《今日头条字节跳动》专题
-
 字节飞书 后端开发 日常实习 25届 面经
字节飞书 后端开发 日常实习 25届 面经简历信息 ps:因为几乎只关注基础和代码实现,只给出技能特长。 TimeLine --12/11投简历--12/12约面试--12/18一面--待补充-- 一面 1h #字节##25届找寒假JAVA实习#
-
 字节火山引擎-后端开发-日常实习面经
字节火山引擎-后端开发-日常实习面经面试和算法题都是在飞书平台上进行,面试官有事晚到了几分钟,但是不影响 1. 自我介绍 2. 三次握手 3. HTTP和HTTPS的区别 4. DNS的解析过程 5. 分库分表是如何做的 6. 布隆过滤器原理 7. ThreadLocal原理 8. 堆和栈的区别 9. 非常大的文件,只有1G内存,如何统计大文件中元素的出现次数 算法:字符串匹配(以前没写过,来回改几次才通过) 整体八股有四十分钟,算
-
如果InputStream以“#”开头,如何使其跳过一行?
我正在写一个程序,必须解码二维码。代码在内部表示为二维布尔列表。代码通常被读取为包含1和0的文本文件,其中1表示矩阵中的暗模块(true),0表示亮模块(false)。 我必须实现一个方法,它将接受一个输入流,然后必须返回一个QR码。我必须读. txt,它包含1、0和以“#”开头的注释行。我需要使该方法忽略这些注释行,但我不知道如何做到这一点。 以下是代码的一些相关部分: 首先QR码构造函数(构造
-
如何在hadoop mapreduce中跳过文件头的读取
我正在使用java学习hadoop mapreduce,我有一个示例文件,数据如下所示,我如何跳过处理这个文件中的标题行…因为当我看到映射器输入时,它也在考虑标题… 滚动noschool namenameageGenderclasssubjectmarks
-
从http标头响应获取日期
问题内容: 好的,因此我可以使用访问HTTP ajax响应标头 但似乎没有日期,尽管它在那里: 而代码只显示了这一点: 这是ajax调用: 有没有办法可以在响应头中获取日期? 问题答案: 这有帮助:
-
swagger日期字段与日期-时间字段
我有一个java实体类TimeEntry.java它的属性之一是Date,它看起来像这样。 对于该字段,在swagger UI模型模式上,字段日期显示为“日期”:“2016-01-08T22:34:22.337Z”,但我需要该字段作为“日期”:“2016-01-08”。 我尝试了以下方法: 请帮帮忙。
-
Tomcat响应标头字段
问题内容: 有没有一种方法不显示http响应的头文件。 例如 : 显示字段 服务器 时,它可能是一个不好的实践。我以为tomcat 有一种 生产模式 ,可以隐藏一些标题字段。 谢谢。 问题答案: 在server.xml文件中,添加到连接器以更改标头名称。我相信只是会删除标题或发送空白,但我并不乐观。 因此,您的连接器将如下所示: 请注意,在开发机器上进行更改时遇到问题。我认为这是Netbeans寻
-
φ4 四通十字接头
概述 φ4直通式节流阀是一种直通式流量控制阀,用于流量的调节和控制,手动旋钮控制调节,可完全锁定关闭。 尺寸图纸 搭建案例
-
日期的字符串日期
问题内容: 如何将字符串日期格式转换为日期,我的日期字符串格式为 接下来,我没有运气尝试。 以上所有语句都给出了解析错误。 问题答案: 请阅读的文档time.Parse: 该布局通过显示参考时间(定义为 2006年1月2日星期一15:04:05-0700 如果它是值,将被解释;它用作输入格式的示例。然后将对输入字符串进行相同的解释。 所以正确的格式是
-
从docplex获取节点日志
CPLEX打印出漂亮的节点日志,如何使用docplex获取它们?我尝试过改变内容。解算器。详细和日志输出,但我没有得到要打印的信息(当前解决方案、间隙)。 我正在使用以下代码: 当verbose=5时,将打印所有分支决策(大量垃圾),而verbose=4时,不会打印间隙
-
计算复活节的日期
问题 你需要在给出的年份中找到复活节的月份和日期。 解决方案 下面的函数返回数组有两个要素:复活节的月份( 1-12 )和日期。如果没有给出任何参数,给出的结果是当前的一年。这是 在CoffeeScript 的匿名公历算法实现的。 gregorianEaster = (year = (new Date).getFullYear()) -> a = year % 19 b = ~~(year
-
有符号字节和无符号字节之间的自动转换?
我正在与Scribbler2机器人和Fluke2板工作,并通过Java中的Myro与Fluke沟通。Fluke board是Scribbler和用Java编写的桌面客户端之间的蓝牙通信桥梁。它通过一个RS232串口与涂写器通信。 这可能是一个愚蠢的问题,上面的系统很复杂,所以如果我不能很好地解释这一点,请原谅我。 我的问题的背景:Java使用有符号字节。Fluke是(我想)用C写的,所以使用了无符
-
了解Java字节
问题内容: 因此,在昨天的工作中,我不得不编写一个应用程序来计算AFP文件中的页数。因此,我整理了我的MO:DCA规范PDF,找到了结构化字段及其3个字节的标识符。该应用程序需要在AIX机器上运行,所以我决定用Java编写它。 为了获得最大效率,我决定读取每个结构化字段的前6个字节,然后跳过该字段中的其余字节。这会让我: 因此,我检查字段类型,如果是,则增加页面计数器,如果不是,则不增加。然后,我
-
Concat字节数组
问题内容: 有人可以指出以下更有效的版本吗 每个变量都是一个字节片,大小不一 : 码: : 基准测试结果: 问题答案: 如果已经分配了内存,则x = append(x,a …)的序列在Go中非常有效。 在您的示例中,初始分配(制造)的成本可能比附加序列的成本高。这取决于字段的大小。考虑以下基准: 在我的盒子上,结果是: 系统地重新分配缓冲区(甚至是很小的缓冲区)会使此基准测试速度至少慢5倍。 因此
-
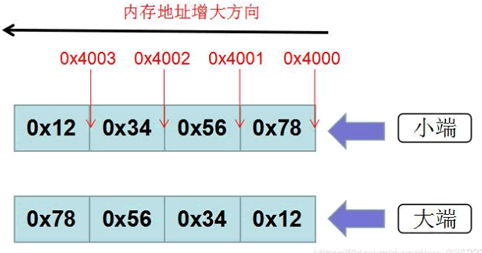 NumPy字节交换
NumPy字节交换主要内容:numpy.ndarray.byteswap()数据以字节的形式存储在计算机内存中,而存储规则可分为两类,即小端字节序与大端字节序。 小端字节序(little-endian),表示低位字节排放在内存的低地址端,高位字节排放在高地址段,它与大端字节序(big-endian)恰好相反。 对于二进制数 0x12345678,假设从地址 0x4000 开始存放,在大端和小端模式下,它们的字节排列顺序,如下所示: 图1:字节存储模式 小端存储后:0x