《深圳》专题
-
JS深入学习之数组对象排序操作示例
本文向大家介绍JS深入学习之数组对象排序操作示例,包括了JS深入学习之数组对象排序操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS深入学习之数组对象排序功能。分享给大家供大家参考,具体如下: JavaScript实现多维数组、对象数组排序,其实用的就是原生的sort()方法,用于对数组的元素进行排序。 sort() 方法用于对数组的元素进行排序。语法如下: arrayObjec
-
面向对象深度优先和广度优先是什么?
本文向大家介绍面向对象深度优先和广度优先是什么?相关面试题,主要包含被问及面向对象深度优先和广度优先是什么?时的应答技巧和注意事项,需要的朋友参考一下
-
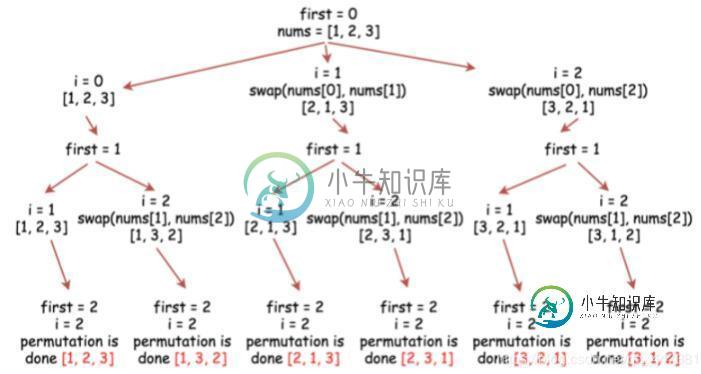 python实现全排列代码(回溯、深度优先搜索)
python实现全排列代码(回溯、深度优先搜索)本文向大家介绍python实现全排列代码(回溯、深度优先搜索),包括了python实现全排列代码(回溯、深度优先搜索)的使用技巧和注意事项,需要的朋友参考一下 从n个不同元素中任取m(m≤n)个元素,按照一定的顺序排列起来,叫做从n个不同元素中取出m个元素的一个排列。当m=n时所有的排列情况叫全排列。 公式:全排列数f(n)=n!(定义0!=1) 1 递归实现全排列(回溯思想) 1.1 思想 举个
-
浅谈Java中实现深拷贝的两种方式—clone() & Serialized
本文向大家介绍浅谈Java中实现深拷贝的两种方式—clone() & Serialized,包括了浅谈Java中实现深拷贝的两种方式—clone() & Serialized的使用技巧和注意事项,需要的朋友参考一下 clone() 方法麻烦一些,需要将所有涉及到的类实现声明式接口 Cloneable,并覆盖Object类中的clone()方法,并设置作用域为public(这是为了其他类可以使用到该
-
DFS:使用深度优先搜索(java)查找节点路径
我有一棵树。此树中的所有节点都有一些真/假值、一个元素和父/子指针。此树中的一个元素的true/false值设置为true。我想找到从根到这个唯一节点的路径(元素序列)。如果我的树是这样的: 特殊节点是H,我的算法将返回字符串“ACEGH”。我已经使用DFS实现了这一点。但是,我当前的算法是从错误路径添加节点元素。因此,我当前的算法将返回:“ABDCEFGHI”。
-
OpenGL:将FBO的深度纹理绑定到计算着色器
我一直在尝试渲染到一个FBO,并将两个FBO渲染到屏幕上,但在合并两个FBO时进行深度测试失败。我尝试使用计算着色器合并纹理,但无法读取深度纹理的值(所有值都是值1,但渲染到FBO时深度测试有效)。有人知道我做错了什么,或者知道其他方法来合并两个FBO吗? 以下是我创建FBO的方式: 以下是我向FBO渲染的方式: 我尝试用glBindTexture绑定纹理(所有值均为1): 计算着色器: 我已尝试
-
具有巨大深度的根树-DFS遍历算法性能
今天,我学习了根树的3次DFS(深度优先搜索)遍历,即按顺序、预顺序 例如,如果我考虑前序遍历, 然后按以下顺序访问节点, 实际上,在NMS(网络管理系统)应用程序中,我们使用根树(representation)来维护网络元素(度量)的层次结构,其中叶节点的深度非常大。 渐近地,预序遍历的空间复杂度是,其中d是最低叶的深度。 在应用这三种遍历中的任何一种时,由于堆栈溢出,应用程序很有可能崩溃。 例
-
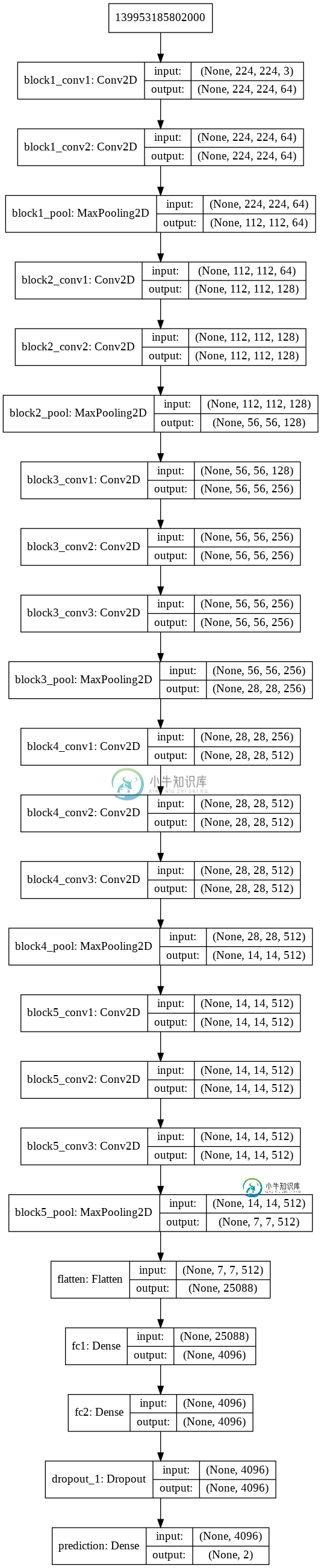 输入层从深度学习模型的结构中消失
输入层从深度学习模型的结构中消失我使用以下代码使用VGG16创建CNN模型,但创建模型后,模型的输入层从结构中消失(见图)。 为什么输入层会从结构中消失? 模型结构
-
保持二叉搜索树节点深度属性的更新
删除某些内容后,如何保持二叉搜索树节点的深度属性更新?
-
 W3中的第一个菜单项默认为深灰色。CSS
W3中的第一个菜单项默认为深灰色。CSS如图所示,第一个菜单项默认为深灰色,尽管我没有在任何地方指定。我想这意味着即使没有鼠标,它也会处于活动状态。 所需行为:除非鼠标悬停,否则整个菜单栏为浅灰色 W3学校表示: 带下拉框的导航栏注意:当下拉框“打开”时,下拉链接会获得灰色背景颜色,以指示其处于活动状态。要重写这个,添加一个w3悬停颜色类到"下拉"li和a: 这是我的html代码 任何帮助都将不胜感激
-
层深超过2的嵌套方法中的异常处理
因为我在C()捕获异常,并且只使用日志记录来处理它,而在B()中没有任何捕获,所以我在A()捕获异常吗? 还是应该在C()抛出异常,并在B()添加try catch以便能够在a()中处理它?
-
迭代深度优先搜索查找字符串(2D数组)
我试图创建一个boggle游戏的迭代方法。该类包含一个名为“Board”的2D字符串数组的字段,并有一个名为“HaveVisit”的2D布尔数组。调用test2的方法遍历整个板,查找目标字符串第一个字符的位置,然后将坐标传递给test2方法,返回一个包含坐标的列表。 return1Index方法获取一个2D数组坐标at,创建一个int表示对应的1D数组的坐标。return2DIndex则相反,返回
-
使用动态/深度链接与Firebase电子邮件验证?
我正在使用RNfirebase与我的react-native应用程序。我可以得到电子邮件验证链接来打开我的应用程序,但仅此而已。我知道我需要访问链接并解析它以获得oobCode并将其应用于用户。但是,当我使用该链接打开应用程序时,我从'react-native'中使用{Linking}触发的监听器似乎没有检测到该URL。我想将他们重定向到“感谢您验证您的电子邮件”页面,以及使用由Firebase生
-
spark提交抛纱pyspark脚本超过最大递归深度
我可以在spark submit yarn-cluster模式下提交org.apache.spark.examples.sparkpi示例jar,它成功了,但是pyspark中的下面的代码片段失败了,最大递归深度超过了错误。 在纱线集群模式下,我根据Pyspark的建议添加了pyspark_python env test.py 怎么解决这个? 运行Spark 1.6.0版 配置单元,版本1.1.0
-
超出了给定最大更新深度的setState的React Refs。
嗨,伙计们,我试着使用Refs并给出在其内部,但它给出: 超过最大更新深度。当组件在componentWillUpdate或componentDidUpdate内重复调用setState时,可能会发生这种情况。React限制嵌套更新的数量,以防止无限循环。 我在做什么: 但当我使用时: 它的工作原理。 在其他组件中,我使用也很好,有人为什么?