《石化盈科》专题
-
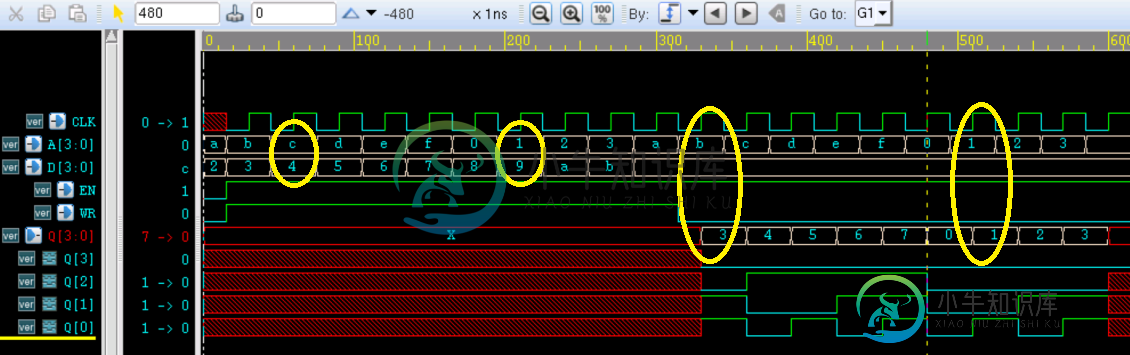 5.3 Verilog 带参数例化
5.3 Verilog 带参数例化主要内容:实例,实例,实例,实例,实例,实例,实例,实例,实例关键词: defparam,参数,例化,ram 当一个模块被另一个模块引用例化时,高层模块可以对低层模块的参数值进行改写。这样就允许在编译时将不同的参数传递给多个相同名字的模块,而不用单独为只有参数不同的多个模块再新建文件。 参数覆盖有 2 种方式:1)使用关键字 defparam,2)带参数值模块例化。 defparam 语句 可以用关键字 defparam 通过模块层次调用的方法,来改写低层次
-
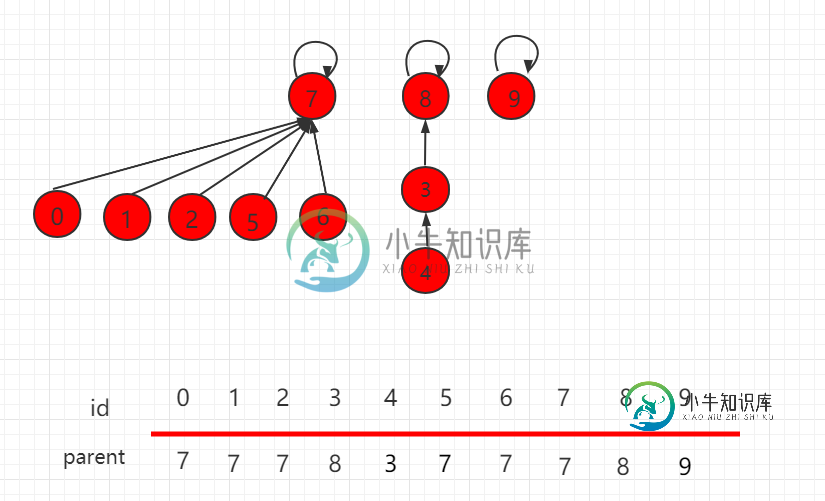 并查集 rank 的优化
并查集 rank 的优化主要内容:UnionFind3.java 文件代码:上一小节介绍了并查集基于 size 的优化,但是某些场景下,也会存在某些问题,如下图所示,操作 union(4,2)。 根据上一小节,size 的优化,元素少的集合根节点指向元素多的根节点。操完后,层数变为4,比之前增多了一层,如下图所示: 由此可知,依靠集合的 size 判断指向并不是完全正确的,更准确的是,根据两个集合层数,具体判断根节点的指向,层数少的集合根节点指向层数多的集合根节点,如下图
-
 并查集 size 的优化
并查集 size 的优化主要内容:UnionFind3.java 文件代码:按照上一小节的思路,我们把如下图所示的并查集,进行 union(4,9) 操作。 合并操作后的结构为: 可以发现,这个结构的树的层相对较高,若此时元素数量增多,这样产生的消耗就会相对较大。解决这个问题其实很简单,在进行具体指向操作的时候先进行判断,把元素少的集合根节点指向元素多的根节点,能更高概率的生成一个层数比较低的树。 构造并查集的时候需要多一个参数,sz 数组,sz[i] 表示以 i 为根的
-
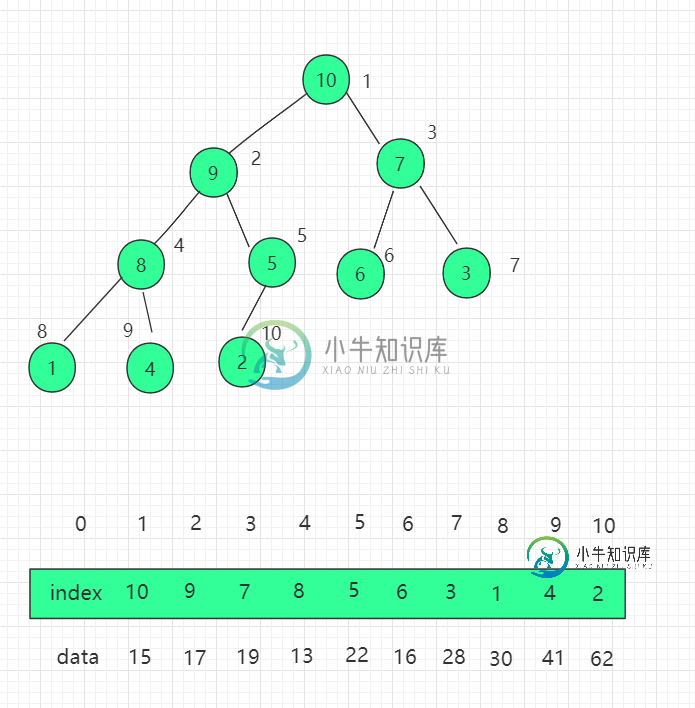 索引堆及其优化
索引堆及其优化主要内容:src/runoob/heap/IndexMaxHeap.java 文件代码:一、概念及其介绍 索引堆是对堆这个数据结构的优化。 索引堆使用了一个新的 int 类型的数组,用于存放索引信息。 相较于堆,优点如下: 优化了交换元素的消耗。 加入的数据位置固定,方便寻找。 二、适用说明 如果堆中存储的元素较大,那么进行交换就要消耗大量的时间,这个时候可以用索引堆的数据结构进行替代,堆中存储的是数组的索引,我们相应操作的是索引。 三、结构图示 我们需要对之前堆的代码实现进行改造,
-
Python格式化字符串
主要内容:指定最小输出宽度,指定对齐方式,指定小数精度我们在《 第一个Python程序——在屏幕上输出文本》中讲到过 print() 函数的用法,这只是最简单最初级的形式,print() 还有很多高级的玩法,比如格式化输出,这就是本节要讲解的内容。 熟悉C语言 printf() 函数的读者能够轻而易举学会 Python print() 函数,它们是非常类似的。 print() 函数使用以 开头的转换说明符对各种类型的数据进行格式化输出,具体请看下表。
-
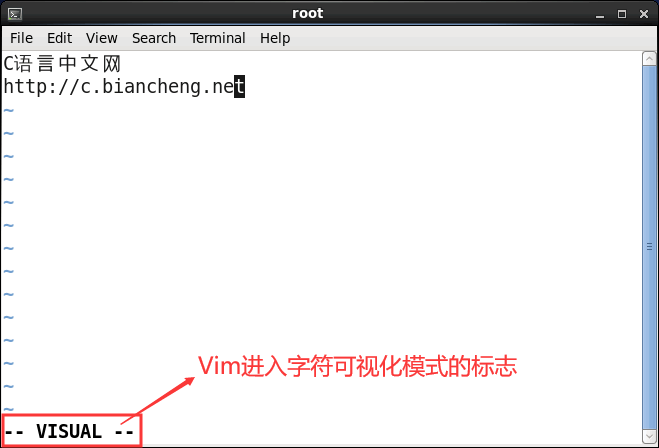 Linux Vim可视化模式
Linux Vim可视化模式相信大家都使用过带图形界面的操作系统中的文字编辑器,用户可以使用鼠标来选择要操作的文本,非常方便。在 Vim 编辑器中也有类似的功能,但不是通过鼠标,而是通过键盘来选择要操作的文本。 在 Vim 中,如果想选中目标文本,就需要调整 Vim 进入可视化模式,如表 1 所示,通过在 Vim 命令模式下键入不同的键,可以进入不同的可视化模式。 表 1 进入Vim可视化模式的方式 命令 功能 v(小写)
-
C++ cout格式化输出
主要内容:C++ cout成员方法格式化输出,使用流操纵算子格式化输出在某些实际场景中,我们经常需要按照一定的格式输出数据,比如输出浮点数时保留 2 位小数,再比如以十六进制的形式输出整数,等等。 对于学过 C 语言的读者应该知道,当使用 printf() 函数输出数据时,可以通过设定一些合理的格式控制符,来达到以指定格式输出数据的目的。例如 %.2f 表示输出浮点数时保留 2 位小数,%#X 表示以十六进制、带 0X 前缀的方式输出整数。 关于 printf()
-
格式化读写文件
fscanf() 和 fprintf() 函数与前面使用的 scanf() 和 printf() 功能相似,都是格式化读写函数,两者的区别在于 fscanf() 和 fprintf() 的读写对象不是键盘和显示器,而是磁盘文件。 这两个函数的原型为: fp 为文件 指针,format 为格式控制字符串,... 表示参数列表。与 scanf() 和 printf() 相比,它们仅仅多了一个 fp 参
-
GWT:Tomcat无法序列化“javax.net.ssl.SSLException”
在我的工作场所,我使用Tomcat6+Java6(我认为)测试了一个GWT webapp,运行良好,但今天它升级到Java7(Java版本输出),当我试图打开webapp时,我在catalina.out中收到以下错误(index.html中的布局运行良好): Grave:在分发传入的RPC调用com.google.gwt.user.client.RPC.SerializationException
-
与Java的确切变化
我正在为一堂Java课的家庭作业而苦恼。我的代码如下所示。 我的美元和25美分的输出有问题,我不确定是25美分还是美元的错误?例如,我从我的实验室得到了一个错误- “产出不同。请参见下面的重点内容。 输入:141 您的产出 1美元1角1镍1便士 预期产出 1美元1季度1角1镍1便士”
-
宏值的字符串化
我遇到了一个问题--我需要同时使用一个string和Integer的宏值。 这会失败,但会出现一条关于“stray#”的消息,即使它起作用了,我想我也会得到宏名的字符串化,而不是值的字符串化。当然,我可以将值提供给最终的方法(),但它既不漂亮也不高效。在这种情况下,我希望预处理器不要以特殊的方式处理字符串,而应该像普通代码一样处理它们的内容。目前,我使用来处理它,但可以理解,我对此并不满意。 怎么
-
物化自动完成ajax
我正在使用materialize autocomplete插件创建带有autocomplete的多个标记输入。插件工作良好,但仅用于作为预先定义的数组传递的数据。如果数据是从ajax调用传递的,则插件不会显示带有选项的下拉列表,就好像没有结果一样。有结果事实上,他们被缓存(使用缓存选项),并显示为下拉只有在重新键入搜索短语。 总而言之,autocomplete插件不会等待ajax完成其请求并交付数
-
多DTO手动初始化
在Microservice中,我们将多个DTO数据作为字符串json发布。 控制器: 发布Json: DTO: Dto1和Dto2是java DTO对象名称.如何将字符串json转换为java对象?
-
tkinter python最大化窗口
我想初始化一个窗口为最大化,但我不知道如何做。我在Windows7上使用Python3.3和Tkinter 8.6。我想答案就在这里:http://www.tcl.tk/man/Tcl/Tkcmd/wm.htmam.m8但是我不知道如何将它输入到我的python脚本中 此外,我需要得到窗口的宽度和高度(既是最大化的,如果用户重新缩放它之后),但我想我可以自己找到。
-
discord.js角色检查优化
我目前正在建立一个不和谐验证机器人,这个机器人的一个功能,如果检查你是否有一个角色从每一个需要的类别,然后在最后产生你的角色的总结。目前,我有一个工作解决方案,它的功能完全符合我的要求,但它使用了一个很大的if堆栈,我对js很陌生,但被告知尽可能不要使用大的if/if else if堆栈。我已经研究了switch的案例,但不知道如何应用这些案例,所以我想知道是否有一种更优化的方法来实现我所需要的。