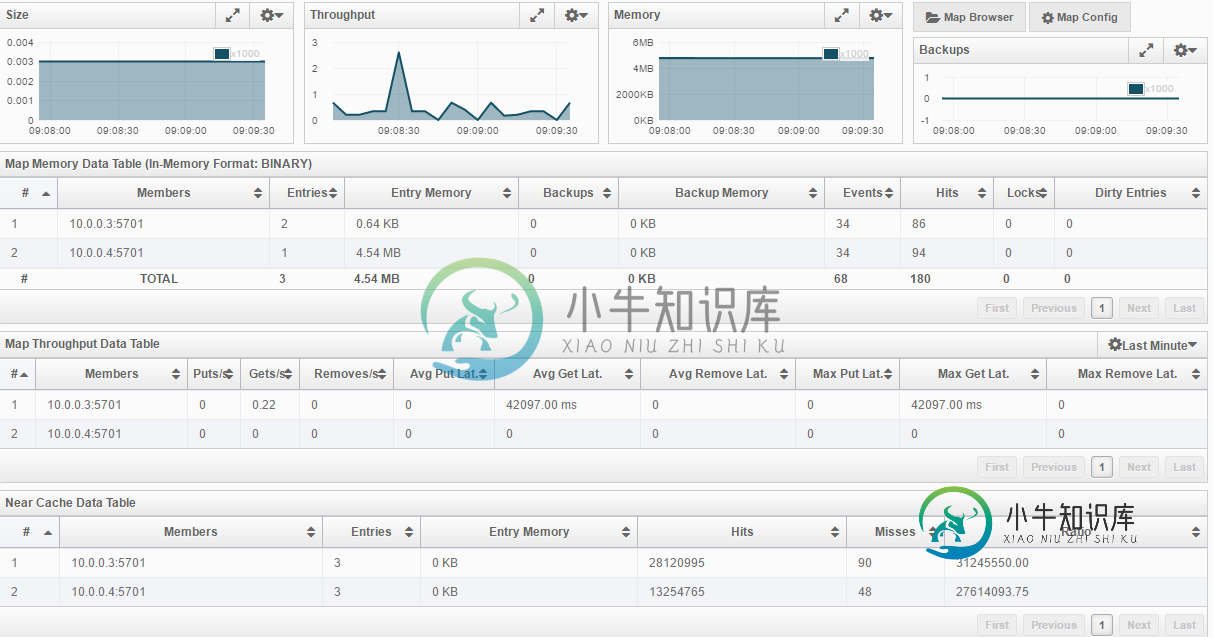
这让我想知道它是从哪里来的。我认为最初发生的是90和48次失误吗?这些计算是并行运行的,所以我认为它们都可以在条目被缓存之前发出一个reguest来获取,因此所有这些都不会从近缓存中受益。那么它是某种预加载方法,以便我在触发所有这些并行任务之前运行它吗?顺便问一下,为什么即使在接近缓存的数据表中有条目,条目内存也为0?
这是我的地图配置:
<map name="commons">
<in-memory-format>BINARY</in-memory-format>
<backup-count>0</backup-count>
<async-backup-count>0</async-backup-count>
<eviction-policy>NONE</eviction-policy>
<near-cache>
<in-memory-format>OBJECT</in-memory-format>
<max-size>0</max-size>
<time-to-live-seconds>0</time-to-live-seconds>
<max-idle-seconds>0</max-idle-seconds>
<eviction-policy>NONE</eviction-policy>
<invalidate-on-change>true</invalidate-on-change>
<cache-local-entries>true</cache-local-entries>
</near-cache>
</map>
实际的问题是,为什么在近缓存中会有这么多未命中,那么巨大的平均获取延迟是从哪里来的?
共有1个答案

管理中心显示的延迟是请求到达服务器后的延迟。如果你有一个近缓存,并且你点击了近缓存,它将不会显示在Man.Center上。我怀疑您不会注意到应用程序的高延迟。我看到已经发生了34起事件。我想这个条目已经更新了。更新条目时,它将从近缓存中逐出。随后的读取将命中服务器。
-
大家好 我尝试在SpringBoot应用程序中使用Hazelcast作为本地缓存,如下教程:https://hazelcast.com/blog/non-stop-client-with-near-cache/ 黑泽尔铸造分级版: 在我的版本中,我没有看到为连接到集群设置最大超时的方法(setClusterConnectTimeoutMillis()): ..如果没有它,它就会掉下来 com.ha
-
我的客户端代码看起来是这样的(Cache只是一个没有属性的可序列化类): 我现在的问题是:使用这段代码,我得到了一个ClassNotFoundError,它试图将东西放到复制的映射或常规映射中,但在专用的Hazelcast服务器(成员)中,而不是在客户端。 每当我从客户端配置中删除近缓存配置时,所有的工作都非常完美,当然,除了我没有近缓存。 我错过了什么?
-
问题内容: 我正在测试Django + Celery,您好是世界示例。使用RabbitMQcelery可以正常工作,但是当我切换到Redis经纪人/结果时,我得到以下信息: settings.py task.py 上面的测试中有什么问题吗? 问题答案: 我发现解决方案是源代码:http : //docs.celeryproject.org/en/latest/_modules/celery/res
-
我正在寻找集成Hazelcast到我的应用程序... 我的要求是将所有数据加载到缓存并从缓存中提取。。 我有两个选择。 1) Hazelcast IMap 2)因为我使用的是Spring启动,所以我可以使用(@Cacheable/@CacheEvict)。 我能得到一些建议吗... 提前谢谢你。。
-
问题内容: 我怀疑这与字节序有关,但我不确定如何解决。我有一个C ++客户端,它告诉Java服务器它将要发送多少字节,而Java服务器仅在输入流上调用readInt()。然后,服务器继续读取其余数据。 目前,如果C ++服务器调用: 然后对应的Java端是: Bytes lBytesSent往往是一个巨大的值,然后在创建数组时就会抛出异常(不足为奇) 只需使用以下命令打开C ++套接字: 而Jav
-
我已经将Hazelcast缓存配置为Spring Boot应用程序中的分布式缓存。 我想要为同一实例提供本地缓存,其中很少缓存不应共享。 如何在应用中一起做本地和分布式缓存?