《总结和分享》专题
-
.NET中方法的注意事项总结
本文向大家介绍.NET中方法的注意事项总结,包括了.NET中方法的注意事项总结的使用技巧和注意事项,需要的朋友参考一下 本文较为详细的总结了.NET中方法的注意事项。分享给大家供大家参考。具体分析如下: 1. 方法中return 会终止整个方法段。 而break只能终止当前循环。 2. 方法就是一对可用代码的复用。 a . 对于可重用的代码,在vs中选中,右键 重构 提取方法。即可自动封装成一
-
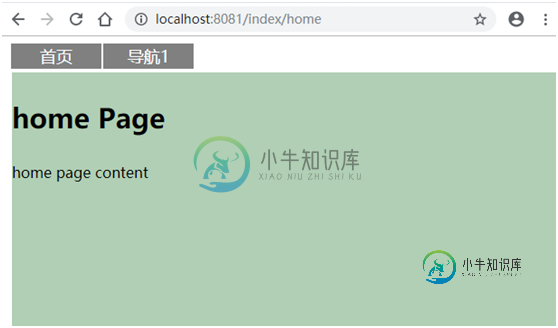 Vue 嵌套路由使用总结(推荐)
Vue 嵌套路由使用总结(推荐)本文向大家介绍Vue 嵌套路由使用总结(推荐),包括了Vue 嵌套路由使用总结(推荐)的使用技巧和注意事项,需要的朋友参考一下 开发环境 Win 10 node-v10.15.3-x64.msi 下载地址: https://nodejs.org/en/ 需求场景 如下图,我们希望点击导航栏不同菜单时,导航栏下方加载不同的组件,进而展示不同的页面内容 解决方案 使用动态路由 新建home.vue作
-
 Vue项目环境搭建详细总结
Vue项目环境搭建详细总结本文向大家介绍Vue项目环境搭建详细总结,包括了Vue项目环境搭建详细总结的使用技巧和注意事项,需要的朋友参考一下 关于Vue安装的详细步骤总结 安装NodeJs 首先解释一下什么是nodejs,为什么要安装node?node的优点? node.js是一个运行在chromeJavascript运行环境下(俗称GoogleV8引擎)的开发平台,用来方便快捷的创建服务器端网络应用程序,也可以把它理解为
-
Android中SQLite数据库知识点总结
本文向大家介绍Android中SQLite数据库知识点总结,包括了Android中SQLite数据库知识点总结的使用技巧和注意事项,需要的朋友参考一下 SQLite 数据库简介 SQLite 是一个轻量级数据库,它是D. Richard Hipp建立的公有领域项目,在2000年发布了第一个版本。它的设计目标是嵌入式的,而且占用资源非常低,在内存中只需要占用几百kB的存储空间,这也是Android移
-
ASP.NET过滤HTML字符串方法总结
本文向大家介绍ASP.NET过滤HTML字符串方法总结,包括了ASP.NET过滤HTML字符串方法总结的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了ASP.NET过滤HTML字符串的方法,供大家参考使用,具体代码如下:
-
 PHP/HTML混写的四种方式总结
PHP/HTML混写的四种方式总结本文向大家介绍PHP/HTML混写的四种方式总结,包括了PHP/HTML混写的四种方式总结的使用技巧和注意事项,需要的朋友参考一下 PHP作为一款后端语言,为了输出给浏览器让浏览器呈现出来,无可避免的要输出HTML代码,下文介绍下我用过的三种PHP/HTML混编方法 1、单/双引号包围法 这是最初级的方法了,用法就像下面这样 这样是最简单的一种方法了,直接用单引号包装上就行了 至于双引号和单引号的
-
 Vue.js watch监视属性知识点总结
Vue.js watch监视属性知识点总结本文向大家介绍Vue.js watch监视属性知识点总结,包括了Vue.js watch监视属性知识点总结的使用技巧和注意事项,需要的朋友参考一下 这个属性用来监视某个数据的变化,并触发相应的回调函数执行 1.基本用法 (1)添加watch属性,值为一个对象。对象的属性名就是要监视的数据,属性值为回调函数,每当这个属性名对应的值发生变化,就会触发该回调函数执行 (2)回调函数有2个参数: newV
-
JavaScript入门系列之知识点总结
本文向大家介绍JavaScript入门系列之知识点总结,包括了JavaScript入门系列之知识点总结的使用技巧和注意事项,需要的朋友参考一下 JavaScript一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。它的解释器被称为JavaScript引擎,为浏览器的一部分,广泛用于客户端的脚本语言,最早是在HTML(标准通用标记语言下的一个应用)网页上使用,用来给HTML网
-
java注解的类型知识点总结
本文向大家介绍java注解的类型知识点总结,包括了java注解的类型知识点总结的使用技巧和注意事项,需要的朋友参考一下 提到java里的注解,和我们平时的注释还是有很大的区别,主要是作为java特性来使用的,跟我们常见的类是同一个使用的层面。关于java注解的类型,我们可以简单分为:自定义注解和元注解。其中元注解里的JDK又有5中注解的类型,下面一起来看看具体的内容讲解吧。 1、自定义注解 定义注
-
ASP的服务总线体系结构。NETWebAPI
我正在使用Telerik平台开发一个移动应用程序。应用程序使用的服务是ASP。托管在Azure上的NETWebAPI RESTful服务。我想通过添加服务总线来增强应用程序的弹性,并且一直在关注Azure服务总线,这似乎就是我所寻找的。 这对我来说相当新鲜,我有几个问题。 Azure服务总线可以用于返回数据的RESTful服务吗? 对于简单的RESTful服务,是Azure服务总线还是Azure存
-
 【百度MUX】交互设计面试总结
【百度MUX】交互设计面试总结三轮面试都采取了电话面试的方式。一二三面的面试中都会提及你的作品集,所以请务必在面试前对自己做的东西了解透彻,不是自己的东西千万不要往上放。 【一面】会先电话沟通,约定时间准时打过来,不会进行突击检查,放心。 性质:基础面 时长:30分钟 一面的面试官提的问题是比较基本的,她主要测试的是你能不能对自己做的东西自圆其说,你在做东西的时候的主要思路,以及对交互设计的一些基本领域的了解。 第一部分是作品
-
 大数据开发暑期实习总结
大数据开发暑期实习总结前言 从2023年3月初开始投递暑期实习,几乎所有大厂都投递过了,有些简历都过不了,有些一面直接挂了,虽然说确实互联网行情不是特别的好,但是应该还是自己能力不足,做的简历不够漂亮; 4月的时候第一次刷到了@三石数据的面经帖(见下图),于是跟他聊了一下,真的收获太多了,非常非常感谢这位大佬的指导,不仅帮助我修改简历,而且还给我解答一些在面试中遇到的问题;大佬要是没女朋友的话,我愿意以身相许(开个玩笑
-
 联想,美团测开面试小总结
联想,美团测开面试小总结联想测开, 1围绕简历提问,八股,介绍项目,问的都不是很深, 2登录测试用例,口述sql查询 3对测开的看法和一些规划,还有遇到某个问题怎么处理,比如bug是前端还是后端的, 4经典的智力题5升,6升杯子问题, 忘记录音其他忘记了,都是常规的问题都不深,45分钟,像聊天。 oc了 美团测开, 一面45分钟, 1问各种基础八股,也是围绕简历问,所以简历写的一定得熟悉。 2算法题是判断回文 3怎么学习
-
第4章 OpenCL案例 - 4.7 本章总结
本章我们使用了一些著名的数据并行算法,将其使用OpenCL实现。直方图的例子展示了如何使用局部内存,并在执行阶段使用了适当的同步。旋转和卷积例子使用了图像对象和采样器。卷积例子中使用了C++ API,并将卷积核放置到常量内存中。生产者-消费者例子中,使用管道为两个内核传递所需的数据,并使用了多设备的方式实现。 虽然,这些OpenCL例子都是正确的,不过其性能还可以进一步提高——有些例子可以有很大的
-
用RXCollections进行函数式编程 - 总结
在过去的章节中,我们使用RXCollections后不需要额外的可变变量就可以在列表上进行操作,虽然RXCollections可能隐式地生成了这样的可变变量来完成任务,但是这不是我们要关心的,因为它已经为我们抽象出了这样的方式,通过:mapping\filtering和folding这种方式让我们不必在意实现任务的步骤。(当然,这并不是说,我们不应该熟悉RXCollections的源码,只是告诉你