《烽火》专题
-
RDD火花质疑
我想了解以下关于火花概念的RDD的事情。 > RDD仅仅是从HDFS存储中复制某个节点RAM中的所需数据以加快执行的概念吗? 如果一个文件在集群中被拆分,那么对于单个flie来说,RDD从其他节点带来所有所需的数据? 如果第二点是正确的,那么它如何决定它必须执行哪个节点的JVM?数据局部性在这里是如何工作的?
-
理想火花构型
我在我们的项目中使用了HDFS上的Apache spark和MapR。我们正面临着运行火花工作的问题,因为它在数据小幅增加后失败了。我们正在从csv文件中读取数据,做一些转换,聚合,然后存储在HBASE中。 请建议,如果上面的配置看起来很好,因为am geting的错误看起来像是要离开内存。
-
火花作业错误超出GC开销限制[重复]
我正在运行一个火花作业,我在spark-defaults.sh.设置了以下配置,我在名称节点中有以下更改。我有1个数据节点。我正在处理2GB的数据。 但我得到一个错误,说GC限制超过。 这是我正在编写的代码。 我甚至尝试了GroupByKey而不是也。但是我得到了同样的错误。但是,当我试图删除还原ByKey或GroupByKey我得到的输出。有人能帮我解决这个错误吗? 我是否也应该在hadoop中
-
火花流式DStream元素与RDD
本质上,我想对dStream中的每个元素应用一组函数。目前,我正在为pyspark.streaming.dstream使用“map”函数。根据文档,我的方法似乎是正确的。http://spark.apache.org/docs/latest/api/python/pyspark.streaming.html#pyspark.streaming.dstream map(f,preservesPart
-
火花流和高可用性
我正在构建作用于多个流的Apache Spark应用程序。 我确实阅读了文档中的性能调优部分:http://spark.apache.org/docs/latest/streaming-programming-guide.html#performan-tuning 我没有得到的是: 1)流媒体接收器是位于多个工作节点上,还是位于驱动程序机器上? 2)如果接收数据的节点之一失败(断电/重新启动)会发
-
如何存储火花流数据
在spark streaming中,流数据将由在worker上运行的接收器接收。数据将被周期性地推入数据块中,接收者将向驱动程序发送receivedBlockInfo。我想知道这会引发流将块分发到集群吗?(换句话说,它会使用分发存储策略吗)。如果它不在集群中分发数据,如何保证工作负载平衡?(我们有一个10s节点的集群,但只有几个接收器)
-
用TTL节省Cassandra的火花
我正在使用Spark-Cassandra连接器1.1.0和Cassandra 2.0.12。 谢谢, 沙伊
-
火花+卡珊德拉。带聚类顺序问题的复合密钥
我有C*列族来存储类似事件的数据。以这种方式在CQL3中创建的列族: null 提前谢谢你。
-
火花(贝壳),卡桑德拉:你好,世界?
Maven中央存储库(Spark-Cassandra-Connector-Java2.11) 那么,在本地运行Spark和Cassandra之后,如何创建keyspace、表和插入行呢?
-
上游太大-nginx+码点火器
我从Nginx得到了这个错误,但似乎无法解决它!我正在使用codeigniter,并正在使用数据库进行会话。所以我想知道头怎么会太大。是否无论如何都要检查标题是什么?或者看看我能做些什么来修复这个错误? 现在我仍然得到以下内容:
-
火基地能让你多长时间?
油门误差会持续多久?
-
控制硒中的火狐标签
根据< code>window_handles文档: 窗口句柄(_H) 返回当前会话中所有窗口的句柄。 但是,在打开一个新选项卡后,我无法在列表中看到新句柄: 如您所见,具有相同的值,但我看到浏览器中打开了 2 个选项卡。是我做错了什么吗?如果是,我应该如何获取新选项卡的句柄? 使用: 硒 2.44.0 (最新) 火狐 35.0 (最新) 蟒蛇 2.7.6 请注意,如果我在Chrome中做类似的事
-
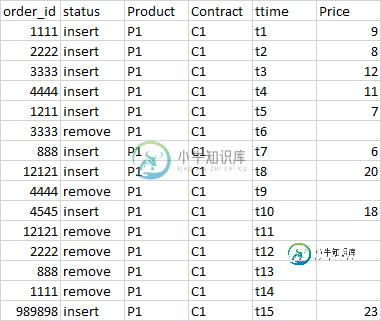 时间序列/刻度数据集的火花转换
时间序列/刻度数据集的火花转换我们在蜂巢中有一个表,它将每天结束时的交易订单数据存储为order_date。其他重要的列是产品、合同、价格(订单价格)、ttime(交易时间)状态(插入、更新或删除)价格(订单价格) 我们必须以滴答数据的方式从主表中构建一个图表表,其中包含从市场开盘到开盘的上午每行(订单)的最大和最小价格订单。i、 e对于给定的订单,我们将有4列填充为maxPrice(到目前为止的最高价格)、maxpriceO
-
火花:错误未找到值SC
我刚从Spark开始。我已经用Spark安装了CDH5。然而,当我尝试使用sparkcontext时,它给出了如下错误 我对此进行了研究,发现了错误:未找到:值sc 并试图启动火花上下文。/Spark-shell。它给错误
-
火花流作业不可恢复
我正在使用一个火花流作业,它使用带有初始RDD的mapAnd State。当重新启动应用程序并从检查点恢复时,它会失败,出错: 此RDD缺少SparkContext。它可能发生在以下情况: RDD转换和操作不是由驱动程序调用的,而是在其他转换内部调用的;例如,rdd1.map(x= 中描述了此行为https://issues.apache.org/jira/browse/SPARK-13758但它