《redis》专题
-
Amazon EC2到AWS Elasticache Redis的连接问题
我正在通过Redisson从Amazon EC2实例连接到AWS Elasticache Redis。在多次请求redis连接后,我遇到了以下问题,使我的程序无法执行。对于很少的redis交互请求,问题不会出现,但在大量请求之后,问题最终会发生。
-
Redis-cli连接到Amazon ElastiCache Redis集群挂断
我已经从源代码安装和编译了Redis,并试图连接到Amazon ElastiCache(Redis)集群。 我可以毫无问题地连接到默认的本地主机,但尝试连接到AWSendpoint会导致无限的挂起。 默认情况下: 现在,这是连接到endpoint的尝试,来自AWS留档主题的副本: 这会无限挂起,而不会向stderr/stdout发出任何消息。 (请注意,这是一个endpoint名称示例;我已验证我
-
django cacheops和aws redis加密
我已经在运输和Rest中使用EncOption设置了redis。我遇到过https://dev.to/yuki0417/easy-way-to-connect-to-amazon-elasticache-redis-with-password-from-django-app-40il并通过途中加密连接到AWS ElastiCache。因为我正在使用https://github.com/Suor/d
-
AWS Redis读卡器endpoint和ioredis
我们希望我们的Redis更具可扩展性,并且能够添加更多的读取实例。 我正在尝试使用此新的读卡器endpoint:https://aws.amazon.com/about-aws/whats-new/2019/06/amazon-elasticache-launches-reader-endpoint-for-redis 但是,我没有看到使用这种方法的任何简单或自动的方法,我可以设置哪个endpoi
-
如何确定Redis(启用群集模式)复制组中的主要endpoint
我们有一个群集Redis设置(引擎版本5.04),其中有三个节点组,每个节点组位于各自的AZ中,每个组包含三个节点,在传输和静止时启用加密。Stunnel是在bastion主机上配置的,它允许我运行bash脚本,以便在需要时(在升级应用程序期间)刷新每个主副本。 通过控制台应用最新的Redis软件补丁后,由于自动故障切换,每个节点组中的主要endpoint都发生了更改,我正在寻找确定新主要endp
-
使用ElastiCache redis服务器和密码解析服务器
我已经在Elastic Beanstalk上设置了一个工作解析服务器。我添加了一个AWS ElasticCache Redis服务器用于缓存,但我无法在使用密码时使连接工作,只有在没有密码的情况下。在我的解析服务器索引中。js文件,我在其中创建与Redis连接的新解析服务器,如下所示: 其中我的URL看起来像REDIS\u URL=clustercfg。xxxx年。xxxx年。use1.cache
-
从客户端(而不是redis-cli组件)使用中转加密身份验证连接到AWS ElastiCache
我正在尝试使用Ruby redis客户端和两个NodeJS客户端(node_redis或ioredis)中的任何一个连接到启用了传输中加密和身份验证的Amazon ElastiCache集群,并且遇到问题。对于所有三个客户端,一旦我连接,我就会立即抛出一个ECONNRESET错误,并且在连接重试发生时一次又一次。 我遵循了AWS文档,能够使用stunnel通过redis cli成功连接,但到目前为
-
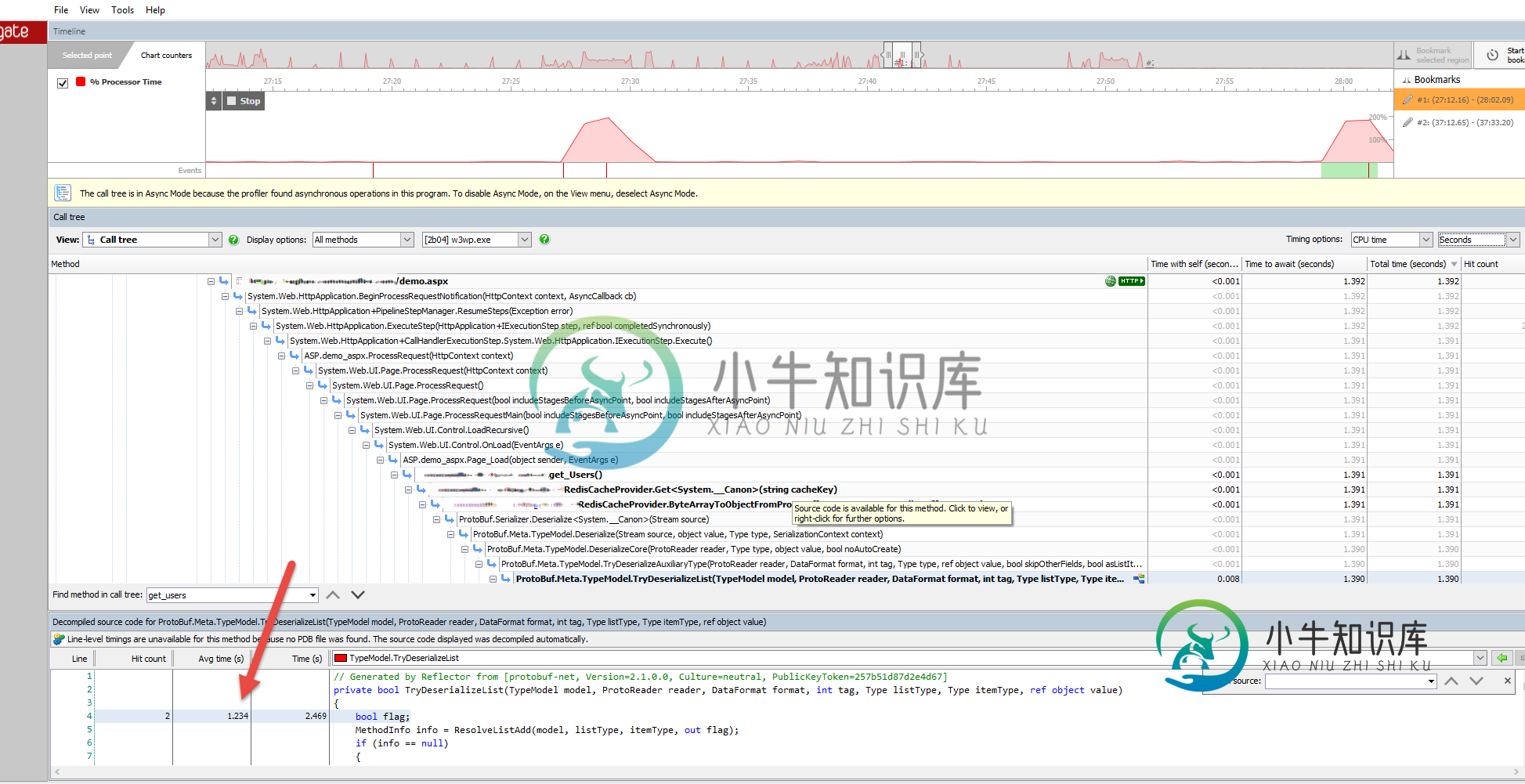 性能问题,同时反序列化大量的用户定义的对象从Redis通过协议bufnet
性能问题,同时反序列化大量的用户定义的对象从Redis通过协议bufnet问题:在对从Redis接收的字节进行反序列化时,性能变慢。 我正在使用REDIS在ASP中分发缓存。NET web应用程序。 为了从我的应用程序中与Redis进行对话,我正在使用StackExchange。Redis。 为了序列化/反序列化从/到DTO接收到/从服务器接收到/从服务器接收到的字节,我正在使用协议buf-net 我的目标是将一个包含100,000个用户的字典(字典(int, User
-
集群模式下的Redis流
Redis streams是否受益于群集模式?假设您有10个流,它们是分布在集群中还是全部分布在同一个节点上?我计划使用Redis streams实现真正的高吞吐量(每秒200万条消息),因此我担心Redis streams在这种规模下的性能。 如果Redis streams不能在集群模式下进行开箱即用的扩展,那么任何关于水平扩展Redis streams的指导都会非常棒。
-
redis在消费者群体内进行有序处理
我将python(aioredis)与redis streams一起使用。 我有一个一个生产者-多个(分组)消费者的场景,并希望确保消费者以有序的方式处理发送到流的(批量)消息,这意味着:当第一条消息完成时,处理流中的下一条消息,依此类推。这也意味着消费者组中的消费者在某一时间正在处理,而其他消费者将等待。 我还希望依赖于第二、第三等消费群体中的有序处理——所有这些都依赖于发送到一个流的相同消息。
-
redis图形与redis流的互操作性
我对这个项目很感兴趣,想了解更多关于RedisGgraph内部的信息,并寻找Redis-Streams和Redis-Ggraph模块之间互操作性的可行性。 因此,我想知道您在Redis的哪些本地数据结构中构建了您自己的“图形数据”数据结构,当我们运行TYPE myGgraph命令时,该数据结构会显示出来。 是RedisGgraph模块(或其子组件、节点、边、路径)内部的图,是建立在Redis的已知
-
Redis使用Java为每个消费者发送一条消息
我正在尝试用redis streams实现一个java应用程序,其中每个consomer只使用一条消息。就像管道/队列一样,每个使用者只接收一条消息,对其进行处理,完成后,使用者接收流中尚未处理的下一条消息。有效的方法是,每条消息只被一个消费者(使用xreadgroup)使用。 我从redislabs开始学习本教程 守则: 我当前的问题是,一个消费者从队列中获取多条消息,在某些情况下,其他消费者正
-
如何为redis streams定义TTL?
我有两个微服务,我需要在它们之间实现可靠的通知。我考虑过使用redis streams——serviceA将向serviceB发送一个标识符为X的请求。一旦serviceB完成了serviceA要求的工作,它将创建/向流中添加一个新项目(该流特定于X),让它知道它已经完成了。 ServiceA可以发送多个请求,每个请求可以具有不同的标识符。所以它会阻止不同流中的新元素。 我的问题是如何删除不再需要
-
Redis—在修剪队列期间数据丢失的可能性
我有一种生产者-消费者设置,其中生产者(不同线程上的多个生产者)将数据排入redis队列,消费者(单个线程上的单个消费者)监视该队列。当队列长度达到时,例如 使用redis-py客户端,我使用以下代码提取前10000项,并删除它们: (用于lrange和ltrim的文件) 我的问题是,这里有数据丢失的机会吗?例如,在调用函数ltrim()和实际修剪队列之间的时间(在这种情况下,最新的日志将丢失,因
-
特定收件人使用redis和python使用的故障安全消息广播
因此,Redis5.0新引入了一个名为Streams的新功能。它们似乎非常适合为进程间通信分发消息: 在可靠性方面,它们超越了发布/订阅事件消息的能力:发布/订阅是一种“火与忘”的方式,无法保证收件人会收到消息 redis列表有些低级,但仍然可以使用。但是,流针对性能和上述用例进行了优化 然而,由于这个特性是相当新的,几乎没有任何Python(甚至一般redis)手册,我真的不知道如何使流系统适应