《2022毕业即失业取暖地》专题
-
Spring批处理:重新运行作业后重复行
我们的Spring Batch应用程序在重新启动失败的作业时,再次处理相同的记录,导致重复的行,我们希望了解如何避免这种情况。 启动批处理作业的Spring集成轮询器配置为每两个小时运行一次。第二次运行时,作业参数将相同,但如果上一次运行失败(例如,由于数据截断异常),Spring Batch不会抱怨作业已完成。 在故障点,几十万条记录已经被处理并从源表复制到目标表。在以后运行作业时,相同的行将复
-
用于与web服务同步的Android后台作业
你能告诉我在Android中做同步工作的正确方法是什么吗(例如,如果我有大约5个工作)<注意 我所说的同步作业是指在后台运行并通过Web服务发送一些数据(如分析)的线程。。。 有关更多详细信息,请阅读更详细的描述: 我的任务是实现一些后台作业,这些作业将使一些数据与restful web服务同步。一些作业应定期安排,并有特定的延迟。如果没有internet连接,我只需缓存数据,然后当连接再次出现时
-
Salesforce:如何在专业版中激活Apex类功能
我正在从事salesforce项目,需要添加一个包。问题是,在开发人员控制台下,我无法创建Apex类,这导致在将包添加到salesforce时出现以下错误。 这是我在尝试安装软件包时遇到的错误 在阅读了许多论坛之后,我得出了一个结论,我需要在权限集下激活Apex作者权限。但那里没有许可证。 我为salesforce创建了一个开发人员帐户,其中Apex类已经处于活动状态,可以导入包并进行更改。 Sa
-
Spring Batch中我的业务逻辑应该在哪里?
我有一个Spring批处理应用程序。我的Spring批处理应用程序由两个步骤组成。 提取csv数据,添加到记录tbl 提取记录tbl行,根据数据验证解析到Food tbl。 步骤2使用微线程完成 我需要处理记录行tbl,无论是否验证,当前日期时间都会添加回记录行 a.验证失败,DateTime错误代码也将添加到记录行中 b.通过验证,日期时间添加到记录行中。Row也将添加到食品tbl中。 在步骤2
-
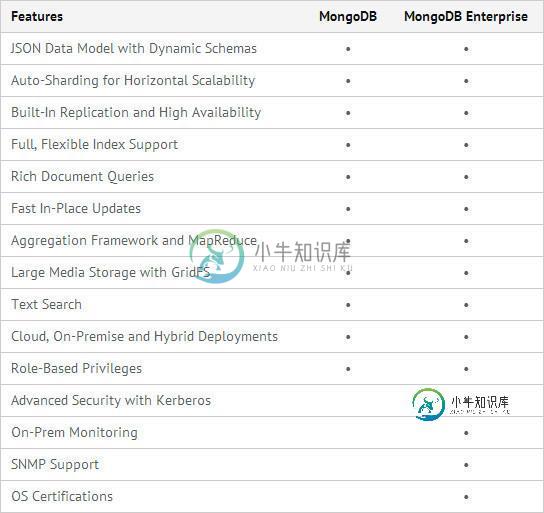 MongoDB社区版和企业版的差别对照表
MongoDB社区版和企业版的差别对照表本文向大家介绍MongoDB社区版和企业版的差别对照表,包括了MongoDB社区版和企业版的差别对照表的使用技巧和注意事项,需要的朋友参考一下 MongoDB社区版本和企业版本差异主要体现在安全认证、系统认证等方面,具体信息参考下表: 版本特性 社区版本 企业版本 JSON数据模型、自由模式 支持 支持 水平扩展的自动分片功能 支持 支持 内置副本以及高可用性 支持 支持 完整的、可扩展的索引支撑
-
Azure Web应用能否仅由Azure Web作业组成
我正在开发一个需要许多连续运行的web作业的解决方案。出于隔离和性能的原因,我不想将这些应用程序与我们产品中的任何Web应用程序打包。我想可能涉及到Azure开发人员的一些工作,但我的问题是,我是否必须创建没有代码的Web应用程序,比如天气预报类型的项目,以便部署我的Web作业。
-
如何在YARN Spark作业中设置环境变量?
问题内容: 我试图访问Accumulo 1.6 从Apache的星火使用的作业(Java编写的)用。为了做到这一点,我必须通过调用该方法来告知在哪里定位ZooKeeper 。此方法采用一个对象,该对象指定各种相关属性。 我通过调用静态方法来创建对象。该方法应该在各个位置查找文件以从中加载其默认值。它应该看的地方之一是。 因此,我试图以这样的方式设置环境变量,使其在Spark运行作业时可见(作为参考
-
大O符号作业-代码片段算法分析?
问题内容: 对于作业,我得到了以下8个代码段,以分析并给出运行时间的Big-Oh表示法。有人能告诉我我走的路是否正确吗? 我在想片段1的O(N) 片段2也为O(N) 片段3的O(N ^ 2) 片段4的O(N) 片段5的O(N ^ 2),但是n * n让我有点失望,所以我不太确定 片段6也为O(N ^ 2) 片段7的O(N ^ 3),但n * n再次让我失望 片段8的O(N) 问题答案: 我认为片段
-
石英:在Jobs.xml中阻止作业的并发实例
问题内容: 这应该真的很容易。我使用的是在Apache Tomcat 6.0.18下运行的Quartz,我有一个jobs.xml文件,该文件设置了每分钟运行的计划作业。 我想做的是,如果下一个触发时间到来时该作业仍在运行,则我不想启动新作业,因此可以让旧实例完成。 有没有办法在Jobs.xml中指定此设置(防止并发实例)? 如果不是,是否可以共享我的应用程序Job实现中对内存中单例的访问(这是通过
-
截止日期为空的作业意味着什么?
问题内容: 我使用以下SQL列出了没有停止日期的所有作业。我以为我可以用它来找到所有活跃的工作。我注意到的是,此表中有许多作业,且stop_execution_date为空。此表中多次重复某些相同的作业(相同的job_id)。 当我在这些作业上运行时,我看到它们的当前执行状态是空闲的。 这些工作代表什么?如果未正确杀死工作,这是行为吗? 问题答案: 每次启动SQL Agent时,它将在sysses
-
CUPS在仍在打印的作业上返回“完成”
我正在使用IPP协议与CUPS通信。我的打印机的所有驱动程序都安装在CUPS中(使用.ppd文件),打印机得到了最新的固件。 当我查询一个打印机正在打印的作业时,它表示该作业的状态在打印机完成打印之前就已经“完成”。CUPS似乎在完成文件“上传”后将作业标记为“完成”。 我不希望出现这种行为,我基本上需要知道打印机何时打印出作业的最后一张纸。代码如下所示。自身。打印机()。ippPrinter()
-
运行Spark流作业时出现序列化问题
无法解决以下由)触发的序列化问题。我认为可以解决序列化问题,但事实并非如此。那么,如何使用? 我假设变量和是不可序列化的,但是我如何正确地序列化它们,以便代码能够在集群上工作,而不仅仅是在本地工作呢? 上面显示的代码抛出错误:
-
使用mockito初始化spring批处理作业执行
问题: 我正在为我的一个spring批处理作业方法编写单元测试。我使用mockito来模拟我的批处理作业依赖关系。在jobExecution发挥作用之前,一切都很好。我要测试的方法调用了jobExecution变量,但它给了我NPE(NullPointerException)并且我没有成功地用mockito模拟它。 删除此currentJobExecution时 从我要测试的方法,然后测试成功完成
-
在一个闪烁作业中使用收集()和env.execute()
我试图在Flink中编写一个需要两个阶段的计算。 在第一阶段,我创建一个Graph并获取它的顶点id: 在第二阶段,我想使用这些ID为每个顶点运行SingleSourceShortestPath。 它在本地工作(在IntelliJ IDE和命令行中使用),但当我使用其WebUI在Flink上提交作业时,程序只是执行直到方法并且不运行程序的剩余部分(用于语句和)。 问题是什么? 这是我的代码:
-
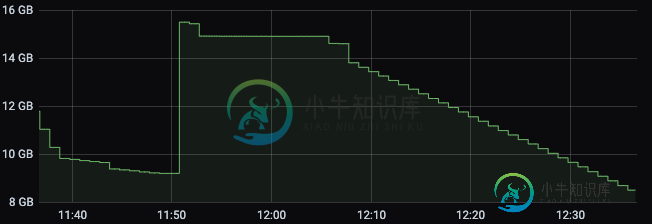 运行Apache Flink作业时K8s群集内存减少
运行Apache Flink作业时K8s群集内存减少我们正在尝试在K8s集群上部署apache Flink作业,但我们注意到一个奇怪的行为,当我们开始我们的作业时,任务管理器内存以分配的数量开始,在我们的例子中是3 GB。 最终,内存开始减少,直到达到约160 MB,此时,它会恢复一点内存,所以不会达到其极限。 这种非常低的内存通常会导致作业因任务管理器心跳异常而终止,即使在尝试查看Flink仪表板上的日志或执行作业流程时也是如此。 为什么它的内存