《内存》专题
-
具有映射内存、统一虚拟寻址和统一内存的GPU内存超额订阅
我正在考虑在GPU上处理数据的可能性,这对于GPU内存来说太大了,我有几个问题。 在CUDA 6.0中,UM不允许超额订阅GPU内存(并且通常不允许分配比GPU拥有的内存更多的内存,即使在主内存中也是如此),但是在CUDA 8.0中,这是可能的(https://devblogs.nvidia.com/parallelforall/beyond-gpu-memory-limits-unified-m
-
NewStringUTF()和释放内存
问题内容: 我应该在将分配的字符串传递给之后释放它吗? 我有一些类似的代码: 在将字符串传递给之后释放字符串时,出现错误。如果我删除呼叫,该错误消失。我究竟做错了什么? 我看到矛盾的意见。有人说我应该自己释放它,有人说VM释放它,有人说VM不释放它,而您应该用奇怪的巫术魔术来释放它。我很困惑。 问题答案: 参数to 的存储完全由您负责:如果您分配了,则需要它。因此,您发布的代码段是正确的。您正在其
-
Java neo4j,REST和内存
问题内容: 我已经在Jersey tomcat下使用Neo4j Java嵌入式版本针对REST API部署了一个应用程序。通过使用jconsole测量内存使用情况,我注意到每个REST调用都会增加200Mb的内存(我认为这是因为整个图形都已加载到内存中)。因此,仅用5个调用,服务器便分配了1Gb的内存!要清理内存,我必须等待垃圾收集器(阈值设置为1Gb)。 这是因为我使用的是neo4j java嵌
-
快速管理内存
问题内容: 该问题已清除,重要信息移至下面的答案。 我对内存管理有一些疑问。 我正在构建照片编辑应用程序。因此,保持较低的内存使用量很重要。另外,我不打算发布代码,因为在做一件特定的事情时,我不会发生大的内存泄漏。我将所有发生的一切都丢失了几KB / MB。遍历数万行代码以查找千字节并不有趣;) 我的应用使用了核心数据,许多cifilter内容,位置和基础知识。 我的第一个视图只是一个表视图,它占
-
Node.js堆内存不足
问题内容: 今天,我运行了用于文件系统索引编制的脚本,以刷新RAID文件索引,并在4小时后崩溃并出现以下错误: 服务器配备16GB RAM和24GB SSD交换。我非常怀疑我的脚本是否超过了36gb的内存。至少不应该 脚本使用文件元数据(修改日期,权限等,无大数据)创建存储为对象数组的文件索引 过去,我曾经用此脚本经历过奇怪的节点问题,这使我不得不这样做。在处理诸如String之类的大文件时,由于
-
内存有效方式
问题内容: 我有两个用Go编写的类似程序的示例。该代码的主要目的是使用结构中的值对结构进行排序。 指针示例 有值的例子 我想知道2分钟: 哪个示例将提高内存效率?(我想这是一种指针方式) 如何使用地图中具有不同数量结构的测试数据来衡量这些示例的性能?您能帮我建立基准吗? 我认为地图中每个结构的大小平均在1-2kB之间。 问题答案: “高效内存”是一个相当宽泛的术语,在诸如Go之类的垃圾收集语言中,
-
Tensorflow GPU内存分配
我正在尝试使用我的GPU而不是CPU来训练一个自定义的对象检测模型。我遵循了以下教程中给出的所有说明:https://tensorflow-object-detection-api-tutorial.readthedocs.io/ 我已经测试了我的软件,一切都已安装并正常工作。 目前正在使用: Windows 10 但问题是,在训练几秒钟后,它停止使用GPU,并发出以下警告消息。 此外,我没有在我
-
 内存管理简介
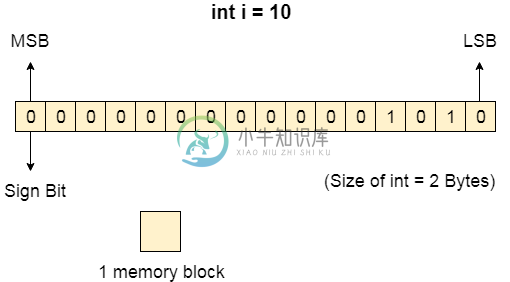
内存管理简介主要内容:什么是内存?,数据如何存储在计算机系统中?,需要多种编程什么是内存? 计算机内存是以二进制格式表示的一些数据的集合。 在各种功能的基础上,内存可以分为不同的类别。 稍后我们将详细讨论它们。 能够暂时或永久存储任何信息或数据的计算机设备称为存储设备。 数据如何存储在计算机系统中? 要理解内存管理,我们必须清楚如何将数据存储在计算机系统中。 机器只能识别0或1的二进制语言。计算机会先将每个数据转换为二进制语言,然后将其存储到内存中。 这意味着如果我们有一个
-
 Objective-C内存管理
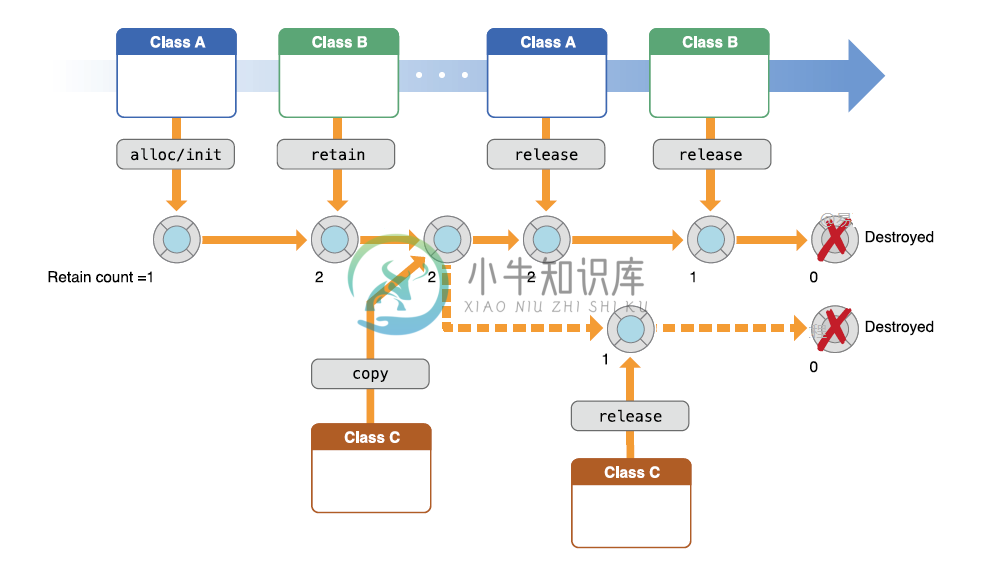
Objective-C内存管理主要内容:1. “手动保留释放”或MRR,2. MRR基本规则,3. “自动参考计数”或ARC内存管理是任何编程语言中最重要的过程之一。它是在需要时分配对象的内存并在不再需要时取消分配的过程。 管理对象内存是一个性能问题; 如果应用程序不释放不需要的对象,则应用程序会因内存占用增加并且性能受损。 Objective-C内存管理技术大致可分为两类 - “手动保留或释放”或MRR “自动参考计数”或ARC 1. “手动保留释放”或MRR 在MRR中,通过跟踪自己的对象来明确管理内存。这是使用一
-
分配内存指针
我想知道何时或是否必须删除此对象。下面是一个基本类对象Object.cpp的构造函数: 我知道在分配内存时,你应该在某个时候删除它,但是我在构造函数中分配了内存,并且想再次使用变量1和2,我什么时候删除它们?
-
Memory Management(内存管理)
内存管理子系统是操作系统的重要部分。从计算机发展早期开始,就存在对于大于系统中物理能力的内存需要。为了克服这种限制,开发了许多种策略,其中最成功的就是虚拟内存。虚拟内存通过在竞争进程之间共享内存的方式使系统显得拥有比实际更多的内存。 虚拟内存不仅仅让你的计算机内存显得更多,内存管理子系统还提供: Large Address Spaces (巨大的地址空间)操作系统使系统显得拥有比实际更大量的内存。
-
2.7 CGO内存模型
CGO是架接Go语言和C语言的桥梁,它使二者在二进制接口层面实现了互通,但是我们要注意因两种语言的内存模型的差异而可能引起的问题。如果在CGO处理的跨语言函数调用时涉及到了指针的传递,则可能会出现Go语言和C语言共享某一段内存的场景。我们知道C语言的内存在分配之后就是稳定的,但是Go语言因为函数栈的动态伸缩可能导致栈中内存地址的移动(这是Go和C内存模型的最大差异)。如果C语言持有的是移动之前的G
-
golang websocket内存泄漏
我们有一个基于go-socket.io(socket.ioGo语言实现)和大猩猩网络插座的网络插座服务,但是似乎有内存泄漏问题。即使我使用调试,HeapAlloc也总是在增加。FreeOSMemroy强制释放内存。 服务很简单。它将使用jwt令牌对传入请求进行身份验证,如果身份验证成功,则将创建一个go套接字。io conn基于gorilla websocket conn。但现在似乎是net/te
-
强制清除内存
我的项目遇到了一些内存问题,所以我决定对一些部分进行压力测试,以查看一些性能度量。我正在使用Google的ConcurrentLinkedHashMap库作为LRU内存缓存。我的测试代码的相关部分如下所示: 当内存超过50%时,我将throttle(油门)标志设置为true(真)。我有一个监视线程,它每2秒进行一次测量。以下是我得到的数字: 由于某种原因,我没有看到LRU缓存的
-
PyTorch GPU内存不足
我正在PyTorch中运行一个评估脚本。我有许多经过训练的模型(*.pt文件),我将其加载并移动到GPU,总共占用270MB的GPU内存。我使用的批量大小为1。对于每个示例,我加载一个图像并将其移动到GPU。然后,根据样本,我需要运行一系列经过训练的模型。有些模型以张量作为输入和输出。其他模型的输入是张量,输出是字符串。序列中的最终模型总是有一个字符串作为输出。中间张量临时存储在字典中。当模型使用