《Keep内推》专题
-
什么是内网穿透?
内网穿透是我们在进行网络连接时的一种术语,也叫做NAT穿透,内网穿透的功能就是,当我们在端口映射时设置时,内网穿透起到了地址转换的功能。 内网穿透的原理很简单的说就是: 两台计算机A和B都处于不同的局域网中,A想要访问B, 就需要通过一台服务器做桥接的,桥接的方式有两种,一种是服务器相互转发流量 到A和B,另一种是告诉对方公网IP地址,自己充当一个介绍人的角色, 专业术语叫DNAT目标地址转换。
-
实验二:内存分配
实验二:内存分配 实验之前 阅读实验指导二。 checkout 到仓库中的 lab-2 分支,实验题将以此展开。 实验题 原理:.bss 字段是什么含义?为什么我们要将动态分配的内存(堆)空间放在 .bss 字段?Click to show 对于一个 ELF 程序文件而言,.bss 字段一般包含全局变量的名称和长度,在执行时由操作系统分配空间并初始化为零。 不过,在我们执行 rust-objcop
-
实现内核重映射
实现内核重映射 在上文中,我们虽然构造了一个简单映射使得内核能够运行在虚拟空间上,但是这个映射是比较粗糙的。 我们知道一个程序通常含有下面几段: .text 段:存放代码,需要可读、可执行的,但不可写; .rodata 段:存放只读数据,顾名思义,需要可读,但不可写亦不可执行; .data 段:存放经过初始化的数据,需要可读、可写; .bss 段:存放零初始化的数据,需要可读、可写。 我们看到各个
-
第五章 内存控制
也许读者会好奇为何会有这样一章存在于本书中,因为在过去很长一段时间内,JavaScript 开发者很少在开发过程中遇到需要对内存精确控制的场景,也缺乏控制的手段。说到内存泄漏,大家首先想起的也是在早期版本的 IE 中 JavaScript 与 DOM 交互时发生的问题。如果页面里的内存占用过多,基本等不到进行代码回收,用户已经不耐烦地刷新了当前页面。 随着 Node 地发展,JavaScript
-
3.2 更新属性内容
操作步骤: ●单条字段属性更新 ①在"图层管理"模块,选择一个带有数据的图层,点击"数据视图"。 ②双击击字段属性内容,进入编辑状态,进行编辑。 ③编辑完成后点击"确定"按钮,属性内容更新成功。 提示: ●批量更新属性内容。 操作动图: [查看原图]
-
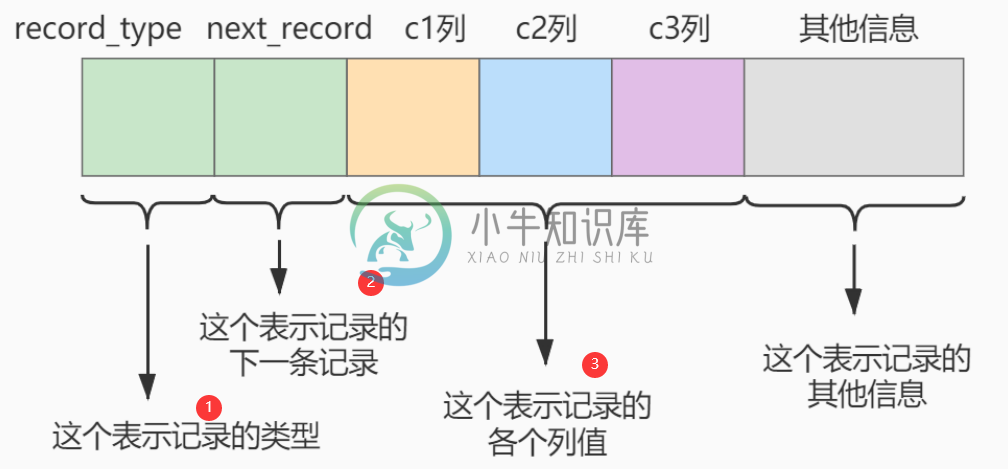 MySQL索引内部原理
MySQL索引内部原理主要内容:一、索引概述,二、设计索引,引入目录项,三、常见索引概念,1. 聚簇索引,2. 二级索引(辅助索引、非聚簇索引),3.联合索引,4.MyISAM中的索引,5.MyISAM与InnoDB对比,四、B-Tree和B+Tree对比一、索引概述 索引即一本书的目录,我们通过书的目录能够快速的查到对应文章的页码。数据库的索引也差不多,通过在某些字段建立索引,可以快速的查找某些特定的数据,避免全表搜索。 因为数据库表的数据在磁盘文件中,会将对应数据读取到内存中进行检索,全表搜索会带来更多的IO操作
-
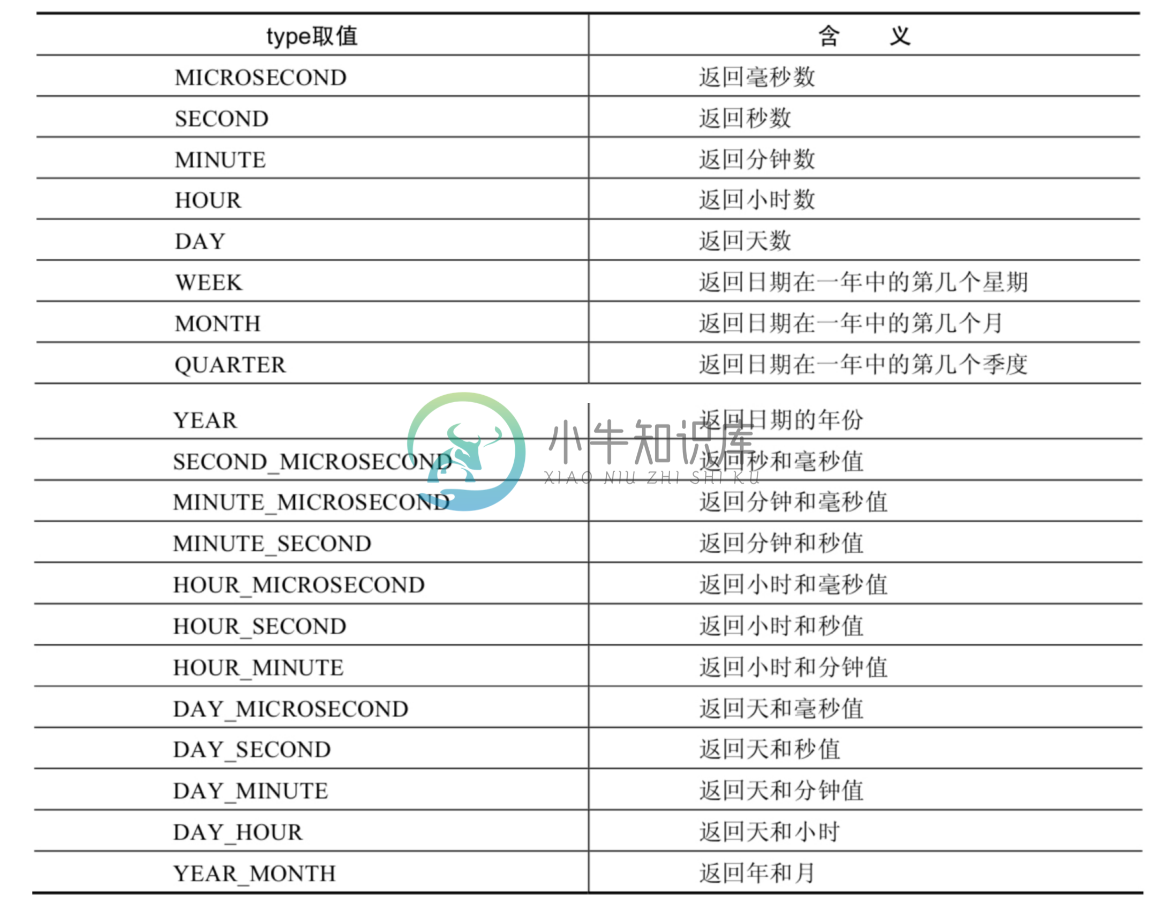 mysql常用内置函数
mysql常用内置函数主要内容:1.数值函数,1.1基本函数,1.2角度和弧度互函数,1.3三角函数,1.4指数和对数,1.5进制间的转换,3.1获取日期、时间,3.2 日期与时间戳的转换,3.3 获取月份、星期、星期数、天数等函数,3.4 日期的操作函数,3.5 时间和秒钟转换的函数,3.6 计算日期和时间的函数,分组函数MySQL提供的内置函数从实现的功能角度可以分为数值函数、字符串函数、日期和时间函数、流程控制函数、加密与解密函数、获取MySQL信息函数、聚合函数等 这里,我将这些丰富的内置函数再分为两类: 单
-
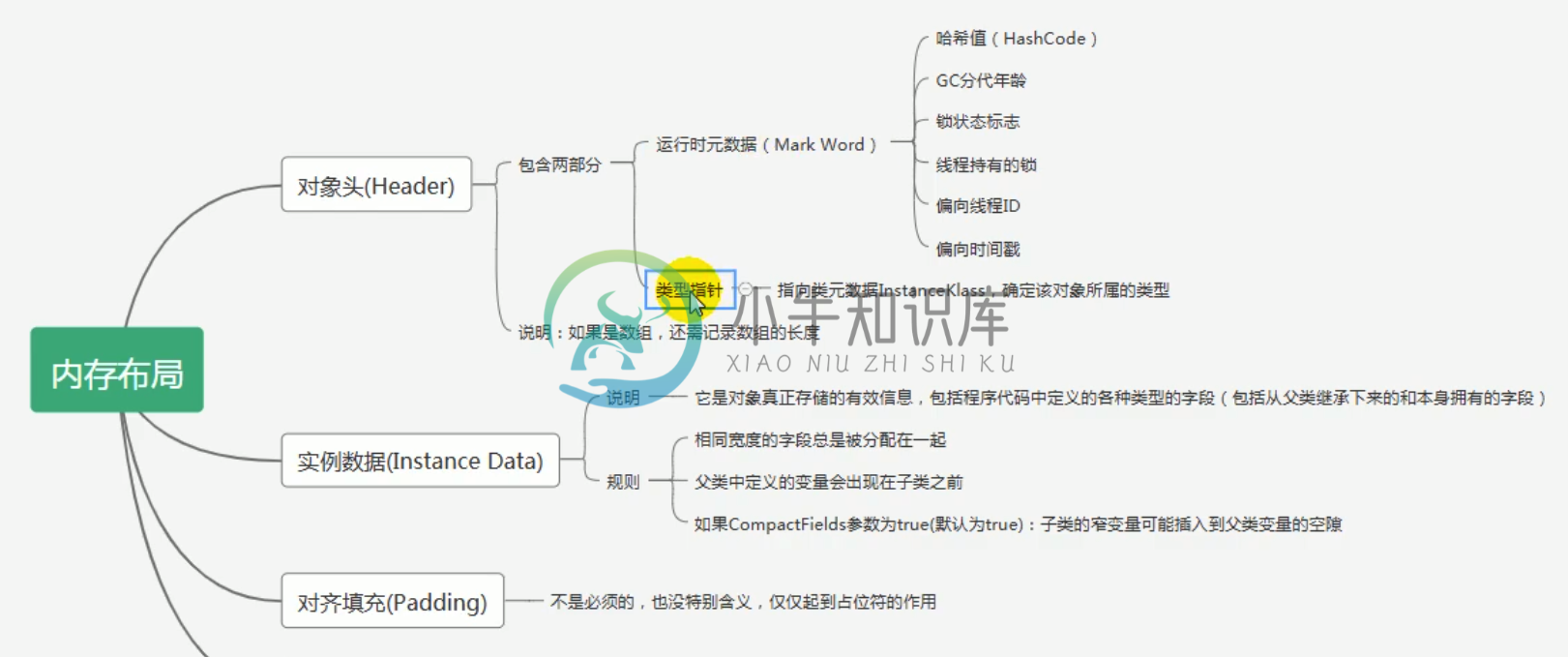 对象的内存分布
对象的内存分布jvm的对象头是如何存储的? 对象头中有哪些信息? 对象头里面的东西:运行时元数据,类型指针:Hashcode,GC分代年龄,锁状态标志,线程持有的锁,偏向线程ID,偏向时间戳。如果是数组的化还需要记录长度 就比如下面的代码来看,内存分布情况: 由于是static的main方法所有局部变量表没有this,如果是非静态方法的话第一个放this。 其次: 栈帧:局部变量表,操作数栈,动态链接,方法返回
-
给内容主题 Theming content
页面的主题内容区域(标有 data-role="content"属性的容器),应该通过给data-role="page"属性的容器增加 data-theme属性来确保不管页面多高背景色都能够在整个页面都应用到 (如果你只为data-role="content"容器添加了data-theme属性,则背景色会在内容结束部分停止,可能会造成固定尾部栏和内容之间产生留白 <div data-role="p
-
Linux 内核的通知链
Introduction The Linux kernel is huge piece of C) code which consists from many different subsystems. Each subsystem has its own purpose which is independent of other subsystems. But often one subsyst
-
Java-将数组存储到内存或从内存上传到磁盘
问题内容: 我有一个长度为2.2亿(固定)的int和float数组。现在,我想将这些阵列存储到内存和磁盘/从内存和磁盘上载。目前,我正在使用Java NIO的FileChannel和MappedByteBuffer解决此问题。它可以正常工作,但大约需要5秒钟(Wall Clock Time)(用于将阵列存储到内存或从内存上载到磁盘或从磁盘上载到磁盘)。实际上,我想要一个更快的。有人可以帮我吗,有没
-
获取“ Java堆空间”和“内存不足”时的Eclipse内存设置
问题内容: 尝试在Eclipse中启动和运行flex / java项目时,我一直使用Eclipse,Tomcat和JRE收到“内存不足异常”和“ Java堆空间”。 在研究尝试调整内存设置时,我发现了三个地方来调整这些设置: Eclipse.ini 窗口>首选项下的JRE设置 Catalina.sh或Catalina.bat 在这些不同位置设置-xms和-xmx有什么区别,这是什么意思? 有什么方
-
如果刷新AJAX请求的内容(ob_flush),将加载该内容吗?
问题内容: 我的意思是……让我们只是发出AJAX请求,然后将结果插入div#result中。 在后端脚本中,使用 ob_flush() 发送标头,但直到请求终止(使用 exit 或 ob_flush_end )后才终止请求 仅当请求终止( exit 或 ob_flush_end )时,内容才会加载到#result中,否则,每次脚本由 ob_flush 发送标头时,内容都会加载到 #result中
-
C中静态内存分配与动态内存分配的成本
问题内容: 当您知道on上对象/项目的确切数量时,我非常想知道哪种内存分配方法对性能(例如,运行时间)有利,这对性能有好处。少量对象(少量内存)和大量对象(大量内存)的成本。 与 请告诉我。谢谢。 注意:我们可以对此进行基准测试,并且可能知道答案。但是我想知道解释这两种分配方法之间性能差异的概念。 问题答案: 静态分配将更快。静态分配可以在全局范围和堆栈上进行。 在全局范围内,静态分配的内存内置在
-
何时在Linux内核中使用内核线程vs工作队列
问题内容: 在Linux内核中有许多安排工作的方法:计时器,tasklet,工作队列和内核线程。什么时候使用一个对另一个的准则是什么? 有明显的因素:计时器功能和小任务无法进入睡眠状态,因此它们无法等待互斥量,条件变量等。 在驱动程序中为我们选择哪种机制的其他因素是什么? 首选的机制是什么? 问题答案: 如您所说,这取决于手头的任务: 工作队列将工作推迟到内核线程中-您的工作将始终在流程上下文中运