《石化盈科》专题
-
如何将Angulation/Apollo客户端与石墨烯-Django集成?
很抱歉有这个问题。我是一个新的web开发与绝对没有经验与GraphQL,Relay或Apollo。我刚刚完成了一个web应用程序,前端是Angulation4,后端是Django Rest框架。该应用程序运行良好,除了一些组件具有复杂的数据关系和深度数据嵌套,需要多次服务器旅行来组装一个完整的对象。而且,即使只需要名称和id就可以填充查找列表,我也无法对具有多个字段的大量对象实现选择性字段查询。因
-
谷歌番石榴缓存invalidateAll()和cleanUp()之间的区别
问题内容: 说我有一个这样定义的: 根据我的阅读 (如果我错了,请纠正我): 如果将值写入0:00,则应在60秒后将其移至“准备退出”状态。从中实际删除值将在下一次 缓存修改 时发生(究竟是什么缓存修改?)。 那正确吗? 另外,我不确定和方法之间有什么区别,有人可以提供解释吗? 问题答案: *此链接的 *第一部分 :Guava如何使CacheBuilder中的条目到期? 我将重点讨论 expire
-
用VC++6.0实现石头剪刀布游戏的程序
本文向大家介绍用VC++6.0实现石头剪刀布游戏的程序,包括了用VC++6.0实现石头剪刀布游戏的程序的使用技巧和注意事项,需要的朋友参考一下 源程序是从网上看到的, geek_monkey于2015年3月3日修改了bug(输入字符非石头剪刀布都算是玩家赢) 编译环境为VC++6.0 增加“上帝模式”和数据统计,纯属娱乐。 我是C语言初学者,轻喷 以上就是使用vc++实现的石头剪刀布程序的全部代码
-
石英。JobStoretX.触发器由两个节点同时触发
我有两个节点具有相同的Quartz调度器。JobStore具有作业的唯一触发器,它每5秒执行一次,处理该作业需要一秒。
-
组织。石英ScheduleException:作业和触发器注册失败
我在使用quartz scheduler运行web应用程序时遇到以下错误。 我使用两个数据库连接和石英,我想使用德比,所以我给德比事务管理器在我的配置文件。 此配置文件中的问题是什么,quartz调度程序如何尝试访问数据库。 我的配置文件如下所示:
-
 在Grafana中交换石墨返回的时间戳和值
在Grafana中交换石墨返回的时间戳和值我正在用Grafana测试从石墨系统读取和绘制数据。 这就是Grafana对Graphite中json数据的期望: 我想从其中读取数据的系统交换时间戳和度量值,例如。
-
将番石榴集转换为列表的最快方法
我甚至不确定这是否可能,但我正在执行一个集合操作,如或,我需要将其转换为以便洗牌列表并将其传递给接受而不是的其他方法。因此,我将结果转换为并且一切都很好。但是从探查器中,我看到操作在负载下花费了很长时间,这是因为Guava设置的方式。它不像普通java集那样是一个常量操作。 下面是代码示例 我正在尝试找到将番石榴转换为的最快方法。通过挖掘代码,这就是Guava Sets所做的工作https://g
-
在加工过程中进口和使用番石榴2
我想使用Guava的Collections2的排列方法,如下所示:获取ArrayList中所有可能的排列,但我在导入它时遇到了困难。我使用的是处理,所以我想知道我是否需要做一些不同的事情来将其用于处理,或者根本不可能。 这是我试图通过上面的链接实现的代码: 任何帮助都将不胜感激谢谢!
-
Springfox招摇过市2和番石榴-爪哇。StackOverflowerr语言
我在Spring Boot 2项目中添加了Springfox Swagger 2.8.0,在应用程序启动期间,遇到以下问题: 这个问题的原因是什么?如何解决它?
-
将一般事件传递给番石榴事件总线?
我变得非常喜欢Google Gauva的EventBus,以至于我想把它包含在我的Swing GridBagBuilder API中。我们的目标是获取一个Swing组件,在任意事件中用它做一些事情,并将其订阅到EventBus。问题是我认为EventBus完成的反射操作不喜欢我的任意事件类型的泛型。 本质上,该方法接受双消费者,其中C是Swing组件,E是订阅EventBus的任意事件类型。 事件
-
提高红宝石中埃拉托色尼筛的效率?
下面是我对埃拉托色尼筛的实现,以找到达到上限参数的质数。 目前,当我的参数为 2,000,000 时,我的代码将在大约 2 秒内完成。我看到我正在通过将数字设置为零来做一个额外的步骤,然后压缩而不是一步删除这些数字。 我将如何着手实现这一点?你还有其他提高我的代码速度的建议吗?
-
第二天在指定时间启动石英触发器
我如何暂停我的石英触发器,并在第二天在其指定的开始时间开始它?为(如)。我的cron表达式是*0/20 15-00**?所以当我暂停扳机时,它应该在第二天15:00开始。
-
无法在Grails 2.4.3中导入石英监视器插件
我已经为我的圣杯项目安装了石英插件,并创建了Job。 BuildConfig.groovy 现在我想用下面的插件来监控我创建的作业。 https://grails.org/plugin/quartz-monitor 要安装此插件,它说 在BuildConfig.groovy中添加依赖项: 我补充道 但它给出的错误为: 在深入挖掘之后,我了解了grails的插件库 http://repo . gra
-
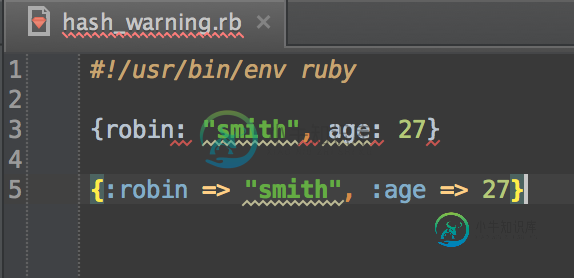 IntelliJ Idea终极红底红宝石速记哈希文字
IntelliJ Idea终极红底红宝石速记哈希文字有人知道为什么IntelliJ Idea Ultimate不喜欢更新语法中的Ruby哈希文本吗?请参阅下面IDE屏幕截图中的红色下划线。语法: 真的很烦人,因为这意味着我的整个项目在目录树上都有一条红色下划线。 我在IDE首选项中设置了一个大于1.9的Ruby SDK版本(我认为是在这个时候引入了新的哈希文本语法),所以没有任何借口! 谢谢
-
番石榴/咖啡因/中的ConcurrentHashMap计算?高速缓存
从Java8开始,我们可以在ConcurrentHashMap上使用。compute*方法来按键同步处理,这样,如果两个线程同时在同一个键上执行。compute*方法,回调仍然会相继执行,而不是同时执行。但是ConcurrentHashMap不能像缓存通常允许的那样提供及时删除数据的能力。 Guava/Caffeine缓存提供了基于时间的自动删除值的能力,但是您没有基于键的同步处理的讨厌特性,如在