《总结和分享》专题
-
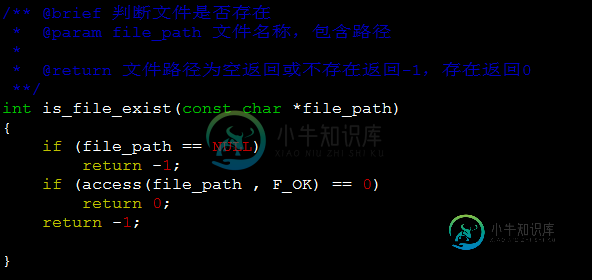 linux下判断文件和目录是否存在的方法(总结)
linux下判断文件和目录是否存在的方法(总结)本文向大家介绍linux下判断文件和目录是否存在的方法(总结),包括了linux下判断文件和目录是否存在的方法(总结)的使用技巧和注意事项,需要的朋友参考一下 1、前言 工作中涉及到文件系统,有时候需要判断文件和目录是否存在。我结合APUE第四章文件和目录,总结一下如何正确判断文件和目录是否存在,方便以后查询。 2、stat系列函数 stat函数用来返回与文件有关的结构信息。stat系列函数有三种
-
JQuery查找子元素find()和遍历集合each的方法总结
本文向大家介绍JQuery查找子元素find()和遍历集合each的方法总结,包括了JQuery查找子元素find()和遍历集合each的方法总结的使用技巧和注意事项,需要的朋友参考一下 1.HTML代码 2.jquery 以上这篇JQuery查找子元素find()和遍历集合each的方法总结就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
PHP循环遍历数组的3种方法list()、each()和while总结
本文向大家介绍PHP循环遍历数组的3种方法list()、each()和while总结,包括了PHP循环遍历数组的3种方法list()、each()和while总结的使用技巧和注意事项,需要的朋友参考一下 ①each()函数 each()函数需要传递一个数组作为参数,返回数组中当前元素的键/值对,并向后移动数组指针到下一个元素的位置。键/值对被返回带有4个元素的关联和索引混合的数组,键名分别为0、1
-
 PHP常用技术文之文件操作和目录操作总结
PHP常用技术文之文件操作和目录操作总结本文向大家介绍PHP常用技术文之文件操作和目录操作总结,包括了PHP常用技术文之文件操作和目录操作总结的使用技巧和注意事项,需要的朋友参考一下 一、基本文件的操作 文件的基本操作有:文件判断、目录判断、文件大小、读写性判断、存在性判断及文件时间等 结果: 二、目录的操作 目录的操作有:遍历目录、删除、复制、大小统计等 1、遍历目录 结果 2、统计目录大小 结果: 3、删除目录 删除成功的提示信息
-
C语言中获取和改变目录的相关函数总结
本文向大家介绍C语言中获取和改变目录的相关函数总结,包括了C语言中获取和改变目录的相关函数总结的使用技巧和注意事项,需要的朋友参考一下 C语言getcwd()函数:取得当前的工作目录 头文件: 定义函数: 函数说明:getcwd()会将当前的工作目录绝对路径复制到参数buf 所指的内存空间,参数size 为buf 的空间大小。 注: 1、在调用此函数时,buf 所指的内存空间要足够大。若工作目录绝
-
评价分类结果
综述 “以古为镜,可以知兴替;以人为镜,可以明得失。” 本文采用编译器:jupyter 首先提出一个关于分类准确度的问题: 一个癌症预测系统,输入体检信息就可以判断病人是否患有癌症。 如果这个系统的预测准确度为99.9%,这个系统是好是坏? 虽然99.9%的概率看上去比较大,但如果癌症产生的概率只有0.1%的话,我们辛辛苦苦做出来的系统和一个预测所有人都是健康的系统的性能完全相同;如果
-
1.5 Python分支结构
流程控制 流程: 计算机执行代码的顺序就是流程 流程控制: 对计算机代码执行顺序的管理就是流程控制 流程分类: 流程控制一共分为三类: 顺序结构 分支结构/选择结构 循环结构 分支/选择结构 分支结构一共分为4类: 单项分支 双项分支 多项分支 巢状分支 (1)单项分支 if 条件表达式: 一条python语句... 一条python语句... ... 特征: if条件表
-
3.2.1 单分支结构
3.2.1 单分支结构 下面我们来改进程序 3.1,使得程序能向游客提供一些温馨提示,例如当温度达到摄氏 35 度就发出高温警告信息。显然这里需要判断温度是否高于 35 度,并根据是或否来执行不 同的动作。 所有编程语言都提供了条件语句(if 语句),用来实现有条件地执行语句的功能。Python 语言的 if 语句有多种形式,最简单的形式是: if <条件表达式>: <条件语句体> 其中
-
目录结构分析
文件目录结构
-
获取所有可能的总和为给定数字的总和
问题内容: 我正在为Android开发一个数学应用程序。在这些字段之一中,用户可以输入一个整数(无数字且大于0)。这个想法是获得所有可能的和,使之成为整数,而不加倍(在这种情况下为4 + 1 == 1 + 4)。唯一已知的是此int。 例如: 假设用户输入4,我希望该应用返回: 4 3 + 1 2 + 2 2 + 1 + 1 1 + 1 + 1 + 1 显然4 == 4,所以也应该加上。关于我应该
-
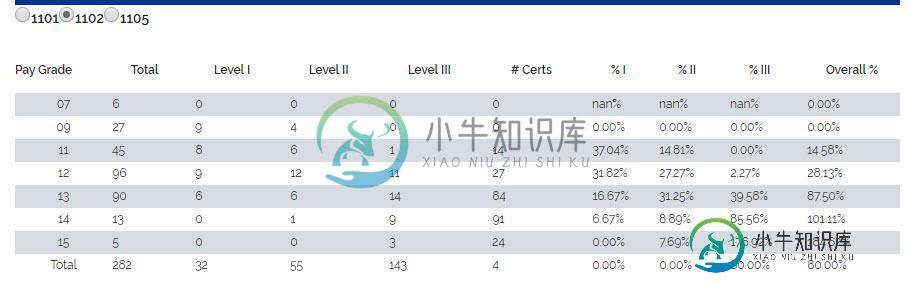 在multindex上使用loc或iloc选择进行总和和总计
在multindex上使用loc或iloc选择进行总和和总计我试图通过使用iloc或loc以及下面引用的数据集来更新表1(一级、二级和三级)。如果有建议,我愿意选择一种比loc和iloc更好的方法。 表1 例1 如果我希望表格更新为第13级和第三级工资等级的1102选择的新信息,我将使用以下pd.loc代码: 例2:这个也管用。 然而,挑战是当我需要选择多个索引或多列时。 多行 现在,如果我想更新表1,所有级别I的总计,而不是执行某种类型的df.isin,
-
JVM垃圾收集和分页内存体系结构
问题内容: 在最近的10年中,当讨论Java和/或垃圾回收时,我无法抗拒的唯一性能损失是,在分页内存体系结构中运行时,垃圾回收算法或多或少会中断,并且堆的某些部分会越来越多。分页。 Unix系统(尤其是Linux)积极地调出一段时间未使用的内存,尽管这对于您的普通泄漏c应用程序很有用,但它在内存紧张的情况下会杀死Java性能。 我知道最佳实践是将最大堆保留为小于物理内存。(或者您将看到您的应用程序
-
Lucene Analyzer查询和搜索结果相关性得分
首先,对不起我的英语不好! 我是Lucene图书馆的新人(从上周三开始),我试图了解如何根据找到的术语获得匹配文档的最佳相关性级别。 我使用Lucene 4.10。0(无Solr) 我能够索引/搜索英语/阿拉伯语文本,以及支持这些文本的点击突出显示。 现在我有一个问题与搜索结果的相关性。 如果我在三个文档中搜索“穆罕默德·奥马尔”: 我得到同样的分数为这3文档。 看起来Lucene忽略了单词顺序,
-
具有连接和分组的MySQL子查询结果
我很难让mySQL返回我想要的结果,因此希望有人能给我一些关于我错在哪里的指示。我有3个表(Sales\u Area、Orders、Rooflight\u Request),Orders包含一个Sales\u Area\u ID列以连接Sales\u Area,因此Sales\u Area可以有多个订单。Rooflight\u请求包含Order\u ID,因此一个订单可以有多个Rooflight\
-
Spring分页:参数映射和页面结果问题
我想使用Spring工具来实现我的分页。我目前没有底层数据库,想要从页面中提供的虚拟列表中输入请求。REST控制器中的请求如下: 当我卷曲或使用swagger发送请求时,总是使用可分页的默认值,而不是给定的大小、页面和排序等请求参数。请求URL看起来像: 自动完成映射需要什么吗?另一个问题是,如果我对页面和大小使用两个int参数,并使用静态PageRequest调用为我的服务提供可分页的页面。评估