《原理》专题
-
 手动实现vue2.0的双向数据绑定原理详解
手动实现vue2.0的双向数据绑定原理详解本文向大家介绍手动实现vue2.0的双向数据绑定原理详解,包括了手动实现vue2.0的双向数据绑定原理详解的使用技巧和注意事项,需要的朋友参考一下 一句话概括:数据劫持(Object.defineProperty)+发布订阅模式 双向数据绑定有三大核心模块(dep 、observer、watcher),它们之间是怎么连接的,下面来一一介绍。 为了大家更好的理解双向数据绑定原理以及它们之间是如何实现
-
Java注解Annotation原理及自定义注解代码实例
本文向大家介绍Java注解Annotation原理及自定义注解代码实例,包括了Java注解Annotation原理及自定义注解代码实例的使用技巧和注意事项,需要的朋友参考一下 什么是注解? 对于很多初次接触的开发者来说应该都有这个疑问?Annontation是Java5开始引入的新特征,中文名称叫注解。它提供了一种安全的类似注释的机制,用来将任何的信息或元数据(metadata)与程序元素(类、方
-
如果清除prod缓存,则获取原则代理错误
当在服务器上折叠PROD高速缓存时,得到错误的教义代理,而在本地主机上,所有执行都没有错误。重置两台主机上的DEV缓存也成功重置。 我的观察1 运行console命令以清除产品缓存: sudo PHP应用程序/控制台缓存:清除-e prod 出错 PHP警告:require(/var/www/site.com/www/app/cache/proú/doctrine/orm/Proxies/úuu
-
 在FrameBuffer上绘制的LibGDX纹理比原始纹理更暗
在FrameBuffer上绘制的LibGDX纹理比原始纹理更暗更新1 如您所见,在FrameBuffer上绘制的LibGDX纹理,与直接在SpriteBatcher上绘制的纹理相比,在SpriteBatcher上绘制的纹理要比原始纹理暗一些。 左侧为原图,比手机1080x1920屏幕小50%。 右侧部分是先在FrameBuffer上绘制的TextureRegion,然后在SpriteBatch上绘制,如下代码所示: 如你所见,它比直接从纹理绘制的图像暗一点。
-
Mysql指定的密钥太长,无法理解原因?[副本]
语法错误或访问冲突:1071指定的密钥太长;最大密钥长度为767字节(SQL:更改表添加唯一()) 这个错误在我做的每件事情中都会无缘无故地出现...我确实制作了有默认值的数据库,它会弹出...复制100%的工作代码,它会弹出...甚至它会被修复我现在真的很无聊,因为它出现在15个不同的项目中...不明白为什么它会弹出,甚至git固定......重新安装Apache像5次获得最后一个版本...仍然
-
Java数组协方差是否违反了Liskov替换原理?
我正在阅读为什么Java中的数组协方差不好(为什么数组是协方差的,而泛型是不变的?)。如果是的子类型,则是的子类型。这是一个问题,因为这样的事情是可以做的: 这与“正确”实现的泛型不同。不是的子类型 我试图理解为什么它是坏的本质,并且刚刚读了关于LSP的文章。它有没有违反LSP?似乎没有明显的违规行为。
-
Laravel Database 数据库 - Laravel Database——分页原理与源码分析
paginate 分页 laravel 的分页用起来非常简单,只需要对 query 调用 paginate 函数,把返回的对象扔给前端 blade 文件,在 blade 文件调用函数 render 函数或者 link 函数,就可以得到 上一页、下一页 等等分页特效。 实际上,我们可以简单地把分页服务看作一个前端资源,render 函数或者 link 函数的结果就是分页前端代码。 如果你还对 lar
-
奇异值分解(SVD)原理与在降维中的应用
我们首先回顾下特征值和特征向量的定义如下:$$Ax=lambda x$$ 其中A是一个$$n times n$$的矩阵,x是一个n维向量,则我们说$$lambda$$是矩阵A的一个特征值,而x是矩阵A的特征值$$lambda$$所对应的特征向量。 求出特征值和特征向量有什么好处呢? 就是我们可以将矩阵A特征分解。如果我们求出了矩阵A的n个特征值$$lambda_1 leq lambda_2 leq
-
一张图了解 tensorflow 中的线性回归工作原理
10行关键代码实现的线性回归 # -*- coding: utf-8 -*- import numpy as np import tensorflow as tf # 随机生成1000个点,围绕在y=0.1x+0.3的直线周围 num_points = 1000 vectors_set = [] for i in xrange(num_points): x1 = np.random.no
-
深究熵的概念和公式以及最大熵原理
熵 有关熵的介绍,我在《自己动手做聊天机器人 十五-一篇文章读懂拿了图灵奖和诺贝尔奖的概率图模型》中做过简单的介绍,熵的英文是entropy,本来是一个热力学术语,表示物质系统的混乱状态。 我们都知道信息熵计算公式是H(U)=-∑(p logp),但是却不知道为什么,下面我们深入熵的本源来证明这个公式 假设下图是一个孤立的由3个分子构成一罐气体 那么这三个分子所处的位置有如下几种可能性: 图中不同
-
原则23:理解接口方法和虚函数的区别
咋一看,实现接口和重载一个虚函数似乎是一样的。都是定义一个在另一个类中声明的成员。第一眼的感觉是很有欺骗性的。实现接口和重载虚函数是非常不同的。在接口声明的成员是非虚的——至少不是默认的。子类不能重载基类实现的接口的成员。接口可以显示实现,可以把它们中 public 接口中隐藏。它们的概念不同而且使用也不同。 但是你可以这样实现接口以至于子类可以修改你的实现。你只需要对子类做一个 hook 就行了
-
原则6:理解几个不同相等概念的关系
当你定义类型(类或结构体)时,你同时要定义类型的相等。 C# 提供四种不同的函数决定两个不同对象是否“相等”: public static bool ReferenceEquals (object left, object right); public static bool Equals (object left, object right); public virtual bool Equal
-
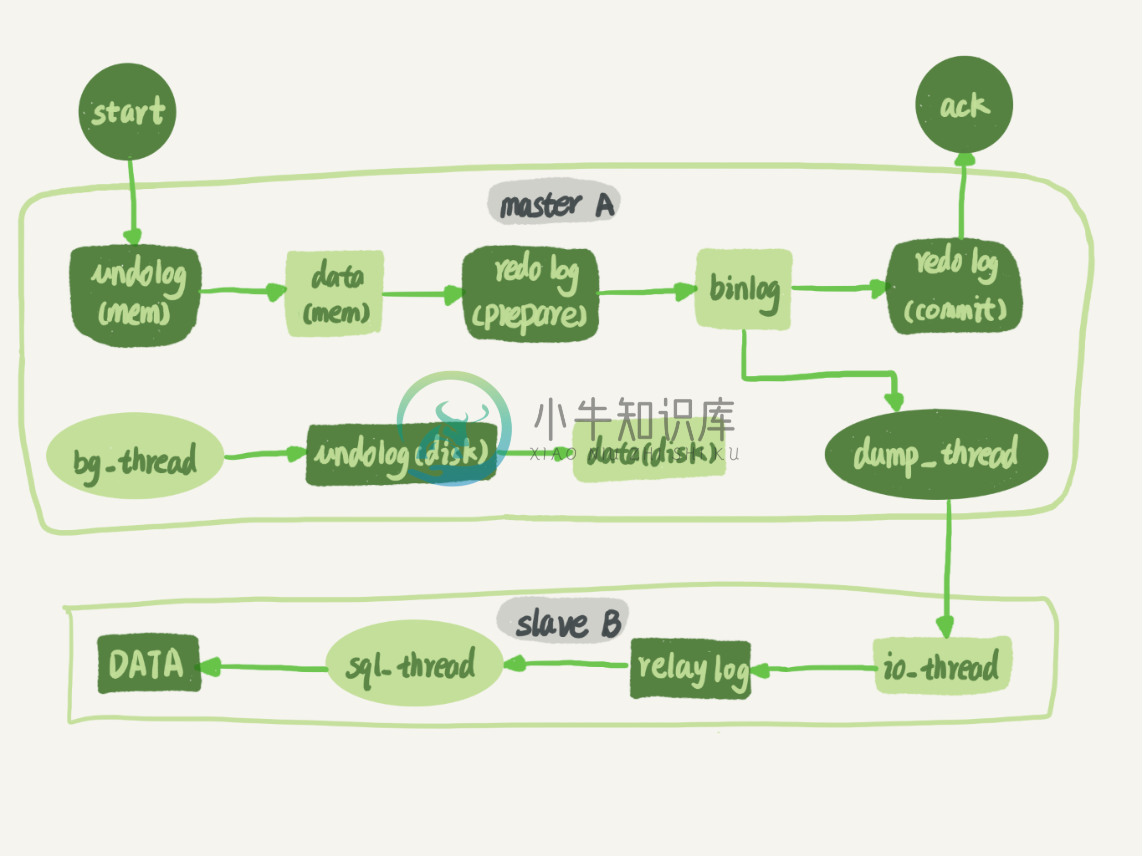 MySQL 数据库主从复制的基本原理和步骤
MySQL 数据库主从复制的基本原理和步骤主要内容:1 主从复制的原理,2 主从切换,3 双主互备,4 主备延迟,4.1 什么是主备延迟,4.3 主备切换策略,1.4. 并行复制详细介绍了MySQL主从复制的原理和基本流程,以及一些问题的处理方式。 1 主从复制的原理 主从复制可以很好的解决的单点故障,并且可以进行读写分离来减轻数据库的压力。很多情况下主服务器仅作为写入数据服务器,而构建多个从节点来进行数据读取。但主库也可以进行读操作。因此建议:关键业务读写都由主库承担,非关键业务读写分离。 下图就是MySQL主从同步的基本原理,节点A
-
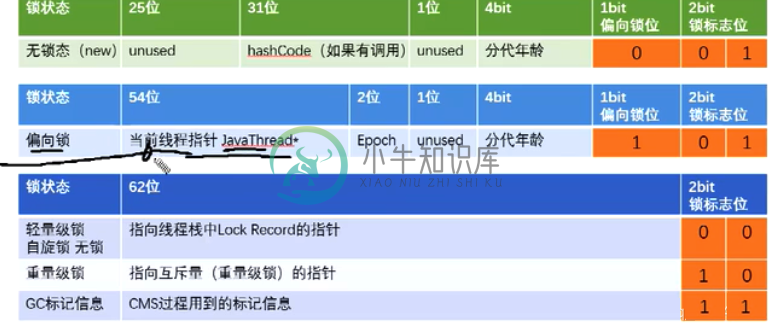 偏向锁、轻量级锁、重量级锁、自旋锁原理
偏向锁、轻量级锁、重量级锁、自旋锁原理主要内容:一、简介,二、Java对象头中的Mark Word,三、偏向锁,四、轻量级锁,五、重量级锁,六、自旋锁,七、锁升级过程一、简介 在讲解这些锁概念之前,我们要明确的是这些锁不等同于Java API中的ReentratLock这种锁,这些锁是概念上的,是JDK1.6中为了对synchronized同步关键字进行优化而产生的的锁机制。这些锁的启动和关闭策略可以通过设定JVM启动参数来设置,当然在一般情况下,使用JVM默认的策略就可以了。 二、Java对象头中的Mark Word HotSpo
-
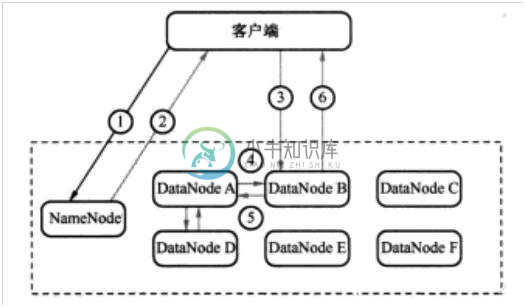 Hadoop分布式文件系统HDFS的工作原理详述
Hadoop分布式文件系统HDFS的工作原理详述Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。要理解HDFS的内部工作原理,首先要理解什么是分布式文件系统。 1.分布式文件系统 多台计算机联网协同工作(有时也称为一个集群)就像单台系统一样解决某种问题,这样的系统我们称之为分布式系统。 分布