
在multindex上使用loc或iloc选择进行总和和总计

我试图通过使用iloc或loc以及下面引用的数据集来更新表1(一级、二级和三级)。如果有建议,我愿意选择一种比loc和iloc更好的方法。
表1
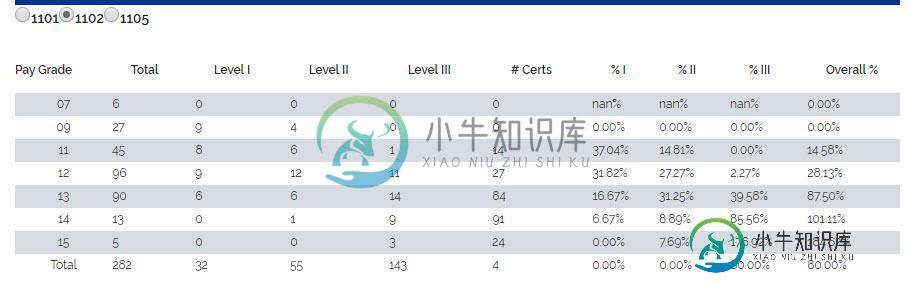
例1
如果我希望表格更新为第13级和第三级工资等级的1102选择的新信息,我将使用以下pd.loc代码:
jobseries = '1102'
result = df.loc[('3',jobseries),'13']
print (result)
14.0
例2:这个也管用。
jobseries = '1102'
result = df.loc[('3',jobseries),'13'].sum()
print (result)
14
然而,挑战是当我需要选择多个索引或多列时。
多行
现在,如果我想更新表1,所有级别I的总计,而不是执行某种类型的df.isin,我需要执行以下操作:
例3:
total = df.loc[('1',jobseries),'07'] + df.loc[('1',jobseries),'09'] + and so on...
print (total)
32
这是可行的,但我相信最终会抛出一个RuntimeWarning:在long_标量中遇到无效值。所以这不是最好的方法。有什么建议吗?
多列
现在,如果我想更新表1,一级、二级和三级的#证书,以及任何给定的等级,我无法计算代码。我尝试了以下方法,但它抛出了一个关键错误。我已经尝试了多种方法来做到这一点,但仍然无法弄清楚:
例4:
jobseries = '1102'
result = df.loc[('1','2','3',jobseries),'All']
print (result)
KeyError: "None of [[('1', '2', '3', '1102')]] are in the [index]"
这很奇怪,因为如果我检查我的索引,keyError会让我困惑。
df.index:
MultiIndex(levels=[['1', '2', '3', 'All'], ['', '0301', '0341', '0342', '0343', '0501', '0560', '0810', '0850', '1101', '1102', '1105', '1106', '1109', '1145', '1146', '1170', '1410']],
labels=[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3], [2, 3, 4, 6, 7, 9, 10, 11, 12, 13, 16, 17, 2, 8, 9, 10, 11, 1, 3, 4, 5, 9, 10, 11, 14, 15, 16, 0]],
names=['Level', 'JobSeries'])
我也试过df.xs:
例5:
jobseries = '1102'
result = df.xs(jobseries, level=1)
print (result)
01 07 08 09 11 12 13 14 15 All
Level
1 1.0 0.0 0.0 9.0 8.0 9.0 6.0 0.0 0.0 15
2 0.0 0.0 0.0 4.0 6.0 12.0 6.0 1.0 0.0 13
3 1.0 0.0 0.0 0.0 1.0 11.0 14.0 9.0 3.0 14
行或列中的更改
另一个挑战是,如果数据集更改,索引或行更改,pd.loc和pd.iloc将抛出一个键错误。这有什么关系吗?
df:
01 07 08 09 11 12 13 14 15 All
Level JobSeries
1 0341 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 1
0342 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 1
0343 0.0 0.0 0.0 0.0 0.0 2.0 0.0 0.0 0.0 2
0560 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 1
0810 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1
1101 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 1
1102 1.0 0.0 0.0 9.0 8.0 9.0 6.0 0.0 0.0 15
1105 0.0 7.0 3.0 5.0 0.0 0.0 0.0 0.0 0.0 9
1106 0.0 2.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 2
1109 0.0 0.0 0.0 0.0 2.0 0.0 0.0 0.0 0.0 2
1170 0.0 0.0 0.0 0.0 1.0 2.0 0.0 0.0 0.0 3
1410 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1
2 0341 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1
0850 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1
1101 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 0.0 2
1102 0.0 0.0 0.0 4.0 6.0 12.0 6.0 1.0 0.0 13
1105 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 1
3 0301 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1
0342 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1
0343 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1
0501 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1
1101 0.0 0.0 0.0 0.0 0.0 0.0 2.0 1.0 0.0 2
1102 1.0 0.0 0.0 0.0 1.0 11.0 14.0 9.0 3.0 14
1105 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1
1145 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1
1146 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 1
1170 0.0 0.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 2
All 2.0 8.0 4.0 11.0 11.0 14.0 15.0 9.0 4.0 17
参考:
pd.loc:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.loc.html
pd.xs:https://pandas.pydata.org/pandas-docs/version/0.22/generated/pandas.DataFrame.xs.html
pd.iloc:https://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-integer
共有1个答案

我不太清楚这个问题,但我会的
列的df.groupby(df.index).count()[13]或df.groupby(df.index).sum()[13],或
df.groupby(['Level','JobSeries']).sum().loc[1341]
完成你想要的?groupby中的level参数用于处理多索引问题
-
问题内容: 我一直在尝试从数据集中为所有行选择一组特定的列。我尝试了以下类似的方法。 我想提一下,所有行都包含在内,但只需要编号的列即可。有没有更好的方法来解决这个问题。 样本数据: 我试图忽略我的数据集中的工作,婚姻,教育和y栏。y列是目标变量。 问题答案: 如果需要按位置选择,请使用: 另一个解决方案是不必要的列:
-
我一直试图从数据集中为所有行选择一组特定的列。我尝试了下面这样的东西。 我想提到的是,所有行都是包含的,但只需要编号的列。有没有更好的方法来解决这个问题。 样本数据: 我试图忽略数据集中的工作、婚姻、教育和y列。y列是目标变量。
-
假设我有下面的数据框,我想将
-
有人能解释一下这两种切片方法有什么不同吗? 我看过文档,也看到过这些答案,但我还是发现自己无法理解这三种方法有什么不同。在我看来,它们在很大程度上是可以互换的,因为它们处于较低的切片级别。 例如,假设我们希望获得的前五行。这两个是怎么工作的? 谁能说出三种情况,在使用上的区别比较清楚? 从前,我也想知道这两个函数与有什么不同,但是已经从pandas 1.0中删除了,所以我不再关心了。
-
问题内容: 假设我有一张桌子: 这将返回自特定日期以来销售数量的产品清单。有没有一种方法不仅可以选择这个和,而且还可以选择没有where条件的和?我想查看每种产品自特定日期以来的销售情况以及所有(没有日期限制)的销售情况。 问题答案:
-
问题内容: 我在某人的iPython笔记本中看到了此代码,并且对 代码的工作方式感到非常困惑。据我了解,pd.loc []用作基于位置的 索引器,其格式为: 但是,在这种情况下,第一个索引似乎是一系列布尔值。 有人可以向我解释一下此选择的工作原理。我试图通读 文档,但找不到解释。谢谢! 问题答案: 可以使用一两个索引器。在其余文章中,我将第一个索引器表示为,将第二个索引器表示为。 如果仅提供一个索