《湖北联投》专题
-
SQL内部联接与3个表?
问题内容: 我试图在一个视图中联接3个表;情况如下: 我有一张桌子,其中包含正在申请住在此大学校园的学生的信息。我还有另一个表格,列出了每个学生的“大厅偏好设置”(其中有3个)。但是这些首选项只是一个ID号,并且ID号在第三张表中有一个对应的Hall Name(不是设计此数据库…)。 差不多,我在桌子上看到了他们的偏好和他们的信息,结果是… 哪里会是。所以现在我想将其与第三个表匹配,该表包含一个和
-
Python字符串格式:%与串联
问题内容: 我正在开发一个应用程序,在其中执行一些请求以获取对象ID。在它们每个之后,我调用一个方法()将此id作为参数传递(请参见下面的代码)。 可以注意到,我正在将其转换为前缀并将其与前缀连接。但是,我知道我能做到这一点的多种其他方式(或者,例如),并在我的问题的结果:将超过字符串连接更好的可读性,代码约定和效率方面? 谢谢 问题答案: 这很容易成为基于意见的主题,但是我发现格式在大多数情况下
-
Sequelize ORM中联接表的条件
问题内容: 我想用sequelize ORM获得这样的查询: 问题是,后遗症不允许我在where子句中引用“ B”或“ C”表。以下代码 给我 这是完全不同的查询和结果 甚至不是有效的查询: 使用sequelize是否可以进行第一个查询,还是我应该坚持使用原始查询? 问题答案: 将引用联接表的列包装在
-
关于使用doctrine2删除级联
问题内容: 我试图做一个简单的例子,以学习如何从父表中删除一行并使用Doctrine2自动删除子表中的匹配行。 这是我正在使用的两个实体: Child.php: 父亲.php 这些表已在数据库上正确创建,但未创建“删除级联”选项。我究竟做错了什么? 问题答案: 在教义中有两种级联: 1)ORM级别- 在关联中使用- 这是在UnitOfWork中完成的计算,不影响数据库结构。删除对象时,UnitOf
-
ng-repeat内的AngularJS内联编辑
问题内容: 我正在与AngularJS一起显示应用程序键(应用程序标识符)表,我想使用编辑按钮在该表行中显示一个小表格。然后用户可以编辑字段并单击“保存”或“取消” 演示:http://jsfiddle.net/Thw8n/ 我的内联表单效果很好。我单击编辑,然后出现一个表格。取消也很棒。 我的问题是 如何连接保存按钮和将对API进行$ http调用的函数 如何从该行获取数据以发送到$ http调
-
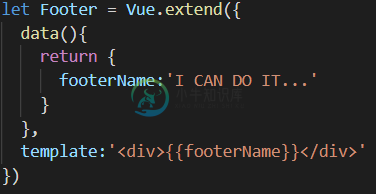 vue.extend与vue.component的区别和联系
vue.extend与vue.component的区别和联系本文向大家介绍vue.extend与vue.component的区别和联系,包括了vue.extend与vue.component的区别和联系的使用技巧和注意事项,需要的朋友参考一下 如果大家只顾开发,对基础知识不了解,在今后的解决问题过程中,也是个大问题,今天小编抽空对基础概念给大家屡一下,用于大家日后学习。 Vue.extend({})简述:使用vue.extend返回一个子类构造函数,也就是
-
React.js-正确设置内联样式
问题内容: 我正在尝试使用带有剑道分离器的Reactjs。拆分器的样式属性如下 使用Reactjs,如果我正确理解了所有内容,则可以使用内联样式来实现 但是,我也使用Dustin Getz jsxutil尝试将内容拆分成更多部分并具有独立的html片段。到目前为止,我有以下html片段(splitter.html) 和splitter.js组件,该组件按如下方式引用此html 现在,当我运行此命令
-
Django中的完全外部联接
问题内容: 如何使用django QuerySet API创建跨M2M关系芯片的完全外部联接的查询? 它不受支持,欢迎提供有关创建我自己的经理来执行此操作的提示。 编辑添加: @ S.Lott:感谢您的启发。应用程序需要使用OUTER JOIN。即使它仍然不完整,它也必须生成一个报告,显示输入的数据。我不知道结果将是一个新的类/模型。您的提示将对我有很大帮助。 问题答案: Django在通常的SQ
-
Django中的内联表单验证
问题内容: 我想在管理员更改表单中强制使用整个内联表单集。因此,在当前情况下,当我在“发票”表单(在“管理员”中)中单击“保存”时,内联订单表单为空白。我想阻止人们创建没有关联订单的发票。 有人知道这样做的简单方法吗? 在此实例中,模型字段上的常规验证(如)似乎不起作用。 问题答案: 最好的方法是定义一个自定义表单集,使用一种干净的方法来验证至少存在一个发票订单。
-
if语句在串联中?[关闭]
问题内容: 这个问题不太可能对将来的访客有所帮助;它仅与较小的地理区域,特定的时间段或极为狭窄的情况(通常不适用于Internet的全球受众)有关。要获得使该问题更广泛适用的帮助。 7年前关闭。 这行不通吗?还是我做错了?尝试了多种形式,似乎找不到关于该主题的任何可靠信息。有任何想法吗? 问题答案: 如果是一个自我陈述。这就像一个完整的声明。因此,不能在字符串左右连接之间使用它。更好的解决方案是使
-
Python中许多列表的串联
问题内容: 假设我有一个这样的函数: 它返回与给定顶点相邻的顶点列表。现在,我想创建一个包含所有邻居的列表。我这样做是这样的: 有没有更Python的方式做到这一点? 问题答案: [x for n in getNeighbors(vertex) for x in getNeighbors(n)] 要么
-
jQuery数据表行内联编辑
看看这个例子https://editor.datatables.net/examples/inline-editing/simple 它允许您在单击单元格时编辑文本。如果单击单元格,它将呈现为标记 我的情况,我想要有点不同。每行都有一个编辑按钮,用户点击编辑按钮,然后所有输入标签将显示在该行上。 我在上找不到任何演示或如何执行此操作,您能给我一些建议吗?
-
Minecraft基岩HTML5 UI:内联显示
我正在使用HTML5 UI(通过资源包部署html和css创建UI的内置方式)制作游戏内覆盖(在Minecraft Basefic Edition中) 我想实现一个类似HUD屏幕的外观:具有半透明黑色背景的文本块,可以根据文本大小进行调整,就像使用显示:内联块一样 。 遗憾的是,html呈现引擎不支持显示:内联块。 我假设他们正在使用相干Gameface库: 根据他们的留档,对任何东西的支持都很少
-
使用多个关联Hibernate获取
我正在为实体对象上的延迟加载集合执行此操作: 我想返回一个实体对象,其中加载了多个延迟加载的集合,我可以这样做吗(传入一个列表并为单个条件设置多个关联?):
-
Php联系人表单插入Mysql
最后编辑:现在一切正常工作将在下面的工作代码,清理后像idealCastle说,并修复了一些语法错误,一切正常工作,因为它应该与javascript验证谢谢大家 超文本标记语言代码: Javascript文件: PHP文件: