《内存》专题
-
内存不足错误:Android Studio上的Java堆内存
问题内容: 编译Android项目时如何解决? 升级到Android Studio版本1后,我得到了这个。但是,我不认为这是问题所在。当我开始将应用程序升级到SDK 21之前(这是在SDK 20之前)的可能性最大。但是我也不是很确定。 我在Google周围搜索了一些 修复程序,但找不到可行的解决方案。大多数修复是针对Eclipse IDE的。 这是编译时遇到的完整logcat错误: 是因为我使用了
-
Java使用的内存比分配的内存更多
问题内容: 使用以下Java选项启动Apache Tomcat(Atlassian Confluence)实例: 但是,我看到启动后,它很快就耗尽了虚拟服务器上可用的1GB内存中的大部分。 总消耗的内存(堆+ PermGen)是否不应该保持在使用- Xmx指定的值以下?这引起的问题之一是我无法使用关闭脚本关闭服务器,因为它试图生成具有256MB内存的JVM,该JVM因不可用而失败。 问题答案: T
-
使用malloc分配的内存超过现有内存
问题内容: 每次从stdin读取字母“ u”时,此代码段将分配2Gb,并且在读取“ a”后将初始化所有分配的字符。 我在具有3Gb内存的linux虚拟机上运行此代码。在使用htop工具监视系统资源使用情况时,我已经意识到malloc操作不会反映在资源上。 例如,当我仅输入一次“ u”(即分配2GB的堆内存)时,我看不到htop中的内存使用量增加2GB。只有当我输入“ a”(即初始化)时,我才会看到
-
MySQL内存及虚拟内存优化设置参数
本文向大家介绍MySQL内存及虚拟内存优化设置参数,包括了MySQL内存及虚拟内存优化设置参数的使用技巧和注意事项,需要的朋友参考一下 mysql 优化调试命令 1、mysqld --verbose --help 这个命令生成所有mysqld选项和可配置变量的列表 2、通过连接它并执行这个命令,可以看到实际上使用的变量的值: mysql> SHOW VARIABLES; 还可以通过下面的语句看
-
简述JAVA中堆内存与栈内存的区别
本文向大家介绍简述JAVA中堆内存与栈内存的区别,包括了简述JAVA中堆内存与栈内存的区别的使用技巧和注意事项,需要的朋友参考一下 Java把内存划分成两种:一种是栈内存,一种是堆内存。 一、栈内存 存放基本类型的变量,对象的引用和方法调用,遵循先入后出的原则。 栈内存在函数中定义的“一些基本类型的变量和对象的引用变量”都在函数的栈内存中分配。当在一段代码块定义一个变量时,
-
内存有效的内置SqlAlchemy迭代器/生成器?
问题内容: 我有一个〜10M记录的MySQL表,可以使用SqlAlchemy进行交互。我发现对这个表的大子集的查询将消耗过多的内存,即使我以为我使用的是内置生成器,它可以智能地获取数据集的一口大小的块: 为了避免这种情况,我发现我必须构建自己的迭代器,该迭代器会分块地进行处理: 这是正常的还是关于SA内置发电机我缺少什么? 这个问题的答案似乎表明内存消耗是不希望的。 问题答案: 大多数DBAPI实
-
内存泄漏和内存溢出有什么区别
本文向大家介绍内存泄漏和内存溢出有什么区别相关面试题,主要包含被问及内存泄漏和内存溢出有什么区别时的应答技巧和注意事项,需要的朋友参考一下 内存泄漏是分配的内存无法释放,导致一直占用内存空间,最终可能引发内存溢出 内存溢出是申请或使用内存超出可以分配的内存时(例如往一个整形空间存放长整形的数据) 参考文章
-
为什么不允许从内存到内存的movl?
为什么会这样?最后,还有其他类似的功能我应该知道是不允许的。
-
从内核线程为用户空间分配内存
问题内容: 我的问题是关于将数据从内核传递到用户空间程序。我想实现一个系统调用“ get_data(size,char * buff,char ** meta_buf)”。在此调用中,buff由用户空间程序分配,并且其长度在size参数中传递。但是,meta_buf是可变长度的缓冲区,已分配(在用户空间程序的vm页面中)并由内核填充。用户空间程序将释放该区域。 (我无法在用户空间中分配数据,因为用
-
虚拟内存和缓存内存之间的区别
本文向大家介绍虚拟内存和缓存内存之间的区别,包括了虚拟内存和缓存内存之间的区别的使用技巧和注意事项,需要的朋友参考一下 在计算机环境中,内存是至关重要的部分,因为它是唯一负责系统性能和系统存储容量的部分。众所周知,内存负责任何应用程序的加载和执行,还用于存储其数据,以后可被其使用,因此在加载或安装应用程序之前了解系统的内存配置非常重要。 现在,在本主题中基本上将要讨论的是两种类型的存储器,即虚拟存
-
java内存泄漏与内存溢出关系解析
本文向大家介绍java内存泄漏与内存溢出关系解析,包括了java内存泄漏与内存溢出关系解析的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了java内存泄漏与内存溢出关系解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memor
-
脚本使用JVM的堆内存或系统内存
我的问题是,如果我从java代码调用Shell脚本,脚本使用的内存,是从JVM堆空间分配,还是使用系统内存空间。
-
将 EhCache 磁盘存储内容加载到内存中
如EhCache留档所述: 实际上,这意味着持久性内存中缓存将启动,其所有元素都将在磁盘上。[...]因此,Ehcache设计不会在启动时将它们全部加载到内存中,而是根据需要懒惰地加载它们。 我希望内存缓存启动时将所有元素都存储在内存中,我该如何实现? 这是因为我们的网站对缓存执行了大量的访问,所以我们第一次访问网站时,它的响应时间非常长。
-
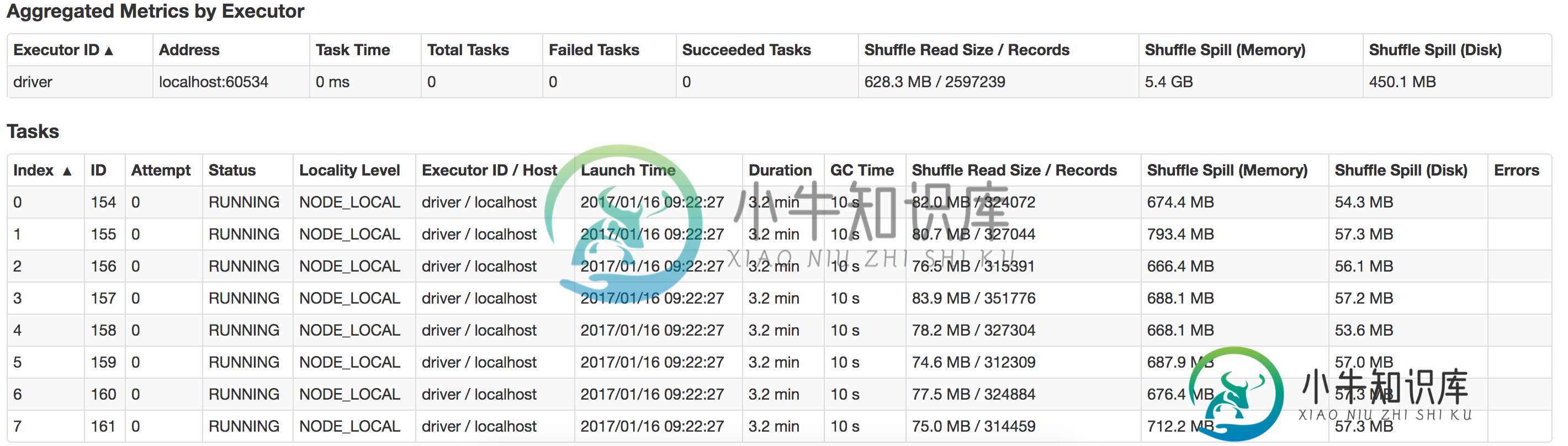 火花驱动程序内存和执行器内存
火花驱动程序内存和执行器内存我是Spark的初学者,我正在运行我的应用程序,从文本文件中读取14KB的数据,执行一些转换和操作(收集、收集AsMap),并将数据保存到数据库 我在我的macbook上本地运行它,内存为16G,有8个逻辑核。 Java最大堆设置为12G。 这是我用来运行应用程序的命令。 bin/spark-submit-class com . myapp . application-master local[*
-
从内存流中提取(字符串)文件内容
我有一个位于Azure Data Lake Store上的文件,我正在编写一个apiendpoint以将该文件的内容作为字符串检索。我遇到的问题是,当我尝试读取流时,我得到一个空字符串。这是我正在使用的: 目前,返回文件的响应工作正常,我可以在PC上打开文件并读取其内容。使用StreamReader返回文件内容的响应返回空字符串。