《达实智能》专题
-
 如何在智能J上更改科特林编译器版本?
如何在智能J上更改科特林编译器版本?在IntelliJ中,您可以像这样设置目标Java版本: 不幸的是,我找不到一个地方可以为科特林做同样的事情。这使得我无法使用类星体科特林。我想切换到M14,即使我安装了1.0测试版。我怎样才能换回? 更改文件返回M14我的项目中遇到编译错误。 我的< code > build . gradle :https://gist.github.com/Jire/5b517fd767ad498bc18f
-
无法在智能手机上安装Flutter应用程序[副本]
我是个初学者,如果这是个垃圾问题,我很抱歉。 我该如何解决这个问题?我没有安装的应用程序了,所以我不知道它如何不能与以前安装的版本匹配。
-
为FHIR设置智能应用程序并利用现有资源
我正在学习如何在FHIR上构建一个智能应用程序来访问EHR。我正在查阅可用的文件和阅读材料,但有一件事我不清楚。 有没有一种方法,我可以访问现有的病人的数据,即。我跳过创建和上传FHIR数据/资源的部分,只是验证和利用存量数据? 有什么服务可以提供吗?
-
 联影智能-AI医疗软件-产品经理面试经历
联影智能-AI医疗软件-产品经理面试经历联影是医学影像的国内龙头,还是不错滴,据说公司有点加班文化。 一、联影医疗-产品经理一面 1.中文自我介绍 2.你之前在市场部实习的时候,竞品分析主要做了哪些工作?有什么心得体会? 3.你对联影医疗有什么了解?你知道我们有哪些产品吗?你对影像学的知识了解多少? 4.你对产品经理的认知 由于面试没有准备,直接挂了。 两周后被联影智能捞起来了,咱就是非常感恩 二、联影智能 1、产品经理一面 主要针对简
-
 23秋招 阿里 商业智能 数据分析 过经挂经?
23秋招 阿里 商业智能 数据分析 过经挂经?9.28晚上十点电话没接到-9.29下午四点电话没接到-9.29晚上十点半约9.30面试 电话面 35min 自我介绍 讲了两个实习项目均没有深入提问 机器学习 -讲两个无监督 两个有监督学习算法 -讲的算法优缺点都是什么 -过拟合怎么处理 -知道决策树ID3吗 讲一下信息增益的公式 数据分析使用什么工具 sql:每个商家近三个月最大的三笔订单 python:给你一个数列怎么转换成数组 用哪个库的
-
 WBC-Liquid 智能合约编程语言软件 中文文档 v1.0.0
WBC-Liquid 智能合约编程语言软件 中文文档 v1.0.0不断多样化、复杂化的应用场景为智能合约编程语言带来了全新挑战:分布式、不可篡改的执行环境要求智能合约具备更强的隐私安全性与鲁棒性;日渐扩大的服务规模要求智能合约能够更加高效运行;智能合约开发过程需要对开发者更加友好。
-
人工智能背景下的Office 365现状和发展趋势
作者:陈希章 发表于 2017年7月31日 引子 谈论人工智能是让人兴奋的,因为它具有让人兴奋的两大特征 —— 每个人都似乎知道一点并且以知道一点为荣,但又好像没多少人能真正讲的明白。毫无疑问,我也仅仅是知道一点点,这一篇文章试图想通过比较接地气的方式给一部分人讲明白。这还得说要感谢这样一个时代,换做是几年前我是绝不敢造次的 —— 那时虽然人工智能并不稀奇,但大抵都是王谢堂前的燕儿,而如今随着技术
-
 宁德时代-无损探测智能开发工程师 面试
宁德时代-无损探测智能开发工程师 面试20分钟,面试官很专业,项目延申问题也很专业 1.自我介绍 2.项目介绍,项目问题延申(某些点怎么考虑的) 3.项目没有深度学习,问有没有相关经历 4.yolo系列的特征金字塔,好处是什么 5.残差结构在算法上的理解?(说的能保证不至于更差,面试官说都这样说,问怎么在算法上理解) 6.C++了解吗,做过哪些项目 7.如果开发一个上位机需要调用监控,怎么解决内存占用问题? 8.反问,忘了问什么时候有
-
 中科曙光 人工智能研发工程师 一面面经
中科曙光 人工智能研发工程师 一面面经总体二十多分钟 1.先问了一下基础情况,然后做自我介绍 2.拷问实习项目,主要问我数据怎么做的、数据分布怎么调整,然后不知道怎么跳到文本分类的样本分布上了,问我文本分类样本不均衡怎么做;然后问我模型训练怎么做的,让我介绍一下deepspeed框架、vllm框架 3.拷问我rag的项目,问我两路召回中这两路有什么区别、rerank的作用、selfrag是什么、模型推理时延 4.拷问我的论文项目,主要
-
人工智能 - 有无这样的audio to text接口可以用?
这段代码运行了,得到满意的输出,但是有不好的地方:google的服务,其他接口都是国外的(如ibm等). 有无这样的audio to text工具? 1.中国产 2.免费 (收费的就不要推了) 3.有python接口
-
 阿里智能信息二面挂,至此暑期无缘阿里
阿里智能信息二面挂,至此暑期无缘阿里阿里信息二面 6.1--- 最汗流浃背的一集,先是自我介绍,然后问了一下职业规划。 ①一个线程和协程之间区别 ②协程的两种类型(这我真不会) 之后就是两道场景题手撕 ①给定一个input文件,文件中有大量的不重复的数字,数字的范围不超过七位数,内存空间只给2MB,如何排序后输出到一个ouput文件中。 这里我首先说用归并排序的思想来做,每次从文件中读取2MB数据到内存中进行排序,再将文件输出到一个
-
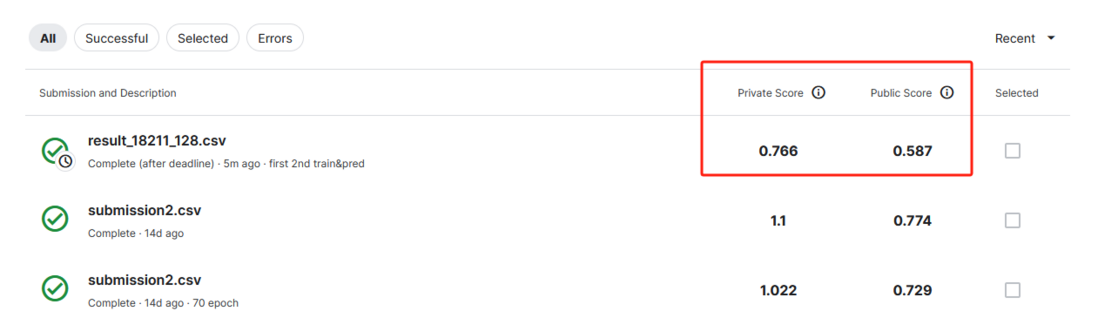 人工智能 - 如何比较Kaggle上late submission与leaderboard的分数?
人工智能 - 如何比较Kaggle上late submission与leaderboard的分数?kaggle上late submission获得的分数药怎么跟leaderboard的分数比较? 下面是leaderboard的分数,该用什么分数跟什么分数比? 搜过,没有解答
-
人工智能 - 目前的开源视觉大模型有哪些?
目前的开源视觉大模型有哪些? 我知道的只有智谱的 CogVLM,还有其他的吗? https://github.com/THUDM/CogVLM
-
Java正则表达式:性能和替代
问题内容: 最近,我不得不搜索许多字符串值,以查看哪个字符串与某种模式匹配。在用户输入搜索词之前,字符串值的数量和模式本身都不清楚。问题是,我的应用程序每次运行以下行时,我都已注意到: 大约需要40微秒。不用说,当字符串值的数量超过几千个时,它会太慢。 该模式类似于: 这里的A〜F只是示例,但是模式类似于上面的东西。 请注意 模式实际上每次搜索都会改变。例如,“ A * B * C ”可以更改为W
-
注释Lambda表达式的功能接口
问题内容: Java 8引入了Lambda表达式和类型注释。 使用类型注释,可以定义Java注释,如下所示: 然后可以在任何类型引用上使用此注释,例如: 这是一个完整的示例,使用此批注打印“ Hello World”: 输出将是: 在Java 8中,还可以用lambda表达式替换此示例中的匿名类: 但是由于编译器会推断lambda表达式的Consumer类型参数,因此不再能够注释创建的Consum