《深圳》专题
-
 JavaScript函数的特性与应用实践深入详解
JavaScript函数的特性与应用实践深入详解本文向大家介绍JavaScript函数的特性与应用实践深入详解,包括了JavaScript函数的特性与应用实践深入详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript函数的特性与应用实践。分享给大家供大家参考,具体如下: 函数用于指定对象的行为。所谓的编程,就是将一组需求分解为一组函数和数据结构的技能。 1 函数对象 JavaScript 函数就是对象。对象是名值对的集
-
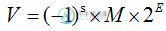 C++中double浮点数精度丢失的深入分析
C++中double浮点数精度丢失的深入分析本文向大家介绍C++中double浮点数精度丢失的深入分析,包括了C++中double浮点数精度丢失的深入分析的使用技巧和注意事项,需要的朋友参考一下 看了一篇关于C/C++浮点数的博文,在Win32下,把int, 指针地址,long等4字节整数赋给一个double后,再用该double数赋给原始类型的数,得到的结果于最初的数值一致,即不存在任何精度丢失。例如下面的结果将总是true: 但是对于l
-
深入理解Bash中的尖括号(适合初学者)
本文向大家介绍深入理解Bash中的尖括号(适合初学者),包括了深入理解Bash中的尖括号(适合初学者)的使用技巧和注意事项,需要的朋友参考一下 前言 Bash 内置了很多诸如 ls、cd、mv 这样的重要的命令,也有很多诸如 grep、awk、sed 这些有用的工具。但除此之外,其实 Bash 中还有很多可以起到胶水作用的标点符号,例如点号(.)、逗号(,)、括号(<>)、引号(")之类。下面我们
-
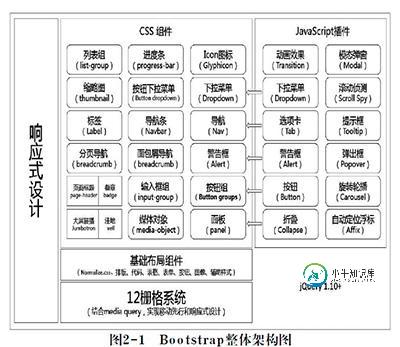 深入理解bootstrap框架之第二章整体架构
深入理解bootstrap框架之第二章整体架构本文向大家介绍深入理解bootstrap框架之第二章整体架构,包括了深入理解bootstrap框架之第二章整体架构的使用技巧和注意事项,需要的朋友参考一下 一. 整体架构 1. CSS-12栅格系统 把网页宽度均分为12等分(保留15位精度)——这是bootstrap的核心功能。 2.基础布局组件 包括排版、按钮、表格、布局、表单等等。 3.jQuery bootstrap插件的基础 4.响应式设
-
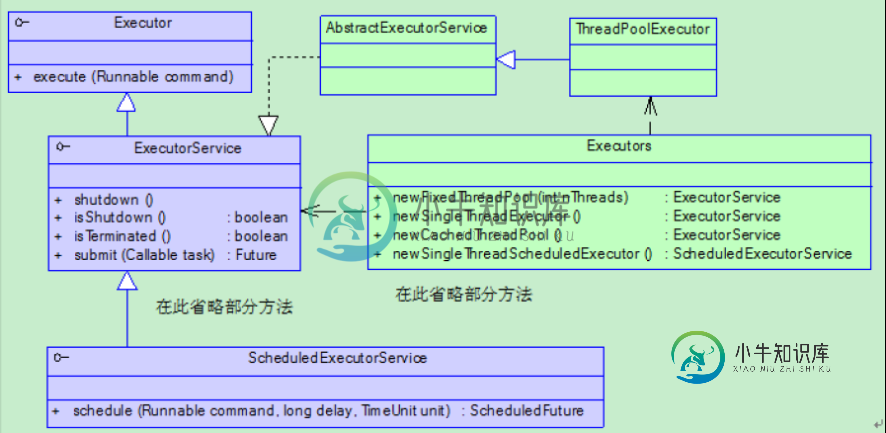 Java并发之线程池Executor框架的深入理解
Java并发之线程池Executor框架的深入理解本文向大家介绍Java并发之线程池Executor框架的深入理解,包括了Java并发之线程池Executor框架的深入理解的使用技巧和注意事项,需要的朋友参考一下 线程池 无限制的创建线程 若采用"为每个任务分配一个线程"的方式会存在一些缺陷,尤其是当需要创建大量线程时: 线程生命周期的开销非常高 资源消耗 稳定性 引入线程池 任务是一组逻辑工作单元,线程则是使任务异步执行的机制。当存在大量并发任
-
JavaScript继承的特性与实践应用深入详解
本文向大家介绍JavaScript继承的特性与实践应用深入详解,包括了JavaScript继承的特性与实践应用深入详解的使用技巧和注意事项,需要的朋友参考一下 本文详细讲述了JavaScript继承的特性与实践应用。分享给大家供大家参考,具体如下: 继承是代码重用的模式。JavaScript 可以模拟基于类的模式,还支持其它更具表现力的模式。但保持简单通常是最好的策略。 JavaScript 是基
-
深入解析Backbone.js框架的依赖库Underscore.js的作用
本文向大家介绍深入解析Backbone.js框架的依赖库Underscore.js的作用,包括了深入解析Backbone.js框架的依赖库Underscore.js的作用的使用技巧和注意事项,需要的朋友参考一下 backbone必须依赖underscore.js才能够使用,它必须通过underscore中的函数来完成访问页面元素、处理元素的基本操作。 注:backbone可以很好的与其它js库一起
-
如何删除node_modules-Windows中的深度嵌套文件夹
问题内容: 尝试删除以下 用户 创建的 node_modules 目录时: 源文件名大于文件系统支持的文件名。尝试移动到路径名较短的位置,或尝试重命名为较短的名称,然后再尝试执行此操作 我也尝试过+ ,但仍然遇到相同的问题。 问题答案: 由于这是Google的最佳搜索结果,因此这对我有用: 安装RimRaf: 在项目文件夹中,使用以下命令删除node_modules文件夹: 如果要递归删除: [
-
JavaScript 基础函数_深入剖析变量和作用域
本文向大家介绍JavaScript 基础函数_深入剖析变量和作用域,包括了JavaScript 基础函数_深入剖析变量和作用域的使用技巧和注意事项,需要的朋友参考一下 函数定义和调用 定义函数,在JavaScript中,定义函数的方式如下: 上述abs() 函数的定义如下: function 指出这是一个函数定义; abs 是函数的名称; (x) 括号内列出函数的参数,多个参数以,分隔; {...
-
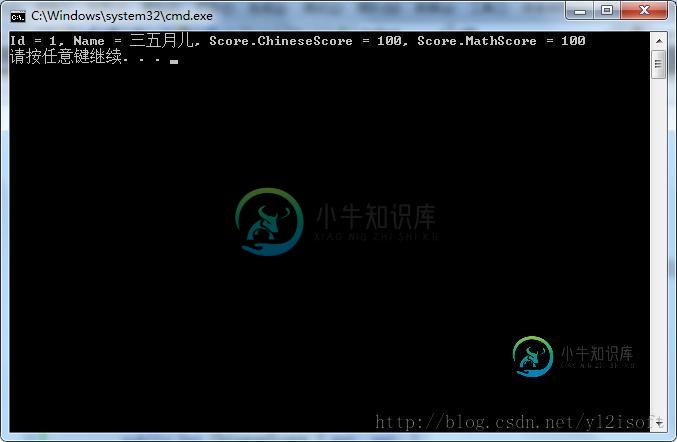 C#中使用DataContractSerializer类实现深拷贝操作示例
C#中使用DataContractSerializer类实现深拷贝操作示例本文向大家介绍C#中使用DataContractSerializer类实现深拷贝操作示例,包括了C#中使用DataContractSerializer类实现深拷贝操作示例的使用技巧和注意事项,需要的朋友参考一下 一、实现深拷贝方法 二、测试深拷贝方法 2.1 书写测试代码 代码中先实例化Student类得到对象s,再使用本文给出的拷贝方法将其拷贝至对象s1并输出s1的内容,s1的内容是不是和s的内
-
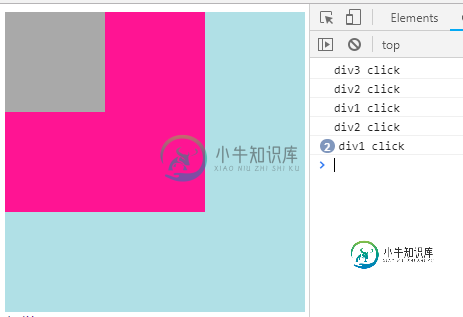 深入理解JS的事件绑定、事件流模型
深入理解JS的事件绑定、事件流模型本文向大家介绍深入理解JS的事件绑定、事件流模型,包括了深入理解JS的事件绑定、事件流模型的使用技巧和注意事项,需要的朋友参考一下 一、JS事件 (一)JS事件分类 1.鼠标事件: click/dbclick/mouseover/mouseout 2.HTML事件: onload/onunload/onsubmit/onresize/onchange/onfoucs/onscroll 3.键盘
-
深入解析Java编程中的boolean对象的运用
本文向大家介绍深入解析Java编程中的boolean对象的运用,包括了深入解析Java编程中的boolean对象的运用的使用技巧和注意事项,需要的朋友参考一下 只能是true或false两个值之一的变量就是布尔(boolean)类型变量,true和false是布尔型直接量。你可以用下面的语句定义一个名称为state的布尔型变量: 该语句用true值对变量state进行了初始化。你也可以使用
-
 深入解析Go语言编程中slice切片结构
深入解析Go语言编程中slice切片结构本文向大家介绍深入解析Go语言编程中slice切片结构,包括了深入解析Go语言编程中slice切片结构的使用技巧和注意事项,需要的朋友参考一下 数组转换成切片 slice测试 我们看到这样的是slice_a指向Array_ori 其实是从c指向到k 我们用fmt.Println(cap(slice_a)) 结果肯定不是3 自己动手试一下下边这个 slice是指向底层的数组,如果多个slice指
-
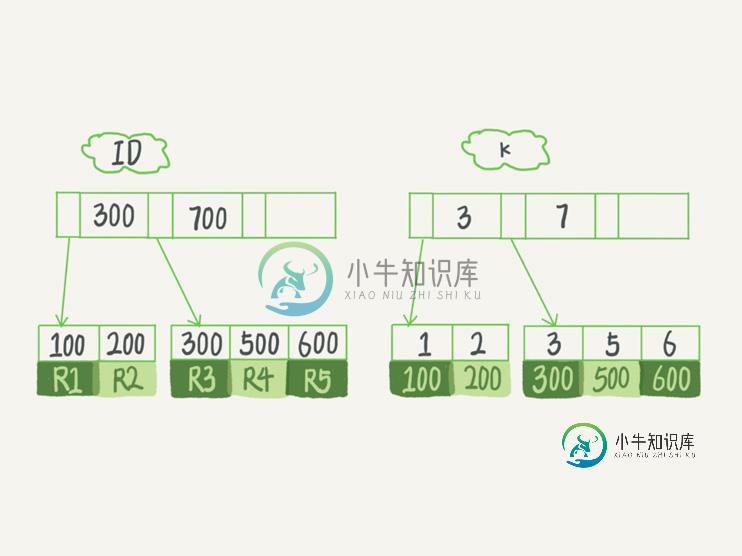 MySQL普通索引和唯一索引的深入讲解
MySQL普通索引和唯一索引的深入讲解本文向大家介绍MySQL普通索引和唯一索引的深入讲解,包括了MySQL普通索引和唯一索引的深入讲解的使用技巧和注意事项,需要的朋友参考一下 场景 1、维护一个市民系统,有一个字段为身份证号 2、业务代码能保证不会写入两个重复的身份证号(如果业务无法保证,可以依赖数据库的唯一索引来进行约束) 3、常用SQL查询语句:SELECT name FROM CUser WHERE id_card = 'XX
-
 深入学习nodejs中的async模块的使用方法
深入学习nodejs中的async模块的使用方法本文向大家介绍深入学习nodejs中的async模块的使用方法,包括了深入学习nodejs中的async模块的使用方法的使用技巧和注意事项,需要的朋友参考一下 最近在学习nodejs,这两天学习了async模块这个地方知识点挺多的,所以,今天添加一点小笔记。 async模块是为了解决嵌套金字塔,和异步流程控制而生.常用的方法介绍 npm 安装好async模块,然后引入就可以使用 var async