《差旅壹号》专题
-
Depthwise 卷积实际速度与理论速度差距较大,解释原因。
本文向大家介绍Depthwise 卷积实际速度与理论速度差距较大,解释原因。相关面试题,主要包含被问及Depthwise 卷积实际速度与理论速度差距较大,解释原因。时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 首先,caffe原先的gpu实现group convolution很糟糕,用for循环每次算一个卷积,速度极慢。第二,cudnn7.0及之后直接支持group convolutio
-
如何基于时间戳(具有几秒钟的差异)联接两个表?
问题内容: 我有两个要结合并插入到基于三列组合的另一个表中的表。我会解释。 表M 表N 现在,这两个表必须匹配,并根据以下内容插入到 表MN 中: 所以从理论上讲,我的输出 表MN 应该是 表M 大约有140万条记录, 表N 大约有90万条记录。 我已尝试根据以下两个查询将两个表连接起来。但是执行需要花费数小时,如果我必须每天运行一次,这是不可行的。 当我只运行上述2个查询的SELECT语句时,在
-
32位和64位寄存器是否会导致CPU微架构的差异?
我试图比较Peter Cordes在回答“将CPU寄存器中的所有位设置为1”的问题时提到的方法。 因此,我编写了一个基准测试,将所有13个寄存器设置为除、和之外的所有位1。 代码如下所示<代码>乘以32 nop用于避免DSB和LSD影响。 我测试了他提到的以下方法,以及这里的完整代码 为了使这个问题更简洁,我将使用替换下表中的。 下表显示,从组1到组3,当使用64位寄存器时,每个循环多1个周期。
-
为什么tflite模型的精度与keras模型有如此大的差异?
我做了一个模型,预测一个字符在一个图像,做车牌识别。它在我的电脑上运行得非常好,但我需要把这项工作放在一个Android应用程序中。所以我开发了一个小应用程序,将我的keras模型转换为TFLITE。现在它总是预测同一个角色。 有没有更好的方法转换模型,还是我遗漏了什么? 编辑:这是我管理位图的操作
-
多API查询字符串、POST请求的差异及其与Postman的使用
以下QUERY_STRING,,和之间的尊重是什么?我应该在什么时候使用它们? 在邮递员中,有不同类型的邮寄请求,例如: 参数 身体形式数据 体x-wow-form-urlencoded 身体生 体二进制 它们之间的区别是什么?何时可以使用它们?邮递员正文请求和查询字符串之间是否存在任何关系? 如果我使用Node Express创建API,并使用React前端,我应该在Node Express A
-
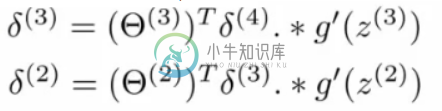 反向传播(神经网络)中获取增量项时的尺寸误差
反向传播(神经网络)中获取增量项时的尺寸误差我正在创建一个具有以下维度的三层图像识别神经网络:400个特征、40个节点、40个节点、10个目标(数字0到9的图像),因此这些是我的权重(θ): 我遵循吴恩达的方法。我在反向传播工作中遇到了一些问题。首先,我通过找出实际结果和预测之间的差异来得到delta\u 4项。然后,使用以下等式获得剩余的δ项, 其中g'是sigmoid函数的导数。我编码了以下函数: 然后,获得梯度的整个反向传播过程如下所
-
我如何从Keras的一个经过培训的模型中获得偏差?
我建立了一个简单的神经网络, 我可以通过以下方式获得其重量: 但是,通过这种方式,我只得到了没有偏差的权重矩阵(5x20,1x20)。如何获取偏差值?
-
是否可以将TFLite配置为返回偏差量化为int8的模型?
我正在与Keras/Tensorflow合作开发一种将部署到低端MCU的ANN。为此,我使用Tensorflow Lite提供的训练后量化机制对原始ANN进行量化。如果权重确实量化为int8,则偏差将从float转换为int32。考虑到我假装在CMSIS-NN中实现这个ANN,这是一个问题,因为它们只支持int8和int16数据。 是否可以将TF Lite配置为也将偏差量化为int8?下面是我正在
-
如何使用HQL(Hibernate)查询日期的平均差异(以天为单位)?
我需要从使用Hibernate映射到Java的PostgreSQL数据库中检索记录的平均日期差(您可能会说开始和结束)。 我编写了一个本机PostgreSQL查询,效果很好: 问题是,由于部分的原因,我无法理解如何将此查询转换为HQL(Hibernate SQL)。 我需要在前端显示信息,这是我用JSF Primeface构建的。 备注:dataEntrada-指起始日期(种类)。dataSaid
-
试图用GEKKO求解这个非线性优化,得到了这个误差
@错误:使用序列设置数组元素 我试图确定下行风险。 我有一个回报形状的二维数组(1000,10),投资组合从100美元开始。在一行中每一个回报复合10次。对所有行都这样做。将每一行的最后一个单元格的值与最后一列值的平均值进行比较。如果值小于平均值或为零,则保留该值。所以我们将有一个(1000,1)数组。最后我找到了它的均方差。 目标是最小化均方差。约束:权重需要小于1 预期回报,即wt*ret应等
-
何时重置索引?loc与iloc在索引中的差距?最佳实践?
我在代码中发现了一个非常微妙的错误。在分析中,我经常从数据帧中删除行。因为这将在索引中留下间隙,所以我尝试通过在末尾用 然后在下一个函数中继续使用 但是,如果我没有正确重置索引,第一行的索引可能是192。192的索引与0的行号不同。这导致了这样一个问题:df0.loc[row]访问索引为0的行,而df0.iloc[row]正在访问索引为192的行。这导致了一个非常奇怪的错误,我试图更新第0行,但索
-
网格步长(两个相邻机器可表示数字之间的差值
我编写了这样一个代码来寻找网格步长(两个相邻的机器可表示数之间的差,机器ε,最小机器可表示数大于1和1之间的差)。为什么这个程序显示1代表巨大的价值关于x,以及如何修正它以显示正确答案?
-
如何在Javascript中以mm dd hh格式获取两个日期的差异
我可以用时间来区分两次约会。js或普通js。 马上。js 月返回月,天返回日差。但我想知道答案 MM DD hh格式,例如2个月12天5小时。我不能直接转换日期,因为还有其他问题,比如闰年。那么,还有别的办法全力以赴地计算一切吗?如果这对我有帮助的话,我是在做这件事
-
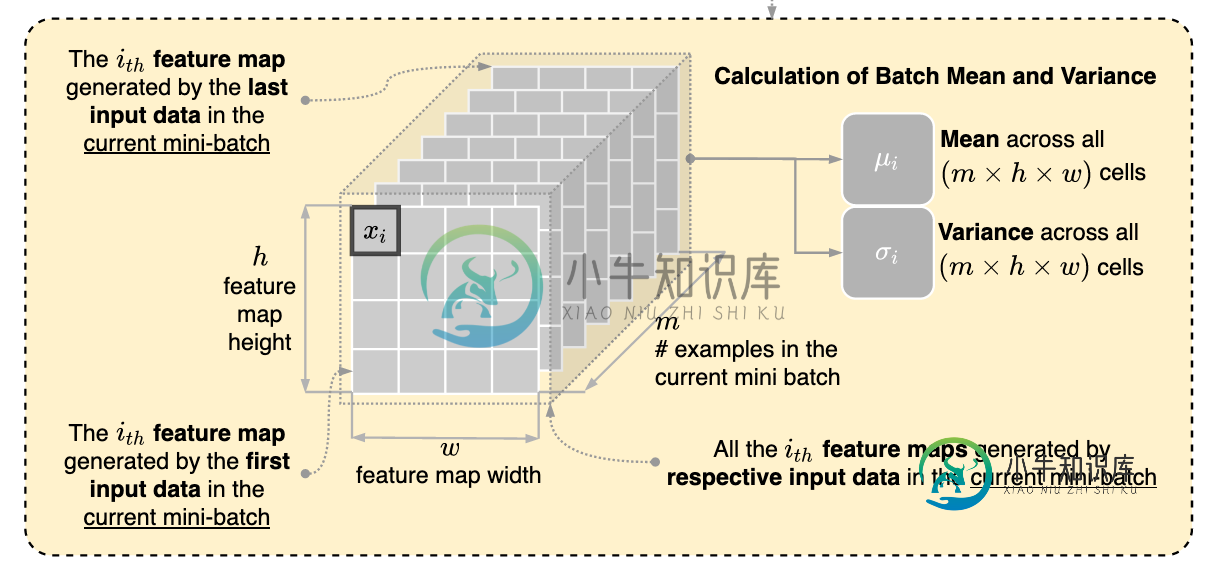 卷积神经网络批量归一化中均值和方差的计算
卷积神经网络批量归一化中均值和方差的计算请问以下对卷积神经网络中批量归一化的理解是否正确? 如下图所示,均值和方差是使用当前小批量中各个示例生成的相同特征图上的所有单元格计算的,即它们是跨h、w和m轴计算的。
-
应用程序之间的差异。使用和应用程序。坐快车。js
我对表达和node.js有点陌生,我不知道app.use和app.get.之间的区别。似乎你可以用它们来发送信息。例如: 似乎与此相同: