
选择与. loc在python

我在某人的iPython笔记本上看到了这段代码,我对这段代码的工作原理感到非常困惑。据我所知,pd.loc[]用作基于位置的索引器,其格式为:
df.loc[index,column_name]
然而,在这种情况下,第一个索引似乎是一系列布尔值。有人能给我解释一下这个选择是如何工作的吗?我试图通读留档,但我想不出一个解释。谢谢!
iris_data.loc[iris_data['class'] == 'versicolor', 'class'] = 'Iris-versicolor'
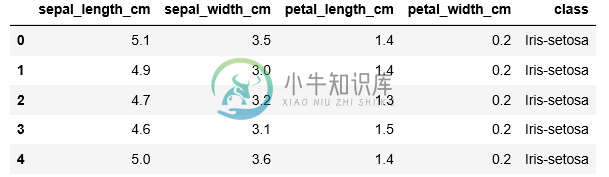
共有3个答案

这是一个熊猫数据帧,它使用带有df.loc的标签基选择工具,其中有两个输入,一个用于行,另一个用于列,所以在行输入中它选择所有这些保存在列class中的值为versicolor的行值,在列输入中,它选择带有标签class的列,并将Iris-versicolor值分配给它们。所以基本上,它用valueversicolor替换了列class的所有单元格。

这是使用pandas包中的数据帧。“索引”部分可以是单个索引、索引列表或布尔值列表。这可以在文档中阅读:https://pandas.pydata.org/pandas-docs/stable/indexing.html
因此,索引部分指定要拉出的行的子集,(可选)列名称指定要从该数据帧子集使用的列。因此,如果您想更新“class”列,但只更新当前将该类设置为“versicolor”的行,您可以执行类似于问题中列出的操作:
iris_data.loc[iris_data['class'] == 'versicolor', 'class'] = 'Iris-versicolor'

pd.DataFrame.loc可以采用一个或两个索引器。对于文章的其余部分,我将把第一个索引器表示为i,第二个索引器表示为j。
如果只提供了一个索引器,它将应用于数据帧的索引,并且假定缺少的索引器表示所有列。所以下面两个例子是等价的。
df.loc[i]
其中:用于表示所有列。
如果两个索引器都存在,i引用索引值,j引用列值。
现在我们可以专注于i和j可以假设的值类型。让我们使用下面的数据框df作为示例:
df = pd.DataFrame([[1, 2], [3, 4]], index=['A', 'B'], columns=['X', 'Y'])
loc的编写使得i和j可以
>
应为各个索引对象中的值的标量
df.loc['A', 'Y']
2
其元素也是相应索引对象的成员的数组(注意,我传递给loc的数组的顺序受到尊重
df.loc[['B', 'A'], 'X']
B 3
A 1
Name: X, dtype: int64
>
df.loc[['B', 'A'], ['X']]
X
B 3
A 1
其元素为True或False且其长度与相应索引的长度匹配的布尔数组。在这种情况下,loc只获取其中布尔数组为True的行(或列)。
df.loc[[True, False], ['X']]
X
A 1
除了可以传递给loc的索引器之外,它还使您能够进行赋值。现在我们可以分解您提供的代码行。
iris_data.loc[iris_data['class'] == 'versicolor', 'class'] = 'Iris-versicolor'
>
iris\u data['class']=='versicolor'返回一个布尔数组。class是表示columns对象中的值的标量。iris\u data.loc[iris\u data['class']='versicolor','class']返回一个pd.Series对象,该对象由'class'列组成,用于'class'为'versicolor' 与赋值运算符一起使用时:
iris_data.loc[iris_data['class'] == 'versicolor', 'class'] = 'Iris-versicolor'
我们为列'class'中的所有元素分配'Iris-versicolor',其中'class'为'versicolor'
-
问题内容: 我在某人的iPython笔记本中看到了此代码,并且对 代码的工作方式感到非常困惑。据我了解,pd.loc []用作基于位置的 索引器,其格式为: 但是,在这种情况下,第一个索引似乎是一系列布尔值。 有人可以向我解释一下此选择的工作原理。我试图通读 文档,但找不到解释。谢谢! 问题答案: 可以使用一两个索引器。在其余文章中,我将第一个索引器表示为,将第二个索引器表示为。 如果仅提供一个索
-
问题内容: 我一直在探索如何优化代码并跨 方法运行。根据文档 基于标签的快速标量访问器 与loc相似,at提供基于标签的标量查找。您也可以使用这些索引器进行设置。 因此,我运行了一些示例: 好像: 让我们使用并确保我得到相同的东西 测试速度使用 测试速度使用 这看起来是巨大的速度提高。即使在缓存阶段,速度也比 题 有什么局限性?我有动力去使用它。该文档说它类似于,但是行为却不一样。例: 结果在哪里
-
问题内容: 如果我只需要2/3列,而是查询而不是在select查询中提供这些列,那么关于更多/更少I / O或内存的性能是否会有所下降? 如果我确实选择了*,则可能会出现网络开销。 但是在选择操作中,数据库引擎是否总是从磁盘中提取原子元组,还是仅提取在选择操作中请求的那些列? 如果它总是拉一个元组,则I / O开销是相同的。 同时,如果它拉出一个元组,从元组中剥离请求的列可能会占用内存。 因此,在
-
问题内容: 我一直在尝试从数据集中为所有行选择一组特定的列。我尝试了以下类似的方法。 我想提一下,所有行都包含在内,但只需要编号的列即可。有没有更好的方法来解决这个问题。 样本数据: 我试图忽略我的数据集中的工作,婚姻,教育和y栏。y列是目标变量。 问题答案: 如果需要按位置选择,请使用: 另一个解决方案是不必要的列:
-
我一直试图从数据集中为所有行选择一组特定的列。我尝试了下面这样的东西。 我想提到的是,所有行都是包含的,但只需要编号的列。有没有更好的方法来解决这个问题。 样本数据: 我试图忽略数据集中的工作、婚姻、教育和y列。y列是目标变量。
-
我试图通过使用iloc或loc以及下面引用的数据集来更新表1(一级、二级和三级)。如果有建议,我愿意选择一种比loc和iloc更好的方法。 表1 例1 如果我希望表格更新为第13级和第三级工资等级的1102选择的新信息,我将使用以下pd.loc代码: 例2:这个也管用。 然而,挑战是当我需要选择多个索引或多列时。 多行 现在,如果我想更新表1,所有级别I的总计,而不是执行某种类型的df.isin,