《超聚变》专题
-
如何在Django JSONField数据上聚合(最小/最大等)?
问题内容: 我正在使用内置的Django 1.9 和Postgres 9.4。在模型的json字段中,我存储带有一些值(包括数字)的对象。我需要汇总它们以找到最小/最大值。像这样: 另外,提取特定的密钥将很有用: 上面的查询失败了 FieldError:“无法将关键字’my_key’解析为字段。不允许加入’attrs’。” 有可能吗? 笔记: 我知道如何进行简单的Postgres查询来完成这项工作
-
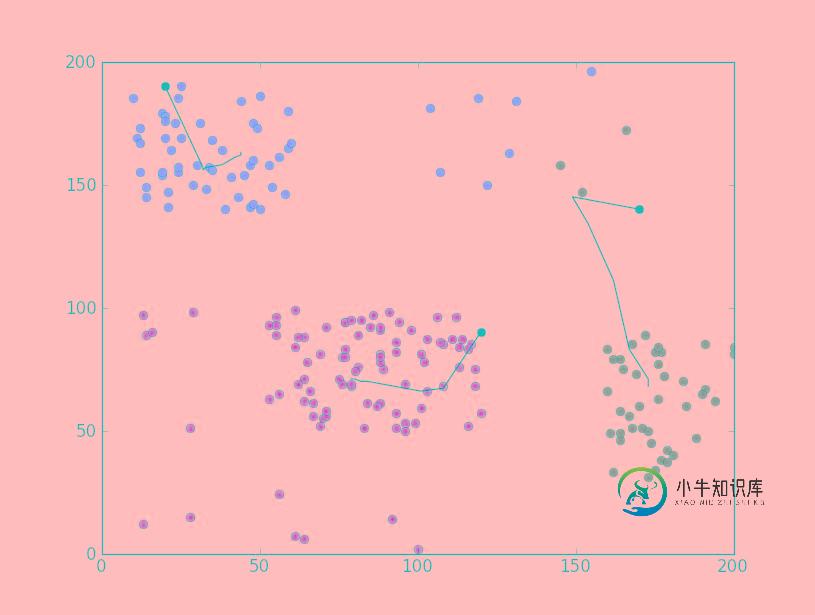 Python聚类算法之基本K均值实例详解
Python聚类算法之基本K均值实例详解本文向大家介绍Python聚类算法之基本K均值实例详解,包括了Python聚类算法之基本K均值实例详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python聚类算法之基本K均值运算技巧。分享给大家供大家参考,具体如下: 基本K均值 :选择 K 个初始质心,其中 K 是用户指定的参数,即所期望的簇的个数。每次循环中,每个点被指派到最近的质心,指派到同一个质心的点集构成一个。然后,根据指
-
将聚合运算符从SQL转换为关系代数
问题内容: 我编写了一些SQL查询,希望将其转换为关系代数。但是,某些查询使用聚合运算符,而我不知道如何转换它们。值得注意的是,它们使用COUNT和GROUP BY .. HAVING运算符。 这是模式: 水手( sid ,sname,评分)储备( sid , 出价 ,价格)船( 出价 ,bname) 这是我正在做的一个示例:查找恰好2个水手保留的所有船只的出价和名称。 允许的关系代数运算:选择,
-
需要对elasticsearch聚合结果中的_term进行排序
问题内容: 根据上述问题,我用Val给定的脚本进行的elasticsearch查询在最后一周之前都可以正常工作。我们已经升级了ES版本,但突然停止了工作。 现在突然我的ES停止使用脚本中包含“ as Integer”的代码。任何人都可以检查和帮助。 我尝试了给定的查询,现在它抛出以下异常。 我作为参数传递的查询是: 由于我的索引器在该字段中包含1、2、4、6、14个值。但是执行完此查询后,我只得到
-
Elasticsearch聚合:如何对存储桶顺序进行排序
问题内容: ES版本:1.5(Amazon Elasticsearch) 我的目标:在某个字段上具有重复数据删除功能的搜索结果。我目前正在对聚合进行一些研究,以解决重复数据删除问题。因此,我的结果是一个带有1个大小的存储桶的列表存储桶。但是,我找不到订购存储桶列表的方法。 当前查询: 结果: 我想看到第二个存储桶,其中max_score = 68.78424为第一个。这可能吗? 如果不建议使用聚合
-
ElasticSearch Nest。术语聚合及其迭代的更好代码
问题内容: 我想获取给定期间内唯一数字用户ID的列表。 假设字段为,时间字段为,我成功获得如下结果; 它 可以工作, 但效率不高,因为(1)首先获取,并且(2)它定义由于存储桶溢出(如果结果有成千上万个),可能导致500个服务器错误。 以某种方式进行迭代会很好,但是我无法使它们按大小迭代。我在这里放了/ 或/ ,但是返回值不可靠。 如何正确编码? 问题答案: 对于某些集合,此方法可能是可行的,但需
-
在ElasticSearch中过滤,嵌套的inner_hits查询上的聚合
问题内容: 我刚开始使用ElasticSearch几天,而作为一项学习练习,我实施了一个基本的工作搜寻器,该工作收集器汇总了一些求职网站上的工作,并在其中填充了一些数据供我使用。 我的索引包含每个列出职位的网站的文档。每个文档的一个属性是一个“作业”数组,其中包含该站点上存在的每个作业的对象。我正在考虑将每个作业作为自己的文档建立索引(特别是因为ElasticSearch文档说inner_hits
-
K-均值聚类中距离质心最近的M点
我已经实现了一个函数,在运行K-Means聚类算法后,找到距离每个质心最近的数据点。我想知道是否有一个函数可以让我找到距离每个质心最近的M个点。
-
什么时候使用关联、聚合、组合和继承?
我在Stackoverflow上看到了很多解释关系区别的帖子:关联、聚合、组合和继承,并附有例子。然而,更具体地说,我对每种方法的优点和缺点,以及什么时候一种方法对手头的任务最有效感到困惑。这是我一直无法找到一个好答案的事情。 为了与论坛的指导方针保持一致,我没有问为什么人们个人更喜欢使用继承而不是组合。我特别感兴趣的是每种方法中的任何客观优点/缺点,尽管听起来很强。一、 e.一种方法是创建比另一
-
如何用自定义对象处理和聚合Kafka流?
所以基本上我有会计课。我有数据。我想将这些对象发送到我与生产者的主题中。现在没关系。稍后,我想使用 Kafka 流进行聚合,但我不能,因为某些 Serde 属性在我的配置中是错误的,我认为 :/。我不知道错误在哪里。我的制作人工作正常,但我无法聚合。有人帮我查看我的 kafka 流代码吗?我的帐户类: 我的Account类有两个类Serializer和Deserializer。序列化程序: 反序列
-
 电子浏览器窗口聚焦时显示任务栏
电子浏览器窗口聚焦时显示任务栏我的应用程序是一个全屏游戏的覆盖图(alwaysOnTop),当用户点击我的覆盖图时,它会聚焦并在游戏顶部显示任务栏。集中注意力是好的,但我不能有任务栏显示。 null 不是不能关注的工具箱窗口 这意味着有可能创建一个无法关注的窗口。 有人知道如何创建一个工具箱窗口,或者简单地避免在点击电子窗口时显示任务栏吗? 我应该提到我已经尝试了 和 。我还有 和 。 我创建的覆盖是“安全,中线,离线”按钮。
-
差异聚合,相识和组成(由四人帮使用)
我一直在读Erich Gamma等人的《设计模式:可重用面向对象软件的元素》,并且读到了解释聚集和相识的部分(第22-23页)。以下是摘录(抱歉,如果太长,但我认为解释这个问题很重要): 考虑对象聚合和相识之间的区别,以及它们在编译和运行时表现出的不同。聚合意味着一个对象拥有另一个对象或对另一个对象负责。通常我们说一个对象具有或是另一个对象的一部分。聚合意味着聚合对象和它的所有者有相同的生命周期。
-
事件时间上的聚合函数和过程函数
在这里输入代码需要在kafka流中使用flink和out聚合数据值放一个新的主题。 聚合应该发生在eventtime,而不是进程时间,这意味着数据对象中的时间戳。 遵循Flink教程中的示例,使用TumblingEventTimeWindow,但根本不调用聚合getResult方法。 如果我更改为TumblingProcessingTimeWInow,getResult将被调用并将结果下沉。 由于
-
基于事件源的微服务响应聚合机制
在实现基于事件源的微服务时,我们遇到的主要问题之一是聚合响应数据。例如,我们可能有两个实体,如学校和学生。一个微服务可能负责处理学校相关的业务逻辑,而另一个微服务可能处理学生。 现在,如果有人通过RESTendpoint进行查询并询问某个特定的学生,他们可能希望了解学校和学生的详细信息,那么对我来说,唯一已知的方法是以下方法。 > 使用类似于服务链接的东西。一个例子是Api-Gateway在向几个
-
如何在PostgreSQL中获取聚合的定义/源代码?
问题内容: 但是,如何在没有GUI客户端的情况下获取该语句(例如,使用psql命令行)? 问题答案: 像这样的东西,但是我不确定这是否涵盖创建聚合的所有可能方式(它确实没有考虑到使用引号引起来的标识符)