《58集团》专题
-
集合视图是什么?
问题内容: 在使用Guava集合并阅读其文档时,我已经阅读了几次“术语 视图” 。 我一直在寻找一种解释,说明在这种情况下视图是什么以及它是否在Guava之外使用。在这里经常使用。番石榴的这种类型在其名称中具有 视图 。 我的猜测是,一个集合的视图是另一个具有相同数据但结构不同的集合。例如,当我将条目从a添加到后者时,将是前者的视图。那是对的吗? 有人可以给我链接到一个公认的 view 定义(如果
-
 DBMS群集文件组织
DBMS群集文件组织当两个或多个记录存储在同一文件中时,它称为群集。 这些文件在同一数据块中有两个或多个表,并且用于将这些表映射到一起的键属性仅存储一次。 该方法降低了在不同文件中搜索各种记录的成本。 当经常需要以相同条件连接表时,将使用群集文件组织。这些连接只会从两个表中提供几条记录。 在给定的示例中,仅检索指定部门的记录。此方法不能用于检索整个部门的记录。 在这种方法中,可以直接插入,更新或删除任何记录。 数据根
-
 测试集锁定机制
测试集锁定机制主要内容:汇编代码中的修改,TSL指令汇编代码中的修改 在锁变量机制中,有时Process读取锁变量的旧值并进入临界区。由于这个原因,多个流程可能会进入临界区。但是,下面第一部分中显示的代码可以用第二部分中显示的代码替换。这不会影响算法,但通过这样做,我们可以设法在一定程度上提供互斥,但不能完全实现。 在更新版本的代码中,Lock的值被加载到本地寄存器R0中,然后锁的值被设置为。 但是,在步骤3中,先前的锁定值(现在存储到R0中)与0
-
 Kafka群集体系结构
Kafka群集体系结构有关Kafka群集体系结构,请看下面的结构图。 它显示了Kafka的集群图。 下表描述了上图中显示的每个组件。 Broker - Kafka集群通常由多个代理组成,以保持负载平衡。 Kafka经纪人是无状态的,所以他们使用ZooKeeper维护他们的集群状态。 一个Kafka代理实例可以处理每秒数十万次的读写操作,每个Broker都可以处理TB消息,而不会影响性能。 Kafka经纪人的领导人选举可
-
Java9集合工厂方法
在Java 9中,新的工厂方法被添加到,和接口来创建不可变的实例。 这些工厂方法是便捷的工厂方法,以较简洁的方式创建集合。 旧的方式创建集合 执行上面示例代码,得到以下结果 - 新方法 使用java 9,以下方法将被添加到,和接口以及它们的重载对象。 注意事项 对于和接口,方法重载为到个参数,另一个使用参数。 对于接口,方法重载为有到个参数。 如果接口的参数超过个,则可以使用方法接受参数。 创建集
-
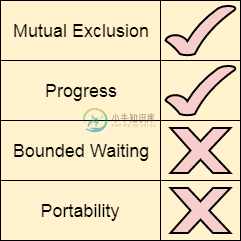
 并查集路径压缩
并查集路径压缩主要内容:UnionFind3.java 文件代码:并查集里的 find 函数里可以进行路径压缩,是为了更快速的查找一个点的根节点。对于一个集合树来说,它的根节点下面可以依附着许多的节点,因此,我们可以尝试在 find 的过程中,从底向上,如果此时访问的节点不是根节点的话,那么我们可以把这个节点尽量的往上挪一挪,减少数的层数,这个过程就叫做路径压缩。 如下图中,find(4) 的过程就可以路径压缩,让数的层数更少。 节点 4 往上寻找根节点时,压缩
-
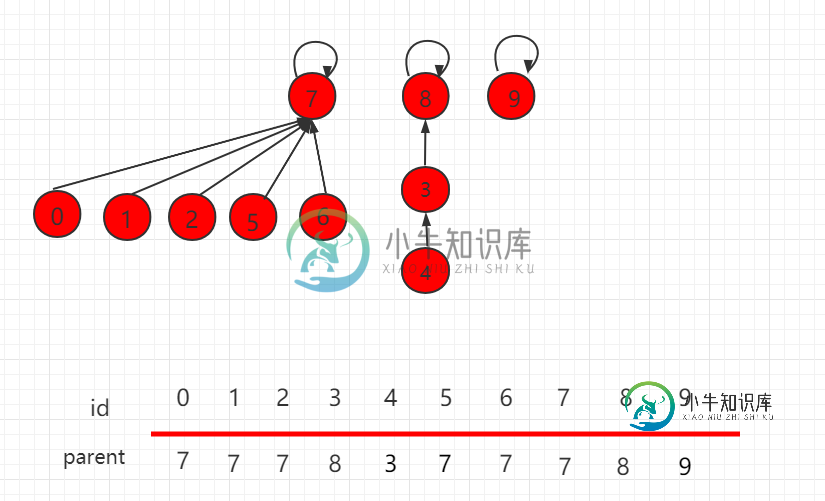 并查集 rank 的优化
并查集 rank 的优化主要内容:UnionFind3.java 文件代码:上一小节介绍了并查集基于 size 的优化,但是某些场景下,也会存在某些问题,如下图所示,操作 union(4,2)。 根据上一小节,size 的优化,元素少的集合根节点指向元素多的根节点。操完后,层数变为4,比之前增多了一层,如下图所示: 由此可知,依靠集合的 size 判断指向并不是完全正确的,更准确的是,根据两个集合层数,具体判断根节点的指向,层数少的集合根节点指向层数多的集合根节点,如下图
-
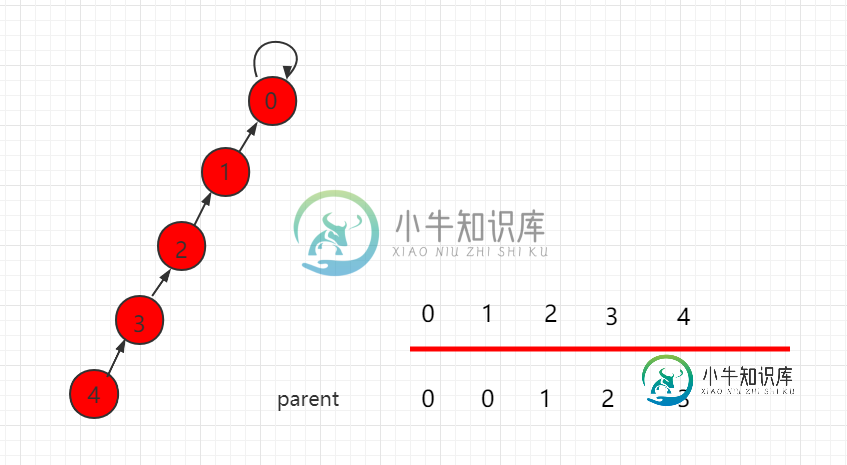
 并查集 size 的优化
并查集 size 的优化主要内容:UnionFind3.java 文件代码:按照上一小节的思路,我们把如下图所示的并查集,进行 union(4,9) 操作。 合并操作后的结构为: 可以发现,这个结构的树的层相对较高,若此时元素数量增多,这样产生的消耗就会相对较大。解决这个问题其实很简单,在进行具体指向操作的时候先进行判断,把元素少的集合根节点指向元素多的根节点,能更高概率的生成一个层数比较低的树。 构造并查集的时候需要多一个参数,sz 数组,sz[i] 表示以 i 为根的
-
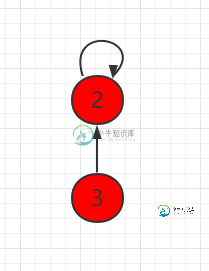 并查集快速合并
并查集快速合并主要内容:UnionFind2.java 文件代码:对于一组数据,并查集主要支持两个动作: union(p,q) - 将 p 和 q 两个元素连接起来。 find(p) - 查询 p 元素在哪个集合中。 isConnected(p,q) - 查看 p 和 q 两个元素是否相连接在一起。 在上一小节中,我们用 id 数组的形式表示并查集,实际操作过程中查找的时间复杂度为 O(1),但连接效率并不高。 本小节,我们将用另外一种方式实现并查集。把每一个元
-
并查集快速查找
主要内容:UnionFind1.java 文件代码:本小节基于上一小节并查集的结构介绍基础操作,查询和合并和判断是否连接。 查询元素所在的集合编号,直接返回 id 数组值,O(1) 的时间复杂度。 ... private int find ( int p ) { assert p >= 0 && p < count ; return id [p ] ; } ... 合并元素 p 和元素 q 所属的集合, 合并过程需要遍历一遍所有元素
-
Java foreach遍历Collection集合
《 Java Iterator遍历Collection集合元素》一节中主要讲解如何使用 Iterator 接口迭代访问 Collection 集合里的元素,除了这个方法之外,我们还可以使用 Java 5 提供的 foreach 循环迭代访问集合元素,而且更加便捷。如下程序示范了使用 foreach 循环来迭代访问集合元素。 输出结果为: 小牛知识库C++教程 小牛知识库C语言教程 小牛知识库Jav
-
无状态EJB和集群
场景:EjbA和EjbB都是远程无状态会话bean。 对b的这些方法调用中的任何一个都可以发生在集群环境中的不同节点/VM上,这是否正确? 甚至连对method1的调用? 我的意思是,如果一些客户端调用方法foo,是否会发生这样的情况:在这个事务中,在node1上调用方法1,下一个对方法1的调用,在同样的foo()调用期间,转到node2上的Ejb实例? 解释下面引用的"Enterprise Ja
-
spring oauth2和集成测试
需要对Oauth2客户端的集成测试的帮助。 设置: 具有受保护UI和API的客户端 完成所有密码验证并检索访问令牌的身份验证服务器 集成测试: 放心用于终点测试 在实现Oauth2之前,测试工作良好 Ole测试示例: 问题: 如何使此测试再次工作? 应如何更改res-assured设置以支持OAuth2? 是否需要模拟身份验证服务器,或者是否可以注入/mock安全上下文?
-
QueryDSL投影中的集合
我试图使用一个投影来从一个实体中提取数据,它有一些关系。然而。投影上的构造函数接受三个参数;一个集合,整数和另一个整数。如果没有这个集合作为参数,这一切都很好,但是一旦我添加了这个集合,我就开始得到SQL语法查询错误。 这里有一个我正在使用的例子... 下面是我正在使用的查询(不完全相同,因为这是我正在处理的问题的简化版本).... 所以,我想我的主要问题是,我如何将一个集合作为一个对象包含在投影
-
AWS Aurora群集endpoint用法
如果我使用带有2个读取副本的AWS Aurora MYSQL数据库,我需要使用不同的连接字符串进行读写,还是由集群endpoint为我路由流量?如果是这样的话,对于一个写得更少的应用程序来说,让读副本成为比主副本更大的实例(更强大)是否明智,因为它几乎不会被使用? 提前道谢。