《Keep内推》专题
-
javascript - vue 使用 keep-alive 包裹了一个带 tab 切换的瀑布流组件,切换tab后,瀑布流还会请求上一次的接口?
使用 vue2 + vant2 的项目 使用 vant tabs 组件包裹了一个瀑布流组件,切换每个 tab,瀑布流会无限刷新。 现在的问题是,切换完所有 tab 后,再切回第一个 tab,滑动页面,请求的数据还是最后一个被 keep-alive 缓存住的数据。 查了很多资料上说使用 activated() 钩子去清除缓存,重新请求数据。请问要怎么做呢? 我的需求是每次切换 tab,需要保留缓存数
-
将线程本地内存刷新到全局内存是什么意思?
问题内容: 我知道Java中的易失性变量的目的是使对此类变量的写入对其他线程立即可见。我还知道,同步块的作用之一是将线程本地内存刷新到全局内存。 在这种情况下,我从未完全理解对“线程本地”内存的引用。我了解仅存在于堆栈中的数据是线程局部的,但是当谈论堆上的对象时,我的理解变得模糊。 我希望能就以下几点发表评论: 在具有多个处理器的计算机上执行时,刷新线程本地内存是否仅是指将CPU缓存刷新到RAM中
-
不带任何内容且不返回任何内容的功能接口
问题内容: JDK中是否有一个标准的功能接口,该接口什么都不做,什么也不返回?我找不到一个。类似于以下内容: 问题答案: 那么Runnable呢:
-
mySQL在y范围内的x公里/英里内选择邮政编码
问题内容: 注意:尽管我将邮政编码数据库与荷兰邮政编码一起使用,但是此问题与国家/地区无关。 我有一个数据库,其中包含荷兰的每个邮政编码及其x和y坐标(纬度/经度)。 例如,我的邮政编码:具有以下坐标: 现在,我想使用from查找其他所有邮政编码。 例如: 问题在于地球并不完全是圆形的。我发现很多关于计算的教程,但这不是我所需要的。 有人有什么主意吗? 更新 感谢Captaintokyo,我发现了
-
淡出内容为A的div,淡入内容为B的同一个div
问题内容: 我有以下几点: 这样几乎可以。问题是…效果不流畅。我的意思是,首先淡出内容A,然后保持空白,然后淡入内容B。 我想要的是减轻这种影响,以便当他确实快要消失时,他开始淡入,以便使效果平滑。 关于下面的代码如何实现? 非常感谢,MEM 问题答案: 试试这个: 因此,只有在检索到数据后才会产生效果,从而避免了等待数据响应的时间间隔。
-
操作系统中虚拟内存和缓存内存之间的区别
本文向大家介绍操作系统中虚拟内存和缓存内存之间的区别,包括了操作系统中虚拟内存和缓存内存之间的区别的使用技巧和注意事项,需要的朋友参考一下 在这篇文章中,我们将了解操作系统中虚拟内存和缓存内存之间的区别- 高速缓存存储器 它有助于提高CPU的访问速度。 它是提高访问速度的存储单元。 CPU和其他相关硬件有助于管理缓存。 尺寸很小。 它用于存储最近使用的数据。 虚拟内存 它增加了主存储器的容量。 这
-
IE8 内存泄露(内存一直增长 )的原因及解决办法
本文向大家介绍IE8 内存泄露(内存一直增长 )的原因及解决办法,包括了IE8 内存泄露(内存一直增长 )的原因及解决办法的使用技巧和注意事项,需要的朋友参考一下 最近开发的时候对页面使用了定时的局部更新,结果在ie6,7和Firefox下,一切正常,而在ie8下过上几个小时就浏览器就崩溃了,显示是内存溢出,我以为是代码写的不好导致内存泄露,但是ie6,7又正常,调查了一下,原来这是ie8的bug
-
内联空格addWG(任务任务)vs内联空格addWG(常量任务
我曾经通过
-
如何连接到应用程序内docker容器内wsl2从Windows主机?
在Windows上: 我刚刚通过创建了应用程序,并为此创建了Dockerfile: 然后我打开wsl2,进入并构建了并启动了它。 我看到它在跑 还有正确的日志: 但是我不确定我怎么能连接到它?
-
为什么我的内部联接查询没有返回任何内容?
我有两张桌子锻炼和练习。我正在尝试使用与我们点击的锻炼匹配的workout_id获取所有锻炼。我做了一个内部联接查询,但它似乎没有返回任何东西。我的查询有问题吗? 我正在使用SQLite创建我的数据库。我已经检查了,以确保练习表中有练习,并且它们有一个workout_id。 2)回到我的WorkoutProvider类中,我将selectionArgs设置为: 并把它传递到我的RawQuery中。
-
RxJava 2.0-如何从可完成的内容发出可观察的内容
假设我有 我要实现的是一个流,它在doTask()完成后发出一个just(“completed”)项。 对于Observable,我可以执行doTask().map(f->just(“completed”));但是,如果它在完成的过程中没有散发出任何自然的东西,我怎么能做到完全的呢?
-
PHP内存不足错误不反映PHP.ini中的内存限制设置
当我尝试使用Composer客户端将软件包安装到Contao时,我收到一个错误: 致命错误:第220行的phar://D:/wamp/www/myproject/composer/composer.phar/src/composer/dependencysolver/Solver.php中允许的内存大小为1073741824字节(尝试分配134217728字节) 我真的很困惑。我的PHP内存限制设
-
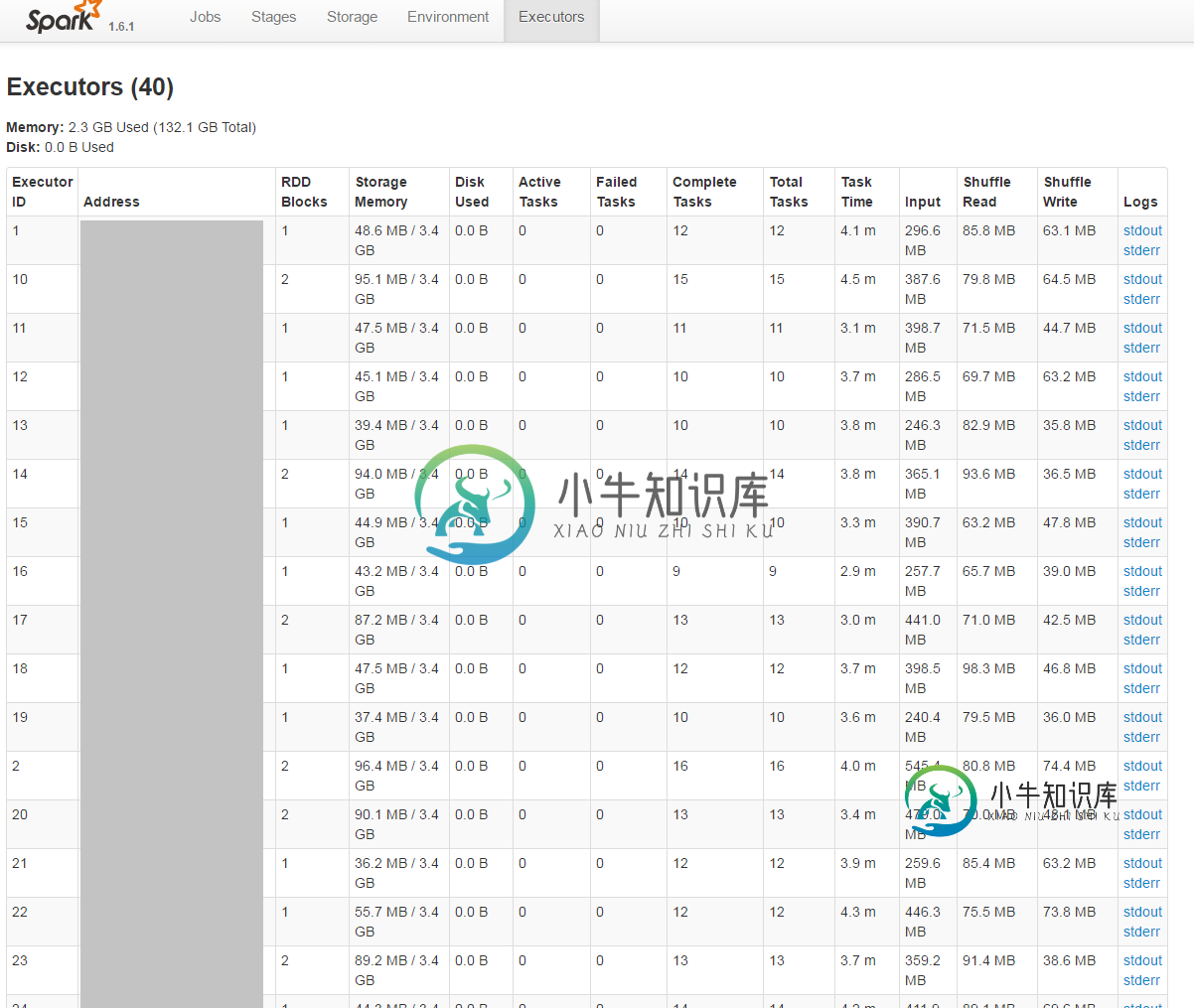 Spark on Yarn:执行器内存少于通过spark-submit设置的内存
Spark on Yarn:执行器内存少于通过spark-submit设置的内存我在纱线簇(HDP 2.4)中使用Spark,设置如下: 1主节点 64 GB RAM(48 GB可用) 12核(8核可用) 每个64 GB RAM(48 GB可用) 每个12核(8核可用) null
-
Jupyter笔记本无法从nb_conda_内核中找到conda环境的内核
我为不同的Python项目使用不同的conda环境,并且习惯于在Jupyter笔记本中愉快地使用nb_conda_kernels来访问这些环境的内核。它们将在“新”下拉列表中提供,名称类似于“Python[conda env: project]。经过一些更新后,这些内核都没有出现在Jupyter中,当我试图打开一个使用这些内核之一的笔记本时,我得到内核未找到-找不到匹配Python[conda e
-
如何处理Spark中的执行器内存和驱动程序内存?
null null 为了进行简单的开发,我使用在独立集群模式下(8个工作者、20个内核、45.3G内存)执行了我的Python代码。现在我想为性能调优设置执行器内存或驱动程序内存。 在Spark文档中,执行器内存的定义是 每个执行程序进程使用的内存量,格式与JVM内存字符串相同(例如512M、2G)。