
Hazelcast Jet 是一个分布式计算平台,专为高性能流处理和快速批处理而构建。它在内存数据网格(IMDG)中嵌入Hazelcast,以提供轻量级的处理器包和可扩展的内存存储。
特性:
-
低延迟和分布式的通用数据处理框架,具有高吞吐量
-
高并行和分布式的数据流和批处理
-
分布式 java.util.stream API 支持 Hazelcast 数据结构,如 IMap 和 IList
-
连接器允许从 Apache Kafka, HDFS, Hazelcast IMDG, sockets 和本地数据文件(如日志或 CSV)高速获取数据
-
自定义连接器的 API
-
针对内部部署和云部署的动态节点发现
-
通过 Docker, Apache jclouds, Amazon Web Services, Microsoft Azure, Consul, Heroku, Kubernetes, Pivotal Cloud Foundry 和 Apache ZooKeeper 进行虚拟化支持和资源管理
架构
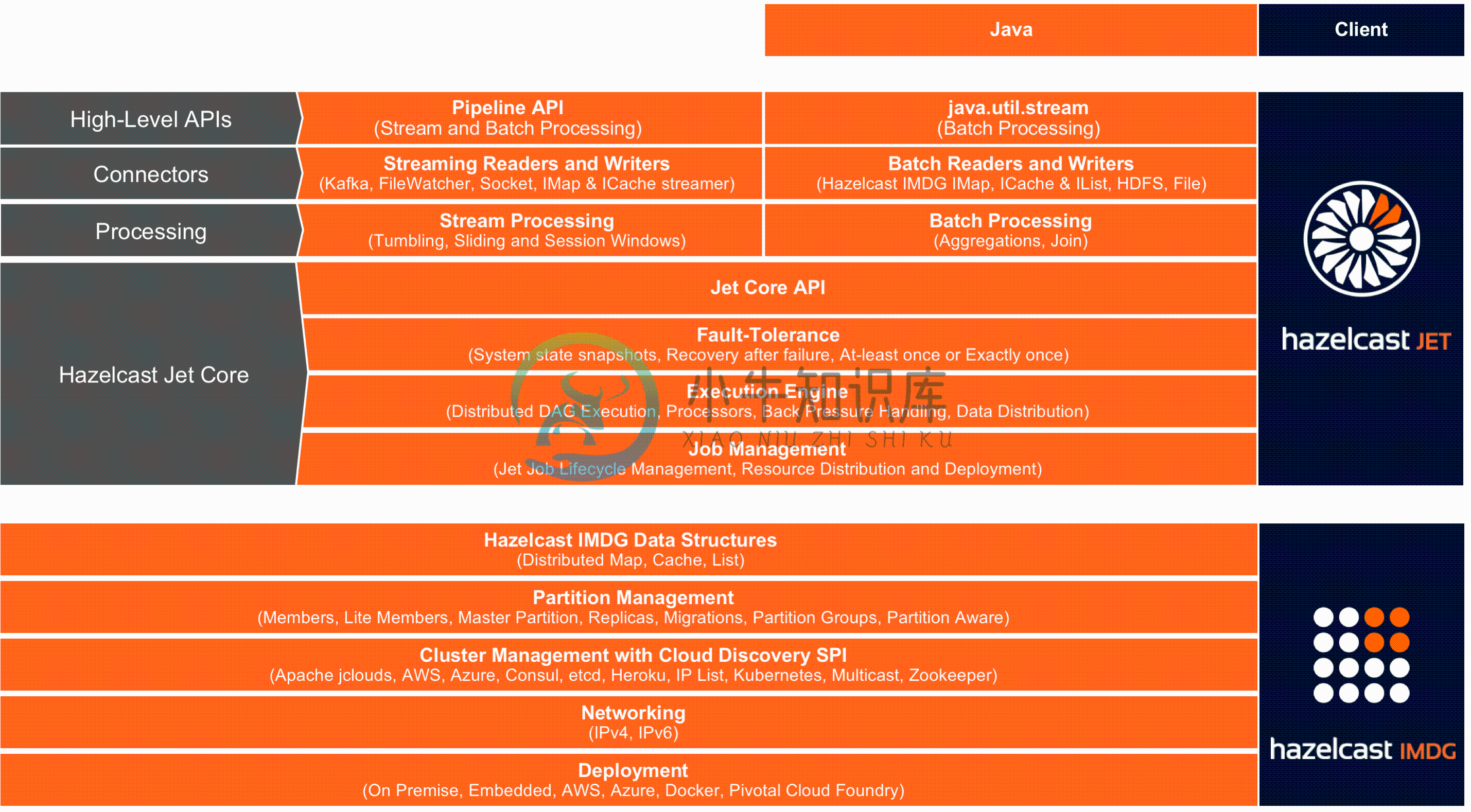
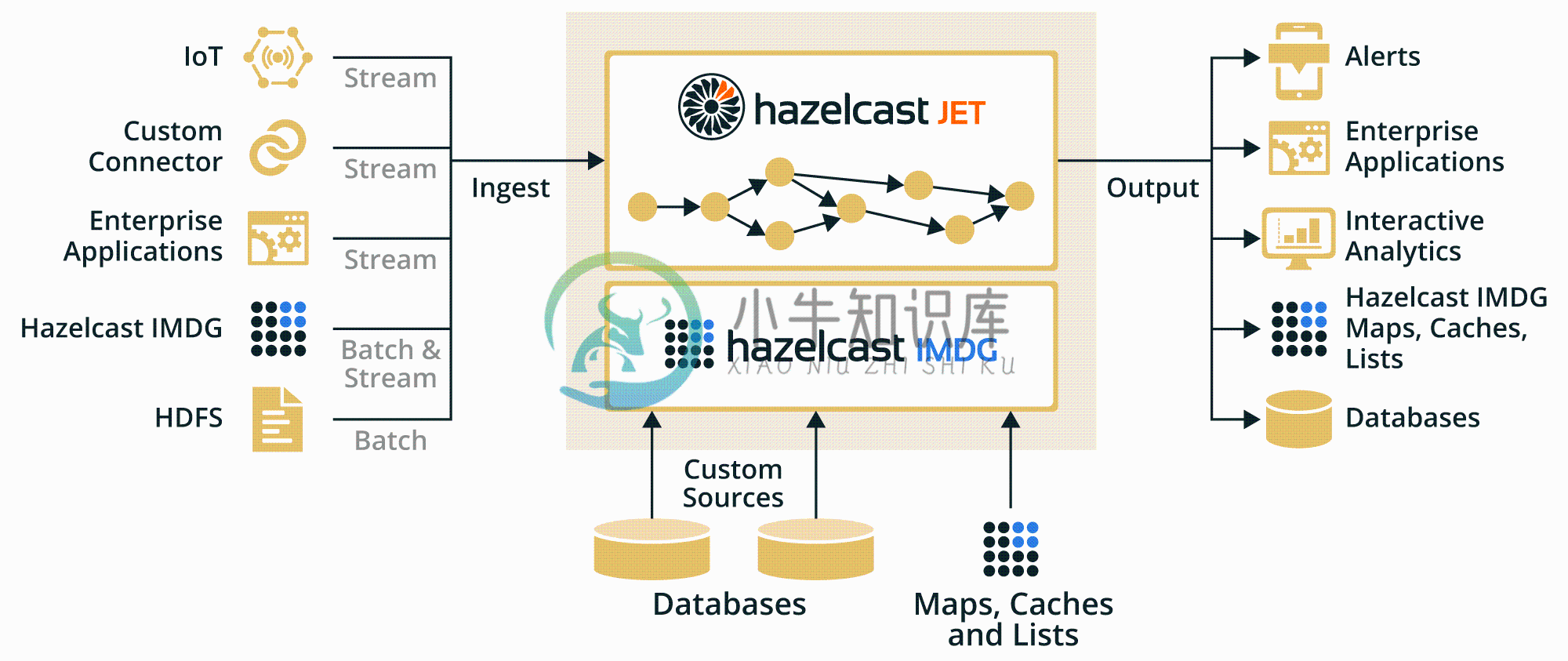
-
前言 com.hazelcast.jet.core.processor.Processors(简称P) 这个类实现了核心的P,这里的P对应的是Jet引擎内部的DAG图的节点。 简单来说,这些P处理的是聚合(SUM/AVG/MAX/MIN),更复杂的情况是,可能是在任意的Key上做聚合,甚至是基于事件发生的时间窗上的聚合。因此Jet开发了两类P节点: 单阶段P 两阶段P 注意:从下面接口文档可以看出
-
前言 Jet没有依赖ZK等外部工具软件来实现容错,它内部实现了Chandy-Lamport 分布式snapshots。一旦一个计算节点fail了,Jet会在另外一个计算节点重启Job,从snapshot中恢复处理中的状态,然后从断点恢复。 一、Jet分布式计算一致性 当配置Job的时候,可以设置为Exactly-Once或者At-Least-Once,这个时候Jet会用IMap来做snapshot
-
Hazelcase 简介 以下内容, 原文出自: http://www.open-open.com/open253825.htm Hazelcast是一个高度可扩展的数据分发和集群平台。特性包括: 提供java.util.{Queue, Set, List, Map}分布式实现。 提供java.util.concurrency.locks.Lock分布式实现。 提供jav
-
Hazelcast是一个高度可扩展的数据分发和集群平台。特性包括: 提供java.util.{Queue, Set, List, Map}分布式实现。 提供java.util.concurrency.locks.Lock分布式实现。 提供java.util.concurrent.ExecutorService分布式实现。 提供用于一对多关系的分布式MultiMap。 提供用于发布/订阅的分布式To
-
最近在总结hazelcast的资料,顺便把集群的也总结下. Hazelcast自称"分布式数据网格”,那他最基本、最重要的功能就是时时刻刻都在多台服务器之间工作,这样必须有网络环境对其分布式功能提供支持。Hazelcast在网络环境中工作分为2个阶段:首先是组网阶段,随后是数据传输阶段。 组网是指每个Hazelcast节点启动时,都会搜寻是否有Hazelcast节点可以连接,组网过程支持多种协议。
-
Hazelcast 概念 Hazelcast 是一个开源的可嵌入式数据网格(社区版免费,企业版收费)。你可以把它看做是内存数据库,不过它与 Redis 等内存数据库又有些不同。项目地址:http://hazelcast.org/ Hazelcast 使得 Java 程序员更容易开发分布式计算系统,提供了很多 Java 接口的分布式实现,如:Map, Queue, Topic, Execut
-
简介 开源中国的简介: Hazelcast是一个高度可扩展的数据分发和集群平台。特性包括: 提供java.util.{Queue, Set, List, Map}分布式实现。 提供java.util.concurrency.locks.Lock分布式实现。 提供java.util.concurrent.ExecutorService分布式实现。 提供用于一对多关系的分布式MultiMap。 提供用
-
Hazelcast is a clustering and highly scalable data distribution platform for Java. Hazelcast helps architects and developers to easily design and develop faster, highly scalable and reliable applicati
-
Hazelcast主要以开源缓存和内存数据网格技术(通常称为Hazelcast IMDG,或者只是Hazelcast)为人所熟知。然而过去的两年中,他们一直致力于一个新的、重要的开源项目Hazelcast Jet,近日,他们宣布了这项新技术的一个主要版本。\u0026#xD;\n\u0026#xD;\n InfoQ与Hazelcast首席执行官Greg Luck和Jet核心团队工程师Marko T
-
一般的应用正式环境中都不止一台服务器(也就是说是集群的),那么如果只是简单的将数据预加载到内存,那么就会有数据不同步的现象。 (更新了其中一台JVM,另一台JVM并不会收到通知从而保持数据同步)。 这时候就需要用到cache server了。 目前流行的cache server有很多种,像redis,Hazelcast,ehcache,memcache等。 如果你在寻找一个基于内存的、可扩展
-
我想分散加工大批量。这个想法是使用Spring Batch在云中激发一堆AMQP消费者,然后加载廉价的任务(如项目ID)并将它们提交给AMQP交换。结果的书写将由消费者自己完成。 null
-
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
我们使用分布式查询来搜索带有键的部分值的条目。 我们的基础设施目前只能提供微服务的一个实例。映射是用数据库中的MapStore实现持久化的。 如果微服务关闭,我们会丢失内存中的所有数据,分布式查询也不会返回任何结果。使用loadAllKeys()等通过MapStore初始化内存中的数据不是一种方法,因为我们在数据库中将有大量条目需要加载。
-
我正在尝试测试我的分布式锁实现,但是我仍然没有找到使它工作的方法。我用两个简单的方法部署了一个REST服务,如下所示: distributedService对象实现getDistributedLock()方法: 在黑兹尔卡斯特。xml文件,我启用了TCP-IP连接,并禁用了其他所有功能: 我在这两台机器上部署了应用程序,IP地址与。xml文件(192.168.0.01和192.168.0.02),
-
我计划在应用程序中使用Hazelcast作为分布式缓存。我们必须在缓存中加载大约300个条目的静态数据。我们计划只使用嵌入式缓存拓扑。任何数据库都不会备份缓存。因此,数据的唯一来源是该缓存。因此,我想知道是否可以通过某种方式手动加载缓存中的数据,而不是通过Hazelcast管理中心的编程方式? 此外,当我在不同的数据中心部署应用程序时,嵌入式拓扑是否适用于分布式缓存?
-
我在Cloudera CDH5.3集群上运行Spark,使用YARN作为资源管理器。我正在用Python(PySpark)开发Spark应用程序。 我正在运行一个提交命令,如下所示: 如何确保作业在集群中并行运行?
-
本文向大家介绍基于python爬虫数据处理(详解),包括了基于python爬虫数据处理(详解)的使用技巧和注意事项,需要的朋友参考一下 一、首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1、设置变量 set @变量名=值 1.2 、length()函数 char_length()函数区别 1.3、 replace(
-
问题内容: 如果创建Oracle dblink,则无法直接访问目标表中的LOB列。 例如,使用以下命令创建一个dblink: 之后,您可以执行以下操作: 除非该列是LOB,否则您将收到错误: 这是有据可查的限制。 同一页上建议您将值提取到本地表中,但这有点…杂乱无章: 还有其他想法吗? 问题答案: 是的,这很混乱,不过我想不出办法避免这种情况。 您可以通过将临时表创建放入存储过程中(并使用“立即执