《联通数科》专题
-
N个数的模级联N次
我今天在开发人员工作面试中遇到了以下场景,这是其中一个问题,也是我唯一没有回答的问题。 将数字串联N次,然后在2017年前计算他的模数。 例如:对于N=5,数字为55555,结果为Mod(55555 2017)=1096;对于N=10,数字为10101010101010,结果Mod(101010101010102017)=1197 现在我要计算的数字是58184241583791680。我得到的唯
-
从Java调用Kotlin内联函数
例外情况。kt: 在科特林: 它在kotlin中工作,函数是内联的。 但是当在Java代码中使用时,它就是不能内联,仍然是一个正常的静态方法调用(从反编译的内容中可以看出)。 像这样的东西:
-
Swagger中的关联数组(OpenApi 3.0.0)
我有一个API,它总是使用关联数组回答,其中只有一个条目包含包含最终结果的键“数据”。结果可以是一个对象或对象数组。这是API输出: 我怎样才能让swagger在文档中显示数据,即键的名称? 至于现在,我只得到大摇大摆的嵌套数组: 我需要数据键在从API返回时以swagger的形式显示。这可行吗?我还没有找到任何解决办法…:/ 我的yaml文件的部分内容: 任何帮助都将不胜感激:) 干杯
-
Spring数据JPA/Hibernate处理关联
我需要基于参数从实体中检索或不检索一些关联。在下面的示例中,只有在通过api传递参数时,我才需要获取记录列表。你能推荐一种使用hibernate/spring数据实现这一点的方法吗?我正在寻找最干净、最像spring数据的方法。 我的存储库是空的: 在我的服务中,我做了如下事情: 但我想做的是:
-
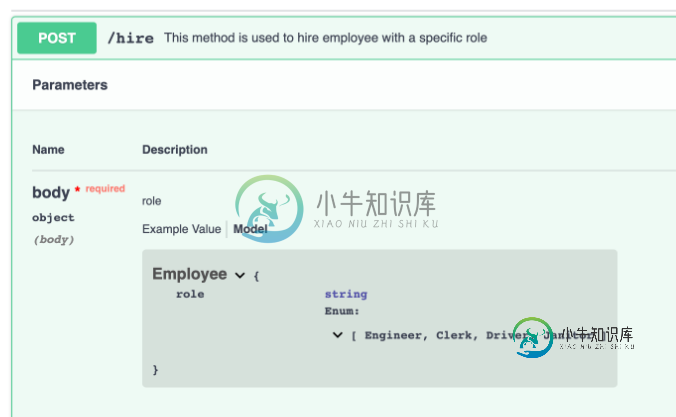 Swagger:将整数关联到枚举
Swagger:将整数关联到枚举我想在我的项目中包含swagger,但我不能更改代码或变量名称。 我有一个返回列表的服务: 代码变量来自枚举操作可能的错误: 是否可以将“代码”和TYPE枚举相关联,以便我可以在生成的swagger文档中显示选项列表? 谢谢
-
代码覆盖率内联函数
我有这个函数写在科特林 但是当我为此函数创建单元测试时,它在报告上显示0覆盖率。我正在使用jacoco进行代码覆盖。你们知道如何正确地对内联功能进行单元测试吗?谢谢!
-
 20221012银联数据面试(一面)
20221012银联数据面试(一面)20221012银联数据面试(一面) 写在前面:约的早上10:10,10:11开始面试,大搞20分钟结束,稍微有点卡,整体体验不错~在这里记录下 面试流程 自我介绍 SparkStreaming项目详说(说一半儿不让我说了,估计嫌烦) 问项目是不是事实项目,说不是,是练手的 问scala相关知识,问函数式编程优点,说了个简单,符合大数据的逻辑,没了,他问我还有没有?/捂脸,是真不知道了 问java
-
 招联金融-数据岗-面经
招联金融-数据岗-面经笔试(10.11) 岗位是数据开发,一道编程,几十道选择。难度不大,但涉及面挺广。 一面(10.15) 笔试完,隔天约面,效率很高。 项目介绍,自己的分工 特征选择方法 数据挖掘中对于缺失值的处理方案 说一下Python(pandas)中常用的数据处理算子。 Spark的原理,分布式是怎么搭建的。 Sql中union和union all的区别 数据行转列怎么操作 xgboost和gbdt的区别 x
-
 联想数据工程师面经
联想数据工程师面经实习生岗位,没有转正机会,本牛没有实习经历 1.自我介绍 2.介绍自己一个与数据分析相关的项目(介绍了期末project) 3.学习中掌握的数据分析技能有哪些(答了sql和python) 4.介绍一个学习中的困难以及是怎么克服的(很笼统地说了些学习中遇到的困难),面试官不满意,一定要我具体介绍某一个困境或者很suffer的经历 5.反问:该岗位还需要哪些能力,面试官答曰需要一双发现的眼睛,会探索的
-
通过pandas_gbq将bigquery google sheets联合数据源读取到云数据实验室时出现问题
这与这个问题非常相似——我有一个基本相同的问题,那里的一位评论员说他已经解决了这个问题,但没有具体说明这个问题。 我在google工作表中有数据,我将其设置为google BigQuery联合数据源(外部数据源) 我试图遵循马特在原始问题帖子中的说明:“我遇到了完全相同的问题,我必须为项目启用驱动应用编程接口(除了大查询应用编程接口之外),并使用大查询驱动范围。然后,我还必须手动许可这些工作表,以
-
通过查询优化MySQL计数/分组:仅显示与产品关联的类别
解释查询: 相关指标: 这是一个数据库,其中包含产品,类别以及它们之间的N:N关系。产品可以属于 1 个或多个类别。 我基本上需要一个查询来告诉我,对于我当前的产品过滤器(在这种情况下,状态和性别),该类别是否有任何产品(所以我可以隐藏没有产品的类别)。目前,我统计了每个类别中的产品,以了解这一点。 该查询中的参数将根据用户选择的过滤器而改变,因此该部分在该优化中不是非常重要。 我不需要一个类别的
-
 2023秋招—数据开发面经—联友科技
2023秋招—数据开发面经—联友科技面试岗位:数据库工程师 两个面试官,一个主要问知识点,另一个主要问实习、项目 介绍一下HDFS的写流程 Spark、Flink有哪些部署模式? Standlone和Yarn(Client、Cluster),会话模式、单作业模式、应用模式 有没有写过Flink平台的开发代码? Yarn由哪些角色组成?各自的任务是什么? Yarn的调度器有哪些? Hive和HBase的区别是什么? 项目中Kafka的
-
关联项 - 关联类型
使用“关联类型”可以增强代码的可读性,其方式是移动内部类型到一个 trait 作为output(输出)类型。这个 trait 的定义的语法如下: // `A` 和 `B` 在 trait 里面通过`type` 关键字来定义。 // (注意:此处的 `type` 不同于用作别名时的 `type`)。 trait Contains { type A; type B; // 通常
-
包含数组的Java spark数据帧联接列
我有两个数据帧df1和df2。df1有一个String类型的列键 当df1.key出现在df2.keys中时,我想连接2个数据帧 然而,我正在寻找一个完整的单词匹配。Contains方法连接部分匹配的行。我的意思是,在上面的示例中,我不希望k2与[pk1,pk2]连接,因为数组不包含密钥k2,它包含pk2。 有人能建议如何加入这个案子吗?请用JAVA提供示例。
-
当联接列不同时,使用Spark Scala动态联接数据流
在scala spark中连接不同数据帧时动态选择多列 从上面的链接,我能够让连接表达式工作,但如果列名不同,我们不能使用Seq(columns)而需要动态地连接它。这里的left_ds和right_ds是我想加入的数据流。下面我想要连接列id=acc_id和“acc_no=number”