《石化盈科》专题
-
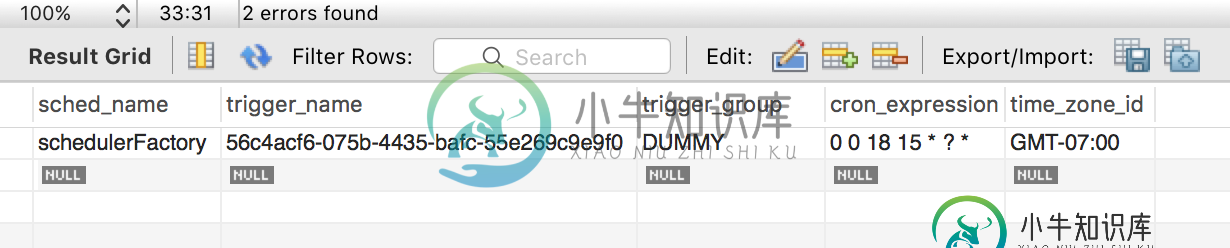 如何处理cron触发器的石英夏时制用户时区?
如何处理cron触发器的石英夏时制用户时区?我的服务api接收quartz作业的startDate和要执行的作业的day。在内部,我将其转换为cron表达式并保存在Quartz中。 例如,PST中的一个用户今天(2017年11月3日)提交了一个作业请求,如下所示。 在这里,用户希望从2017-11-03开始,在每月15日下午6点启动一个工作。所以石英的第一天将在2017-11-15。以上请求是如何转换为cron表达式,这是正确的。下面是QR
-
 Struts2 本地化/国际化(i18n)
Struts2 本地化/国际化(i18n)主要内容:资源包:,访问消息:,Localization 例子:国际化(i18n)是规划和实施的产品和服务,使他们能很容易地适应特定的本地语言和文化的过程中,这个过程被称为本地化。国际化的过程有时也被称为翻译或本地化启用。国际化是缩写i18n,因为我和两端用n字打头,并有18个字符之间的第i个和最后n。 Struts2提供本地化,即,国际化(i18n)支持,通过资源包,拦截器和标签库在以下地方: UI 标签 消息和错误 动作类 资源包: Struts2 使用资
-
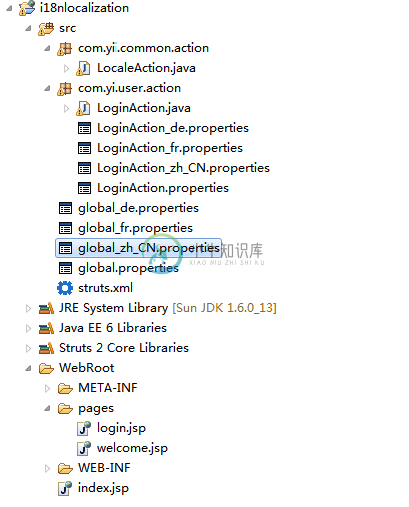 Struts2本地化和国际化
Struts2本地化和国际化主要内容:1. 工程结构,2. Properties文件,3. 动作类,4. 视图页面,5. 显示资源包的消息?,6. struts.xml,7. 示例,参考Struts 2的国际化(I18N)和本地化(i10n)或多语言的例子,来说明如何使用资源包来显示不同语言的消息。在这个例子中,您将创建一个简单的登录屏幕,通过Struts 2的UI组件显示来自资源包的消息, 并更改基于所选的语言选项的语言环境。 1. 工程结构 项目结构,如下图片显示: 2. Properties文件 确保属性文件命名为国
-
格式化输出 - 格式化
我们可以看到格式化就是通过格式字符串得到特定格式: format!("{}", foo) -> "3735928559" format!("0x{:X}", foo) -> "0xDEADBEEF" format!("0o{:o}", foo) -> "0o33653337357" 根据使用的参数类型,同样的变量(foo)能够格式化成不同的形式:X, o 和未指定形式。 这个格式化的功能是通过 t
-
Kryo序列化/反序列化
我正在尝试使用kryo序列化和反序列化到二进制。我想我已经完成了序列化,但似乎无法反序列化。下面是我正在处理的代码,但最终我想存储一个字节[],然后再次读取它。文档只显示了如何使用文件。
-
Camel石英路由在路由启动时不希望的作业执行
我在第1天17:00之前开始我的路由,作业将在第1天17:00触发 我在第1天17:00后开始路由,作业应在第2天17:00触发 和我选择了一份全州的工作有关吗?我选择了一个有状态的作业,以避免并发执行相同的作业。
-
 这些关联不是通过顺丁烯、方石和电子产生的
这些关联不是通过顺丁烯、方石和电子产生的我正在开发一个电子应用程序,对于数据库,我正在使用sqlite3和sequelize。我想在以下两个模型之间建立一对多关系。 > 项目 度量指标可以是升/千克/单位,并且可以在这些指标中的任何一个中测量项目。下面是我如何声明项模型的。 const{Model,DataTypes}=require(“sequelize”);const sequelize=require(“../database/d
-
我根本无法让“大口红宝石”或“大口大口”去工作
忘记vanilla sass测试,回到这里的gulp sass问题-在我的gulpfile中,我在运行递归复制任务之前运行gulp sass任务,所以如果它工作,那么应该应用并复制sass更改。至少我是这么想的。 下面是显示相关文件的dir结构: 在gulpfile.js中,有两个文件映射对象可以很好地用于src/assets/的递归副本。但是为了测试gulp-ruby-sass任务,我对SASS
-
为什么java 7不能使用钻石运算符和multi-catch语句
um使用Java7(1.7.0_67),项目语言级别设置为7-Diamond、ARM、multi-catch。我的代码如下,使用maven构建时抛出编译错误的行。 InstrumentingAgent行63中的多捕捉块 编译时我遇到了以下错误。为什么它不起作用?我做错了什么。我正在使用IntelliJ IDE。 根据我所读的钻石运算符应该与Java7一起工作。但是为什么我得到这个。如果我用相关类型
-
如何使一个石英作业创建另一个作业后执行?
我想用Quartz实现下面的算法,但不确定是否可以做到。这是我第一次尝试使用石英。 用户通知作业-此作业计算每月报告并向用户发送电子邮件,它需要用户id和用于生成自定义用户报告的其他参数 可能需要生成10,000多个这样的报告 null 如何确保每月作业在单个事务中执行,以便识别所有需要每月报告的用户,并安排作业通知他们 如何立即安排作业在创建它们的作业之后立即执行? 我用的是Spring 3.2
-
Java序列化-Android反序列化
问题内容: 我尝试过在Java和Android之间实现跨平台序列化。我使用了Serializable,并将我的代码在Android中与台式机Java放在同一软件包中。 来源:java-desktop序列化 资料来源:Android-反序列化 学生是一类,实现了Serializable。在桌面上,我将学生实例序列化为“ thestudent.dat”。我将此文件放在Android设备上的SD卡上,并
-
Redis序列化和反序列化
问题内容: 我注意到存储在Redis中的某些序列化对象在反序列化方面遇到问题。 当我对Redis中存储的对象类进行更改时,通常会发生这种情况。 我想了解问题,以便为解决方案设计一个清晰的方案。 我的问题是,什么导致反序列化问题?移除公共/私人财产会引起问题吗?也许添加新属性?向类添加新功能会产生问题吗?那么更多的构造函数呢? 在我的序列化对象中,我有一个属性Map,如果我更改(更新了一些属性,添加
-
Golang序列化和反序列化
问题内容: Golang中将结构序列化和反序列化为字符串的最佳方法(完整性和性能)是什么,反之亦然? 例如,如果我有这个结构: 我想将其存储在Redis上并取回。我试过保存,整型和字符串,这很好,但是如何存储结构对象? 问题答案: 使用gob和base64可以解决问题,例如: 当您需要序列化自定义结构或类型(例如struct)时,只需添加以下行:
-
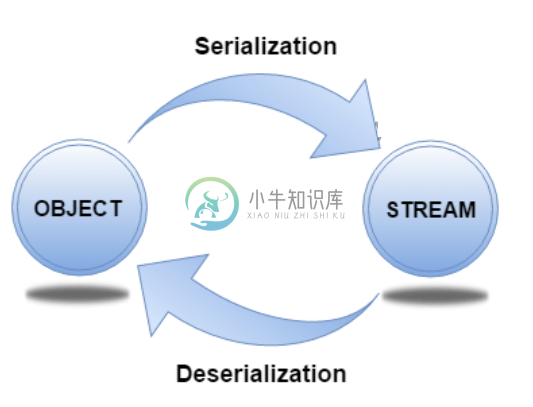 Java序列化和反序列化
Java序列化和反序列化主要内容:1 Java序列化和反序列化,2 Java序列化的优点,3 java.io.Serializable接口,4 Java ObjectOutputStream,5 Java ObjectInputStream,6 Java序列化的例子,7 Java反序列化的例子1 Java序列化和反序列化 Java中的序列化是一种将对象状态写入字节流的机制。它主要用于Hibernate,RMI,JPA,EJB和JMS技术。 序列化的反向操作称为反序列化,其中字节流被转换为对象。序列化和反序列化过程与平台
-
Java Stream并行化的可视化
问题内容: 通常,不清楚并行流如何精确地将输入拆分为多个块以及以什么顺序连接这些块。是否有任何方法可以可视化任何流源的整个过程,从而更好地了解发生了什么?假设我创建了这样的流: 我想看一些树状结构: 这意味着将整个输入范围划分为和,然后将范围进一步划分。当然,该图应反映Stream API的实际工作,因此,如果我对此类流执行某些实际操作,则拆分应该以相同的方式执行。 问题答案: 我想用一种解决方案