
性能问题,同时反序列化大量的用户定义的对象从Redis通过协议bufnet

问题:在对从Redis接收的字节进行反序列化时,性能变慢。
我正在使用REDIS在ASP中分发缓存。NET web应用程序。
为了从我的应用程序中与Redis进行对话,我正在使用StackExchange。Redis。
为了序列化/反序列化从/到DTO接收到/从服务器接收到/从服务器接收到的字节,我正在使用协议buf-net
我的目标是将一个包含100,000个用户的字典(字典(int, User))存储到Redis中,并在单个请求中多次检索它。
该字典将驻留在MyContext下。当前。用户属性。该字典的键是用户ID,值是完整的dto。我现在遇到的问题是,从字节反序列化列表100,000个用户需要1.5-2秒(Redis给我字节)。我必须在请求中多次使用该属性。
public Dictionary<int, User> Users
{
get
{
// Get users from Redis cache.
// Save it in Redis cache if it is not there before and then get it.
}
}
Users是在我的上下文包装器类中公开的属性。
这是我为用户准备的DTO(此DTO有100多个属性):
[ProtoContract]
public class User
{
[ProtoMember(1)]
public string UserName { get; set; }
[ProtoMember(2)]
public string UserID { get; set; }
[ProtoMember(3)]
public string FirstName { get; set; }
.
.
.
.
}
这是我在StackExchange的帮助下与Redis交谈的代码片段。Redis:
存储时-将我的DTO转换为字节,以便将其存储到Redis中:
数据库。StringSet(cacheKey、bytes、slidingExpiration)
命令:
private byte[] ObjectToByteArrayFromProtoBuff(Object obj)
{
if (obj == null)
{
return null;
}
using (MemoryStream ms = new MemoryStream())
{
Serializer.Serialize(ms, obj);
return ms.ToArray();
}
}
在提取-将字节转换为DTO时,从
DB. StringGet(cacheKey);
命令:
private T ByteArrayToObjectFromProtoBuff<T>(byte[] arrBytes)
{
if (arrBytes != null)
{
using (MemoryStream ms = new MemoryStream(arrBytes))
{
var obj = Serializer.Deserialize<T>(ms);
return obj;
}
}
return default(T);
}
这是ANTS Performance Profiler的屏幕截图,显示protobuf网络从Redis提供的字节中反序列化100000个用户所花费的时间。
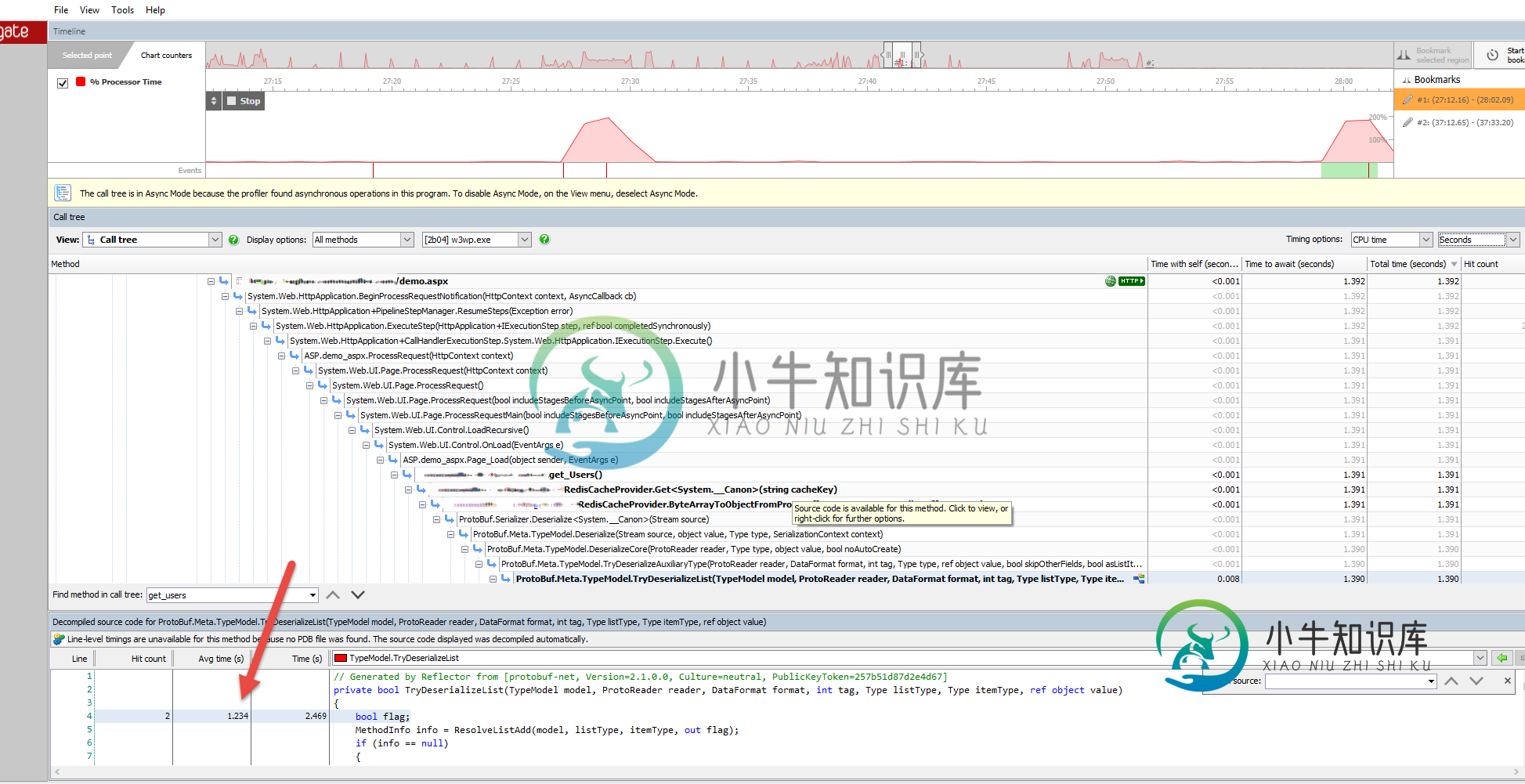
如您所见,将字节反序列化到用户字典(字典用户)中所需的平均时间约为1.5到2秒,这太长了,因为我在很多地方使用该属性从该字典中获取用户信息。
你能告诉我我做错了什么吗?
每次都将Redis中的100000个用户列表反序列化到应用程序中,然后使用它,这样好吗?(每个请求还必须反序列化使用ever Users属性处理请求的位置)。
将字典/集合/用户列表或任何其他大型集合以字节为单位存储到Redis中,然后在每次我们必须使用它时通过反序列化将其取回是正确的吗?
根据下面的帖子,堆栈交换是否使用缓存?如果是,如何使用?我知道StackExchange大量使用Redis。我相信我的100000个用户要少得多,其规模(大约60-80MB)远远小于StackExchange和其他网站(FB等)的规模。StackOverflow为什么能如此快速地反序列化如此庞大的用户/热门问题列表和许多其他项目(缓存中)?
我不能使用一个有100000个用户的字典,在缓存下使用DTO(该列表中的每个项都有100多个属性),并在单个请求或每个请求中多次反序列化它吗?
当我使用HttpRuntime时,我对该列表/字典没有任何问题。缓存作为缓存提供程序,但当我切换到Redis时,反序列化部分会造成阻碍,因为它仍然很慢。
我想在这篇文章中再添加一个细节。之前,我使用BinaryFormatter反序列化该列表,它几乎比我现在使用的protobufnet慢10倍。但是,即使使用protobufnet,从字节反序列化这些用户平均需要1.5到2秒,这仍然很慢,因为该属性必须在代码中多次使用。
共有1个答案

是的,如果您尝试传输大量对象的集合,您将始终需要为整个图支付带宽反序列化成本。这里的关键是:不要这样做。每个请求多次获取100,000个用户的列表似乎完全没有必要,而且在很大程度上是一个性能瓶颈。
有两种常见的方法:
- 使用大型对象(
字典
这两种方法都很好,您更喜欢哪种方法可能取决于您的请求率与数据更改率,以及您对数据的最新要求。例如,对于第二种方法,您可以考虑使用redis哈希,其中键与您现在使用的非常相似,哈希槽键是int(或其中的一些字符串/二进制表示),哈希槽值是单个DyveUser实例的序列化形式。在这里使用哈希(而不是按用户字符串)的优点是,您仍然可以通过redis哈希命令(例如,hgetall)一次获取/清除/等所有用户。SE中提供了所有必需的哈希操作。带有前缀的Redis。
-
这就是我想要实现的: > 在Proc#1中使用google协议缓冲区建模对象 使用proto-buf序列化该对象,并将其发送到posix消息队列。 在Proc#2中读取流并将其反序列化为类似的模型,同时使用协议缓冲区。 换句话说: 进程1中的对象-- 问题是Proc#1和Proc#2可能是完全不同的语言平台。程序#1通常是C与g相一致的。但是Proc#2可以是任何东西:Python、Java等等。
-
我该怎么做才能使这件事如我所愿?。谢谢 JSON对象示例列表 示例JSON对象: null 忽略不存在json字段的反序列化错误,但问题仍然存在。 示例:对象反序列化器
-
问题内容: 确定,所以我编辑了问题,因为它不够清楚。 编辑2 :更新了JSON文件。 我在Android应用程序中使用GSON,我需要解析来自服务器的JSON文件,这些文件有点太复杂了。我不想让我的对象结构太沉重,所以我想简化内容: 所以我的对象的结构将不是JSON文件的结构。 例如,如果在JSON中,我有以下内容: 我不想保留我当前的对象结构,即一个对象,其中包含一个和一个“总计”。但是我只想将
-
我所在的团队使用杰克逊数据绑定来处理发送到 REST API 和从 REST API 发送的 JSON 的序列化和反序列化。该 API 广泛使用一种臭名昭著且难以处理的模式,我们称之为“键值”。不幸的是,JSON的格式超出了我们的控制范围,所以我试图找到一种简单易行的好方法来处理序列化和反序列化它们。 键值总是以下列模式出现: 值得注意的是,它们始终采用数组的形式,其中包含单个对象,并且对象中 k
-
我有下面的JSON,我正试图使用Jackson API反序列化它 我基本上需要一个附件类,它有一个AttachmentFile对象列表,如下所示: 如何使用自定义反序列化器实现这一点? 谢谢
-
错误: java.lang.ClassNotFoundException:testprocedure.tp$3在java.net.URLClassLoader$1上运行(未知源)在java.net.URLClassLoader上运行(未知源)在java.security.accessController.doprivileged(本机方法)在java.net.URLClassLoader.find