《NLP》专题
-
如何使用Open nlp的分块解析器提取名词短语
问题内容: 我是自然语言处理的新手。我需要从文本中提取名词短语。到目前为止,我已经使用open nlp的分块解析器来解析我的文本以获得Tree结构。但是我无法从中提取名词短语。树结构,在打开的nlp中是否有任何正则表达式模式,以便我可以用它来提取名词短语。 下面是我正在使用的代码 在这里,我得到的输出为 (TOP(S(S(ADJP(JJ欢迎光临)(PP(TO至)(NP(NNP大)(NNP数据。
-
Java Stanford NLP:语音标签的一部分?
问题内容: 在此处演示的Stanford NLP 给出如下输出: 词性标签是什么意思?我找不到正式名单。是斯坦福大学自己的系统,还是使用通用标签?(例如,什么是?) 另外,当我遍历句子时,例如,寻找名词时,我最终会做类似检查标签是否的事情。这感觉很虚弱。是否有更好的方法以编程方式搜索语音的某个部分? 问题答案: 宾夕法尼亚州树银行项目。查看词性标记 ps。 JJ是形容词。NNS是名词,复数。VBP
-
Stanford NLP for Python
问题内容: 我要做的就是找到任何给定字符串的情绪(正/负/中性)。在研究中,我遇到了斯坦福大学NLP。但是可悲的是它在Java中。关于如何使它适用于python的任何想法? 问题答案: 下载Stanford CoreNLP 目前(2020-05-25)的最新版本是4.0.0: 如果您没有,则可能有: 如果其他所有方法均失败,请使用浏览器;-) 安装套件 启动服务器 笔记: 以毫秒为单位,我将其设置
-
 极氪智能座舱NLP & 比亚迪规划院NLP 面经
极氪智能座舱NLP & 比亚迪规划院NLP 面经吉利 让我也打开简历,简单做个自我介绍(说着说着就开始讲细节了,嘴管不住) 了解的知识图谱的书,推荐些(推荐了大老板的= =) 了解的哪些做的比较好的国内NLP/KG团队(清华KSE、刘知远、浙大OpenKG--我说不确定是啥具体实验室,我关注了这个公众号和网站) 多任务模型的loss怎么自适应权重 crf原理 基于Bert的序列标注任务去掉crf效果是否有影响 lstm的门有哪些,怎么运算的(这
-
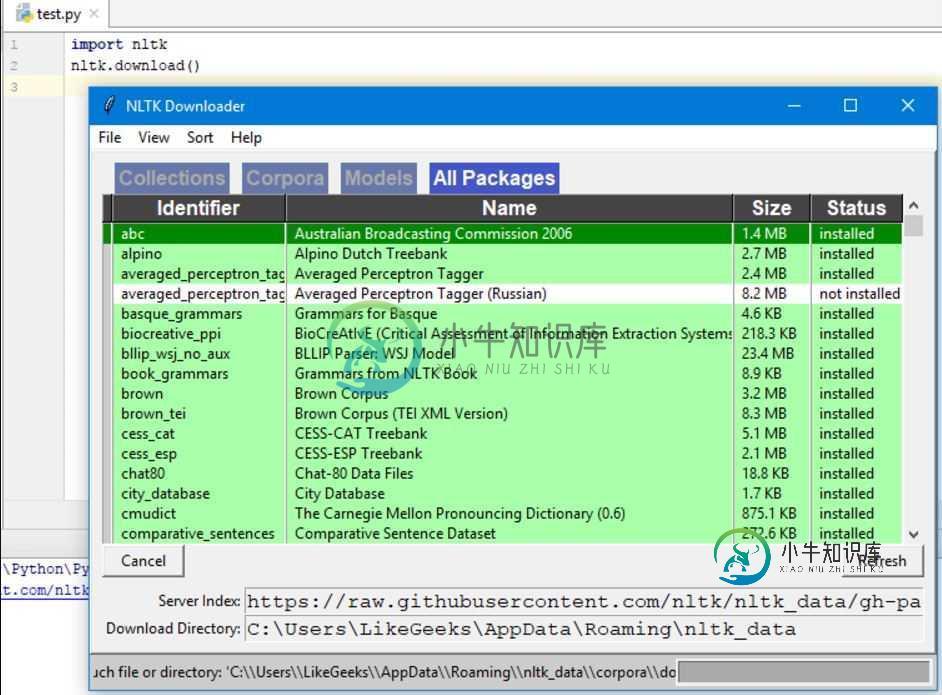 浅谈Python NLP入门教程
浅谈Python NLP入门教程本文向大家介绍浅谈Python NLP入门教程,包括了浅谈Python NLP入门教程的使用技巧和注意事项,需要的朋友参考一下 正文 本文简要介绍Python自然语言处理(NLP),使用Python的NLTK库。NLTK是Python的自然语言处理工具包,在NLP领域中,最常使用的一个Python库。 什么是NLP? 简单来说,自然语言处理(NLP)就是开发能够理解人类语言的应用程序或服务。 这里
-
如何使用Stanford NLP Tagger和NLTK提高速度
问题内容: 有什么方法可以以更高性能的方式使用Standford Tagger? 每次调用NLTK的包装器时,每个分析的字符串都会启动一个新的Java实例,这非常慢,尤其是在使用较大的外语模型时。 http://www.nltk.org/api/nltk.tag.html#module- nltk.tag.stanford 问题答案: 找到了解决方案。可以在servlet模式下运行POS Tagg
-
Python阿拉伯语NLP
问题内容: 我正在评估NLTK处理阿拉伯文本的能力,这项研究旨在分析和提取情感。 问题如下: NTLK是否可以处理并允许分析阿拉伯文本? python是否能够操纵\标记阿拉伯文本? 我可以使用Python解析和存储阿拉伯文本吗? 如果python和NTLK不是完成这项工作的工具,那么您会推荐哪些工具(如果存在)? 谢谢。 编辑 根据研究: NTLK仅能阻止阿拉伯文本:链接 Python支持UTF-
-
JAVA中使用哪个NLP工具包?
问题内容: 我正在做一个项目,该项目包括一个网站,该网站连接到NCBI(国家生物技术信息中心)并在其中搜索文章。问题是我必须对所有结果进行一些文本挖掘。我正在使用JAVA语言进行文本挖掘,并使用ICEFACES与AJAX进行网站开发。我拥有什么:搜索返回的文章列表。每篇文章都有一个ID和一个摘要。这个想法是从每个抽象文本中获取关键字。然后比较所有摘要中的所有关键字,找到重复次数最多的关键字。因此,
-
CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性?
本文向大家介绍CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性? 相关面试题,主要包含被问及CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通
-
 CNN为什么可以应用在CV、NLP、SPEECH乃至ALPHA GO中?
CNN为什么可以应用在CV、NLP、SPEECH乃至ALPHA GO中?本文向大家介绍CNN为什么可以应用在CV、NLP、SPEECH乃至ALPHA GO中?相关面试题,主要包含被问及CNN为什么可以应用在CV、NLP、SPEECH乃至ALPHA GO中?时的应答技巧和注意事项,需要的朋友参考一下 以上几个不相关问题的相关性在于,都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。如下图:低层次的直线/曲线等特征,组合成
-
Matlab中一般非凸/非线性约束问题(NLP)求解器的包装器
我有一个具有一般非凸不等式约束的一般非凸函数。我有一个可行的起点,我想最小化约束下的能量。求解器不应离开可行域(即障碍法),也不应增加能量。到目前为止,我使用的fmincon在这两个帐户上都失败了,我想用一种简单的方法来尝试其他解算器,如IPOPT、KNITRO和SNOPT。说到这里,我不介意推荐一个特定的解算器来完成我想要的(不增加并保持在可行区域)。 我想尝试其他求解器,但我正在寻找在某个包装
-
在非线性求解器中,什么影响求解器时间与NLP函数评估?
我很难理解非线性优化中的性能如何受到求解器引擎接口的特定方式的影响。 我们有一个优化模型,在它的第一个版本中,是用GAMS编写的。IPOPT(一个常见的FOOS非线性求解器引擎)在IPOPT(无函数评估)中为每个优化返回1.4 CPU秒的执行时间,在函数评估中返回0.2 CPU秒的执行时间。 当我们将模型转换为C(以便更好地考虑模型的非优化组件)并通过其C API接口IPOPT时(使用ADOL-C
-
使用Pyomo MindtPySolver设置MIP和NLP解算器路径
我正在使用Pyomo 5.6.8,并尝试使用MindtPySolver解决非线性优化问题。 我在本地机器上没有问题,只需使用以下参数调用solve方法: 但是,当我在Azure上云时,Pyomo无法获取CBC和IPOPT求解器的路径。当需要解决线性问题时,我可以使用以下命令绕过该问题,方法是在使用LP求解器创建实例时添加参数: 在我的非线性规划案例中,MindtpySolver不接受额外的参数。我
-
如何使用NLP库从句子中提取谓语和主语?
我想使用从句子中找到谓语和主语。这种技术在的世界中有任何名称吗?或者有什么方法可以做到这一点吗? 他喜欢孩子。结果:(他,喜欢孩子)
-
斯坦福NLP解析器。如何拆分树?
如果我从主页上举个例子: 斯坦福解析器: 交付下面的树: 我现在想拆分依赖于其结构的树以获取子句。所以在这个例子中,我想拆分树以获得以下部分: 印度有史以来最强的降雨 最强的降雨导致孟买金融中心关闭 最强的雨切断了通讯线路 最强降雨导致机场关闭 大雨迫使数千人睡在办公室 强降雨迫使数千人在夜间步行回家 所以第一个答案是使用递归算法打印所有根到叶的路径。 以下是我尝试过的代码: 当然,这段代码完全不