《内存》专题
-
共享内存 - TableManager
EasySwoole对Swoole table进行了基础的封装。 方法列表 getInstance() 该方法用于获取TableManager管理器实例 add($name,array $columns,$size = 1024) 该方法用于创建一个table get($name):?Table 该方法用于获取已经创建好的table 示例代码 TableManager::getInstance()
-
共享内存 - shmdt
shmat是shared memory attach的缩写。而attach本意是贴的意思。 如果进程要使用一段共享内存,那么一定要将该共享内存与当前进程建立联系。即经该共享内存挂接(或称映射)到当前进程。 shmdt则是shmat的反操作,用于将共享内存和当前进程分离。在共享内存使用完毕后都要调用该函数。 函数原型 #include <sys/types.h> #include <sys/shm.
-
共享内存 - shmctl
共享内存的控制 函数原型 #include <sys/ipc.h> #include <sys/shm.h> int shmctl(int shmid, int cmd, struct shmid_ds *buf); 参数 shmid 由shmget函数生成,不同的key值对应不同的id值。 cmd 操作字段,包括: 公共的IPC选项(ipc.h中): IPC_RMID //删除 IPC_SET
-
共享内存 - shmget
创建共享内存,通过key返回id。 函数原型 #include <sys/ipc.h> #include <sys/shm.h> int shmget(key_t key, size_t size, int shmflg); 参数 key 不消多说 size 欲创建的共享内存段的大小 shmflg 共享内存段的创建标识: 公共的IPC选项(在/usr/include/linux/ipc.h中定义)
-
4 虚拟内存
处理器的虚拟内存子系统为每个进程实现了虚拟地址空间。这让每个进程认为它在系统中是独立的。虚拟内存的优点列表别的地方描述的非常详细,所以这里就不重复了。本节集中在虚拟内存的实际的实现细节,和相关的成本。 虚拟地址空间是由CPU的内存管理单元(MMU)实现的。OS必须填充页表数据结构,但大多数CPU自己做了剩下的工作。这事实上是一个相当复杂的机制;最好的理解它的方法是引入数据结构来描述虚拟地址空间。
-
4.2 内存对齐
当目标指令集为x86/x64时,未对齐的内存读写不会导致错误的结果;而在Emscripten环境下,编译目标为asm.js与WebAssembly时,情况又各有不同。 info 这里“未对齐”的含义是:欲访问的内存地址不是欲访问的数据类型大小的整数倍。 4.2.1 asm.js C代码如下: //unaligned.cc struct ST { uint8_t c[4]; float f; }
-
3.4 内存管理
第2章我们介绍了Emscripten使用的线性内存模型,以及C/C++代码和JavaScript代码通过Emscripten堆交换数据的方法。本节将介绍Emscripten堆(既内存)管理的相关内容。 3.4.1 内存容量/栈容量 Emscripten当前版本(v 1.38.11)默认的内存容量为16MB,栈容量为5MB。 在使用emcc编译时,可以使用TOTAL_MEMORY参数控制内存容量,例
-
Java-内存模型
规范了Java虚拟机与计算机内存是如何协调工作的,规定了一个线程如何及何时能看到其他线程修改过的共享变量,在必须时如何同步地访问共享变量,控制线程本地内容和共享内容之间的同步。 2. 同步八种操作 操作 定义 lock(锁定) unlock(解锁) read(读取) load(载入) use(使用) assign(赋值) store(存储) write(写入) 3. 同步规则 Read和Load之
-
指针与内存
内存32位和64位的区别 ///01.Point.c #include <stdio.h> #include <stdlib.h> //01.指针变量所占用的内存尺寸由编译器进行直接决定 // 指针变量所占用的内存尺寸同时直接或间接与CPU-->操作系统-->编译器平台有关 // 综合决定:CPU-->操作系统-->编译器平台 // 直接决定:编译器
-
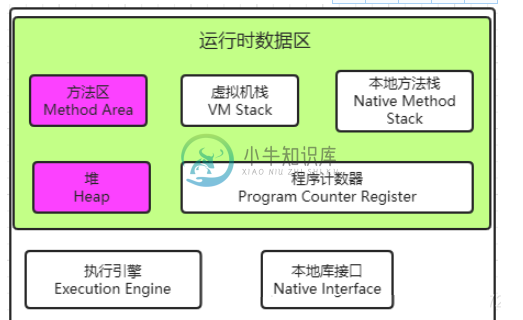 JVM内存结构
JVM内存结构主要内容:1.运行时数据区,3.Java堆,4.方法区(Method Area)1.运行时数据区 运行时数据区 Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分为若干个不同的数据区域。每个区域都有各自的作用。 分析 JVM 内存结构,主要就是分析 JVM 运行时数据存储区域。JVM 的运行时数据区主要包括:堆、栈、方法区、程序计数器等。而 JVM 的优化问题主要在线程共享的数据区中:堆、方法区。 1. 程序计数器 程序计数器(Program Counter
-
内存DB管理
主要内容:一、数据库DB,二、源码分析,三、总结一、数据库DB REDIS是一款内存型数据库,那么数据的最终处理是如何处理的呢,前面提到了数据的挺久化,那么持久化的什么内容,其实就是数据的处理过程。也就是说,持久化的数据也就是Redis需要操作的数据,这些数据才是它真正有用的部分,前面提到的一切一切,甚至以后再提到的一切一切,其实都是为这些数据服务的,保证这些数据的安全、高效和稳定。 REDIS的所有数据都存储在redisDb这个数据结构体中,
-
TT内存清理
因为自己的手机比较卡,所以就想写个小工具改善一下手机卡顿的情况,既然写了就又顺手写点自定义的View,最后又顺手把它上线了,其实基本没什么人下载,现在把原来项目的友盟数据统计和有米广告去掉了开源出来给大家看看。 apk下载:http://zhushou.360.cn/detail/index/soft_id/2366842 开源地址:http://git.oschina.net/cocobaby/
-
display:block内部显示:内联
问题内容: 我想了解当CSS是CSS元素的DOM子元素(因此block元素是inline元素的子元素)时会发生什么情况。 CSS 2.1规范的“ 匿名块框”部分描述了这种情况:该示例包括以下规则… …以及随附的文字说… BODY元素包含一个匿名文本块(C1),然后是一个块级元素,然后是另一个匿名文本块(C2)。结果框将是围绕BODY的匿名阻止框,其中包含C1周围的匿名阻止框,P阻止框和C2周围包含
-
内容库 - 渲染内容
使用步骤 下载 小程序内容渲染包 wxParser 把 wxParser 目录放到小程序项目的根目录下 在需要富文本解析的的 WXML 内引入 wxParser/index.wxml 在页面 JS 文件内使用 wxParser.parse(options) 方法解析 HTML 内容 在需要展示富文本内容的页面的 wxss 文件内引入 wxParser 的默认样式库 wxParser/index.w
-
内容库 - 内容操作
{% tabs first=”SDK 1.1.3 及以上版本”, second=”SDK 1.1.3 以下版本” %} {% content “first” %} SDK 1.1.3 及以上版本 以下操作都需指明操作的内容库,方法如下: let MyContentGroup = new wx.BaaS.ContentGroup(contentGroupID) 参数说明 参数 类型 必填 说明 co