《石化盈科》专题
-
Hello World - 格式化输出
打印操作由std::fmt里面所定义的一系列宏来处理,其中包括: format!:将格式化文本写到字符串(String)。(译注: 字符串是返回值不是参数。) print!:与 format!类似,但将文本输出到控制台。 println!: 与 print!类似,但输出结果追加一个换行符。 所有的解析文本都以相同的方式进行。另外一点是格式化的正确性在编译时检查。 fn main() { /
-
37. 序列化二叉树
NowCoder 题目描述 请实现两个函数,分别用来序列化和反序列化二叉树。 解题思路 // java private String deserializeStr; public String Serialize(TreeNode root) { if (root == null) return "#"; return root.val + " " + Seria
-
 redis持久化的介绍
redis持久化的介绍本文向大家介绍redis持久化的介绍,包括了redis持久化的介绍的使用技巧和注意事项,需要的朋友参考一下 1. RDB 1.1 RDB简介 RDB:在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。 工作机制:每隔一段时间,就把内存中的数据保存到硬盘上的指定文件中。 RDB是默认开启的! Redis会单独创建(fork)一个子
-
了解tf.contrib.lite.TFLiteConverter量化参数
问题内容: 我试图在将张量流模型转换为tflite模型时使用UINT8量化: 如果使用use ,则模型大小比原始fp32模型小4倍,因此我假定模型权重为uint8,但是当我加载模型并通过float32获取输入类型时。量化模型的输出与原始模型大致相同。 转换模型的输入/输出: 另一个选择是显式指定更多参数:模型大小比原始fp32模型小x4,模型输入类型为uint8,但模型输出更像垃圾。 转换模型的输
-
子类化numpy ndarray问题
问题内容: 我想继承numpy ndarray。但是,我无法更改数组。为什么不更改数组?谢谢。 问题答案: 也许使它成为一个函数,而不是一个方法: 或者,如果您希望将其用作方法, 此处的主要区别在于,它不尝试修改,而仅返回的新实例。
-
MySQL优化GROUP BY方案
本文向大家介绍MySQL优化GROUP BY方案,包括了MySQL优化GROUP BY方案的使用技巧和注意事项,需要的朋友参考一下 执行GROUP BY子句的最一般的方法:先扫描整个表,然后创建一个新的临时表,表中每个组的所有行应为连续的,最后使用该临时表来找到组并应用聚集函数(如果有聚集函数)。在某些情况中,MySQL通过访问索引就可以得到结果,而不用创建临时表。此类查询的 EXPLAIN 输出
-
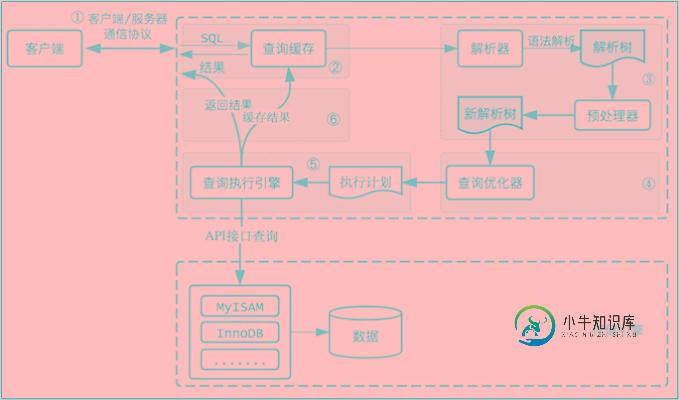 MySQL优化方案参考
MySQL优化方案参考本文向大家介绍MySQL优化方案参考,包括了MySQL优化方案参考的使用技巧和注意事项,需要的朋友参考一下 优化可能带来的问题 优化不总是对一个单纯的环境进行,还很可能是一个复杂的已投产的系统。 优化手段本来就有很大的风险,只不过你没能力意识到和预见到! 任何的技术可以解决一个问题,但必然存在带来一个问题的风险! 对于优化来说解决问题而带来的问题,控制在可接受的范围内才是有成果。 保持现状或出现更
-
简化嵌套数组JavaScript
本文向大家介绍简化嵌套数组JavaScript,包括了简化嵌套数组JavaScript的使用技巧和注意事项,需要的朋友参考一下 假设我们有一个数组数组,其中包含一些这样的元素- 我们的工作是编写一个递归函数,该函数接受此嵌套数组,并将数组中的所有fale值(NaN,undefined和null)替换为0。 因此,让我们为该函数编写代码- 示例 输出结果 控制台中的输出将为-
-
如何参数化Pytest timeline
问题内容: 考虑以下Pytest: 该测试使用Pytest固定装置,其本身具有属性。在测试中迭代该属性,以便仅在每个in的断言均成立的情况下测试才通过。 但是,我实际上想做的是生成3个测试,其中2个应该通过,其中1个将失败。我试过了 但这导致 据我了解,在Pytest固定装置中,函数“成为”其返回值,但是在对参数进行参数化时,这似乎尚未发生。如何以所需的方式设置测试? 问题答案: 从 pytest
-
Java实例化类详解
本文向大家介绍Java实例化类详解,包括了Java实例化类详解的使用技巧和注意事项,需要的朋友参考一下 Java 中实例化类的动作,你是否还是一成不变 new 对应对象呢? 经手的项目多了,代码编写量自然会增加,渐渐的会对设计模式产生感觉。 怎样使书写出来的类实例化动作,高内聚,低耦合,又兼具一定的扩展能力呢? 本文试图从几段鲜活的代码入手,给大家呈现不一样的 Java 实
-
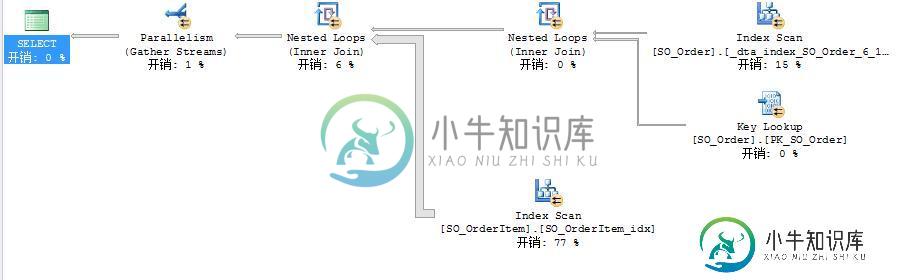 SQL字段拆分优化
SQL字段拆分优化本文向大家介绍SQL字段拆分优化,包括了SQL字段拆分优化的使用技巧和注意事项,需要的朋友参考一下 今天看到一条用函数处理连接的SQL,是群里某位网友的,SQL语句如下: 语句不算复杂,只是执行比较慢,下面是关于这SQL语句的一些信息: --1.SQL执行203条数据 --2.耗时12秒 --3.so_order表的fid字段是字符串集合, --由1-2个字符串组成,用','分隔 通过分析执行
-
与Python Pandas融化相反
问题内容: 我无法弄清楚如何使用python中的Pandas进行“反向融化”。这是我的起始数据 这是我想要的输出: 我敢肯定有一个简单的方法可以做到这一点,但是我不知道怎么做。 问题答案: 有几种方法; 使用: 使用: 或后跟:
-
MySQL如何优化索引
本文向大家介绍MySQL如何优化索引,包括了MySQL如何优化索引的使用技巧和注意事项,需要的朋友参考一下 1. MySQL如何使用索引 索引用于快速查找具有特定列值的行。如果没有索引,MySQL必须从第一行开始,然后遍历整个表以找到相关的行。表越大,花费越多。如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间查找的位置,而不必查看所有数据。这比顺序读取每一行要快得多。 大多数MyS
-
Python内存优化技巧
问题内容: 我需要优化应用程序的RAM使用率。 请避免让我的讲座告诉我在编写Python时我不关心内存。我有一个内存问题,因为我使用了很大的默认字典(是的,我也想很快)。我当前的内存消耗为350MB,并且还在不断增长。我已经不能使用共享主机了,如果我的Apache打开更多进程,内存将增加两倍和三倍……这很昂贵。 我已经进行了 广泛的分析, 而且我确切地知道了问题所在。 我有几个带有Unicode键
-
OffsetDateTime格式化和解析
此代码 导致 Java语言时间总体安排DateTimeParseException:无法分析文本“2020-11-27 01:00”:无法从TemporalAccessor获取OffsetDateTime:{OffsetSeconds=3600},ISO解析为java类型的2020-11-27。时间总体安排已解析 这不管用吗?