《极兔速递》专题
-
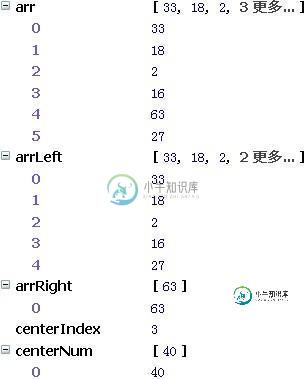 基于javascript实现的快速排序
基于javascript实现的快速排序本文向大家介绍基于javascript实现的快速排序,包括了基于javascript实现的快速排序的使用技巧和注意事项,需要的朋友参考一下 "妙味课堂"的一期视频教学。 主要原理是:快速排序的原理:找基准点、建立二个数组分别存储、递归 基准点:就是找到这个数组中间的一个数; 建立二个数组分别存储:就是以这个基准点,将它的左右数值,分别存放到两个定义的新数组当中; 递归:在函数内部调用自身;
-
Android购物车项目快速开发
本文向大家介绍Android购物车项目快速开发,包括了Android购物车项目快速开发的使用技巧和注意事项,需要的朋友参考一下 购物车项目,业务需要实现了一个购物车的项目,简单的了解下实现逻辑:数据计算等是在Adapter中计算出来的,通过在Adapter中计算出来的数据就可以回调到Activity中进行订单操作等功能业务逻辑,每一个店铺产生的数据是走一条流程的,(业务需求:不是作为一个类似淘宝,
-
快速搞懂Android口令加密(一)
本文向大家介绍快速搞懂Android口令加密(一),包括了快速搞懂Android口令加密(一)的使用技巧和注意事项,需要的朋友参考一下 废话不多说了,直接给大家贴代码了。 使用加密方法: 以上内容是针对Android口令加密的相关介绍,希望对大家有所帮助!
-
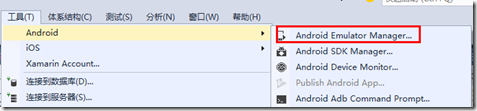 如何快速创建Android模拟器
如何快速创建Android模拟器本文向大家介绍如何快速创建Android模拟器,包括了如何快速创建Android模拟器的使用技巧和注意事项,需要的朋友参考一下 调试手机应用程序一般先用模拟器来实现,只是因为每次都发布到手机上调试太麻烦了。当应用程序在模拟器上调试没错后,再发布到手机运行验证就行了。 一、模拟器创建方式 为了在模拟器中观察运行结果,创建Android应用程序前,需要先创建模拟器。有以下几种办法: 办法1:进入And
-
使用ORDER BY时查询速度慢
问题内容: 这是查询(最大的表约有40,000行) 如果运行此命令,它将很快执行(大约.05秒)。它返回13行。 当我在查询末尾添加一个子句(按任意列排序)时,查询大约需要10秒钟。 我现在正在生产中使用此数据库,并且一切正常。我所有其他查询都很快。 有什么想法吗?我在MySQL的查询浏览器中并从命令行运行了查询。两个地方都死了。 编辑: Tolgahan ALBAYRAK解决方案有效,但是谁能解
-
快速打印可变内存地址
问题内容: 无论如何,是否可以使用新的Swift语言从Objective-C 模拟? 例如: 问题答案: 现在,它已成为标准库的一部分:。 迅捷3 对于Swift 3,请使用:
-
怎么计算21!(21阶乘)迅速?
问题内容: 我正在快速计算阶乘的函数。像这样 该函数可以计算到20。 我认为阶乘(21)的值大于UINT64_MAX。 那么该如何计算21!(21阶乘)迅速? 问题答案: 无符号64位整数的最大值为18,446,744,073,709,551,615。虽然21!=51,090,942,171,709,440,000。对于这种情况,您需要一个Big Integer类型。我在Swift中发现了一个关于
-
如何快速复制数组末尾?
问题内容: 从某些索引开始,肯定有一些使用Swift拷贝数组末尾的非常优雅的方法,但是我只是找不到它,所以我以此结束: 有没有其他功能的更好方法吗? 问题答案: 还有一个… 这给出了对于大多数目的来说应该足够好的。如果您需要一个真实的,请使用 如果起始索引大于(或等于)元素计数,则会创建一个空数组/切片。
-
如何在UILabel上快速下划线?
问题内容: 如何在Swift中下划线?我搜索了Objective-C,但不能完全让它们在Swift中工作。 问题答案: 您可以使用NSAttributedString做到这一点 例: 编辑 为了使一个UILabel的所有文本具有相同的属性,建议您将UILabel子类化并覆盖文本,如下所示: 斯威夫特4.2 斯威夫特3.0 然后将您的文本像这样: 旧: 迅捷(2.0到2.3): Swift 1.2:
-
扩展中的快速覆盖功能
问题内容: 如果我上课: 我最初以为我可以通过添加扩展名来覆盖子类而无需子类化: 该代码不会编译,但错误说明了该函数,这很有意义。 我的问题是: 是否仍要重写特定类的功能?换句话说,在某些情况下,例如上面的示例中,我可以替换功能吗?如果没有,是否有其他解决方法或方法来实现该行为(可能声明了另一个协议,idk) 现在,我考虑得更多了,我不得不说这是不可能的,因为是什么阻止某人重写任何标准库函数? 问
-
makeObjectsPerformSelector的快速等效项是什么?
问题内容: 在Objective-C中,我使用以下代码删除所有子视图: 但是如何迅速使用它呢?我看到苹果文档迅速使用了该方法 但是当我尝试它时,出现错误: 有什么方法可以快速删除子视图? 问题答案: 已针对Swift 2.0(Xcode 7)更新 用途: 或像这样:
-
快速从函数返回多个值
问题内容: 如何快速从函数返回3个相同类型(Int)的单独数据值? 我试图返回一天中的时间,我需要将小时,分钟和秒作为单独的整数返回,但是所有这些都来自同一个函数,这可能吗? 我想我只是不了解返回多个值的语法。这是我正在使用的代码,我在last(return)行上遇到了麻烦。 任何帮助将不胜感激! 问题答案: 返回一个元组: 然后将其调用为: 要么:
-
快速完成自动完成功能
问题内容: 我正在尝试实现自动补全功能,但是找不到在Swift中可用的示例。下面,我打算转换Ray Wenderlich的自动完成教程 和2010年的示例代码。最后,代码进行了编译,但是没有显示包含可能完成的表格,而且我没有经验来了解为什么它未被隐藏shouldChangeCharactersInRange。 问题答案: 用下面的内容替换您的函数内容。希望对您有帮助。
-
无法隐藏状态栏-迅速3,
问题内容: 我通常会隐藏状态栏 但是Xcode给我一个错误,说“方法不会覆盖 其超类中的任何内容”。 如果我删除override,则Xcode会给出另一个错误:“ 带有Objective-C选择器’prefersStatusBarHidden’的方法’prefersStatusBarHidden()’与 具有相同Objective-C选择器的 超类 ‘UIViewController’的gette
-
使用JavaFX2.2助记符(和加速器)
我正在努力使JavaFX助记功能发挥作用。我在现场有一些按钮,我想要实现的是通过按Ctrl+S来激发这个按钮事件。以下是代码Sceleton: