《2022毕业即失业取暖地》专题
-
如何定期安排flink批次处理作业
我有一个java应用程序,它对通过查询数据库中的表获得的批进行flink批处理,并将其输入kafka主题。我将如何定期安排这项工作。有flink调度程序吗?例如,我的java应用程序应该在后台持续运行,flink调度程序应该定期从数据库查询表,flink批处理它并将其输入kafka(flink批操作和输入Kafca已经在我的应用程序中完成了)。如果有人有这方面的建议,请帮忙。
-
Quartz调度程序-允许并行作业执行
我正在使用Quartz调度器,但我不知道如何并行运行作业。配置文件中有什么东西可以允许我这样做吗?
-
Quartz调度程序:群集-作业执行两次
我有一个使用Quartz1.6.6的Java应用程序。它被部署到Weblogic上,Weblogic的体系结构包括两个应用服务器。 令人困惑的是,我有另一个Java应用程序,其中包含了Quartz调度,它似乎运行得非常愉快。另一个应用程序有一个相同的机制,每分钟触发一个触发器,从日志中我可以看到该作业每60秒只运行一次。 昨天下午作业已运行的次数示例: 15:10:46,984 15:10:49,
-
Jenkins - 从下游作业访问存档的工件
我对 jenkins (2.74) 在归档 maven 项目中的工件时究竟在做什么有点困惑。从日志中可以看出,jenkins 正在自动存档项目中的工件,而无需指定生成后操作。工件文件确实在
-
断开连接后重试AWS IoT作业执行
我有一个设备可以做一些工作。例如,下载一些文件。在作业执行时,连接可能会丢失,需要重试下载。是AWS IoT上的某些机制提供了重试作业执行的可能性吗?或者如何通过aws SDK重试作业执行?
-
如何使用cron作业localhost在Windows与Laravel 5
我在这里找到了这篇文章:在PHP脚本上运行Cron作业,在Windows中的localhost运行完美。我想运行一个URL而不是PHP文件,就像http://localhost/test-cron-job 我试图简单地改变这一行: 为此: 但它根本不起作用。我能做些什么来使它工作?
-
成批缩松作业纱线簇的低性能
aws上的3台机器(32个内核和64 GB内存) 我手动安装了带有hdfs和yarn服务的Hadoop2(没有使用EMR)。 机器#1运行hdfs-(NameNode&SeconderyNameNode)和yarn-(resourcemanager),在masters文件中定义 问题是,我认为我做错了,因为这项工作需要相当多的时间,大约一个小时,我认为它不是很优化。 我使用以下命令运行flink:
-
如何模块化配置spring批处理作业?
我希望在我的应用程序中定义多个,并尝试将它们模块化,如下所示: 从sysout中,我可以看到创建了两个作业bean。 那么为什么找不到读者呢?我的意思是:除了将bean方法本身命名为,并将其注入变量名之外,我还能做些什么呢? SideNote:当我删除模块化并在上使用时,job运行良好。所以我很确定作业和阅读器的配置应该是正确的。但是当然我不能在下面运行类似的jobclass,所以我希望启用模块化
-
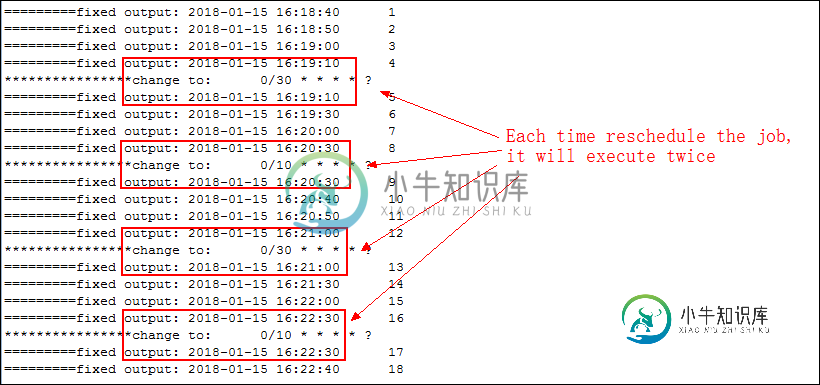 Spring Quartz重排作业第一次执行两次
Spring Quartz重排作业第一次执行两次我使用Quartz1.5.2和Spring3.2.1来做调度器任务,在我的应用程序中,我需要在某个时候重新安排任务,但我发现每次重新安排任务时,它都会在第一次执行两次。 下面是我的Quartz+Spring配置文件: 我把它作为一个web应用程序,下面是web.xml的代码:
-
Spring Security性和企业LDAP身份验证错误
我使用Spring Security(基本身份验证)+LDAP身份验证,这与嵌入式测试ldif很好,但与我的域LDAP不一样。但是,我可以使用LDAP浏览器/编辑工具使用相同的筛选器搜索我的帐户(SAMAccountName=NAPO) 错误消息为:LDAP:错误代码32-0000208D:Nameerr:DSID-0310020A,problem 2001(NO_OBJECT)
-
Spring批处理管理和启动主/从作业
是否可以配置Spring批处理管理员来启动主作业和从作业。我们有一个进程作为主节点和3-4个从节点。 Spring batch admin在单独的JVM进程中运行,但所有Spring批处理作业都使用相同的批处理数据库模式。
-
Google Cloud上的Apache Beam作业停滞-CPU过高
我们正在尝试调试运行在Google Cloud上的一个看似部分停顿的Apache Beam作业。我们的工作从PubSub读取消息,以各种方式对其进行转换,并将结果流式传输到几个BigQuery表。部分工作仍然是活动的-我们的几个表正在更新。但其他部分似乎停滞不前,上一次数据库表更新是在许多小时前(2:35AM)。不幸的是,我们在日志中没有看到有用的异常。我们只有少量用户生成的日志消息,每分钟发出一
-
使用struts和hibernate的Dao层和业务逻辑
我有一个struts项目,我的客户给了我完整的业务逻辑类。他需要这个忘恩负义的人,昂首阔步,冬眠。 哪一种最好,要将业务逻辑放到我的Dao层,需要为业务逻辑添加一个附加的服务层。 一些strut项目我发现动作类直接访问道。 请建议我哪个更好choice.help高度赞赏。 谢谢,
-
调度程序作业记录的分发处理
我正在研究一个用例,其中我安排了一个cron作业(通过石英),它从数据库中读取某些条目并处理它们。现在,在每个计划中,我可以获得数千条需要处理的记录。处理每条记录需要时间(以秒/分钟为单位)。目前,所有这些记录都在单个节点(由quartz选择的节点)上进行处理。现在,我面临的挑战是并行化这些记录处理。请帮助我解决以下问题: 如何将这些记录/任务分发到计算机群集 如果任何计算机在处理少量记录后发生故
-
如何将Flink作业与Guava缓存并行化?
我写了一份使用番石榴缓存的Flink作业。缓存对象是在main()函数中调用的run()函数中创建和使用的。 它类似于: 如果我以某种程度的并行性运行这个Flink作业,所有并行任务是否都将使用相同的缓存对象?如果没有,如何使它们都使用单个缓存? 缓存用于流的进程()函数内部。所以这就像 您可以将我的用例视为基于缓存的重复数据消除,因此我希望所有并行任务都指向单个缓存对象