《同程数科》专题
-
7 教程3:将不同类型的数据写入到 XLSX 文件中
在上一节中,我们使用Python和XlsxWriter模块创建了一个设置了简单格式的电子表格。 这次,我们继续扩展要写入的数据,在其中添加一些日期: expenses = ( ['Rent', '2013-01-13', 1000], ['Gas', '2013-01-14', 100], ['Food', '2013-01-16', 300], ['Gym'
-
python3.x - 如何让多进程调用同一个函数运行更快?
同时运行4个进程,这4个进程会调用同一个作用域在全局的函数(4个进程的代码片段有相同部分,有不同部分),这4个进程的运行速度是否会因此受到影响? 我是否需要先深拷贝这个全局函数4份,然后每个进程,传递一个同样函数的深拷贝(伪装成4个函数),这样做,整体的程序,运行会更快吧? 这样可以避免万一发生4个进程同时调用一个函数,起冲突? 下面有这样的伪代码表示我的基本意思: global_fun()在四
-
进程参数
任何进程启动时都可以赋予一个字符串数组作为参数,一般名为ARGV或ARGS。 通过解析这些参数可以让你的程序更加通用,例如cp命令通过给定两个参数就可以复制任意的文件,当然如果需要的参数太多最好还是使用配置文件。 获得进程Argument 进程参数一般可分为两类,一是Argument,也就是作为进程运行的实体参数。例如cp config.yml config.yml.bak的这两个参数。 设计Go
-
改造2,同名不同数据类型的JSON解析
问题内容: 我正在尝试从服务器解析JSON响应,如果在post方法中发送的查询中有更改,我将第一个作为响应,否则,我将第二个作为响应。 1: 2: 如您所见,返回对象是否更改,如果没有更改,则返回字符串。 我正在使用这种方法来获取数据,并且我正在使用Gson Converter来映射数据。 这是请求界面 这是我的POJO课 最后我进行了改造电话: 问题答案: 谢谢您的建议,但我想出了一种可行的方法
-
多个ResultSets,不同的查询,相同的数据库SQLSERVER
使用JDBC驱动程序,我如何使用来自不同查询的多个结果集,而不不断地打开和关闭连接,因为我正在提取所需的w.e并将其传递给另一个方法。每次打开新的conn、语句和结果集时 我试图在一个方法中使用多个结果集,但它一直抛出异常,称结果集已关闭。我没有太多的SqlServver经验,所以任何指导都会有所帮助:-)
-
相同的小数点,不同的舍入结果[副本]
保留两位小数,小数部分相同,结果不一致 输出如上所述,应与小数部分相同。
-
Java-具有相同方法的不同对象的数组
问题内容: 我正在练习继承。 我有两个相似的类,我想将其同化为一个数组,因此我想将Object类用作超类,因为所有内容都是Object的子类。 因此,例如,我将T类和CT类放入一个名为all的数组中,如下所示: 我跳过了声明,因为那不是我的问题。 当我希望使用循环在数组内调用函数时,我真正的问题就变成了: T和CT分别涉及的类都具有beingShot方法,该方法是公共的。 Eclipse建议将它们
-
Parquet分区中同一列中不同类型的数据
我从S3读取PARQUET文件时出错,原因是“final_height”列在同一个分区中有String和Double类型。供参考,拼花文件中有20多列。我得到的错误是: 当"part1.gz.parquet"有X列的字符串数据,而"part2.gz.parquet"在同一列中有双精度数据时,找到了一些解决方案。但是当在同一分区中发现同一列中的不同类型时,它们不起作用。 试: 使用合并模式和推断模式
-
请你说一下多线程和多进程的不同
本文向大家介绍请你说一下多线程和多进程的不同相关面试题,主要包含被问及请你说一下多线程和多进程的不同时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 进程是资源分配的最小单位,而线程时CPU调度的最小单位。多线程之间共享同一个进程的地址空间,线程间通信简单,同步复杂,线程创建、销毁和切换简单,速度快,占用内存少,适用于多核分布式系统,但是线程间会相互影响,一个线程意外终止会导致同一个进程的其
-
Logback |同步/异步日志记录|线程|线程转储
正如logback的文档所说,大多数appender本质上是同步的,但是如果我们将appender包装在异步appender中,那么线程将把数据推送到BlockingQueue中,如果有,比如说X-logback线程将从BlockingQueue获取数据并将其追加。这就是我对它的基本理解。 尝试使用JstackThread转储来测试这个。但是空手返回,没有回退线程的线索。 作为参考,请检查下面lo
-
Pytorch Batch范数层不同于Keras Batch范数
我试图将预训练的BN权重从pytorch模型复制到其等效的Keras模型,但我一直得到不同的输出。 我阅读了Keras和Pytorch BN文档,我认为差异在于它们计算“平均值”和“var”的方式。 Pytorch: 平均值和标准偏差是按小批量的每个尺寸计算的 来源:Pytorch BatchNorm 因此,他们对样本进行平均。 Keras: 轴:整数,应规格化的轴(通常是特征轴)。例如,在具有d
-
 Laravel-根据数组同步数据透视表
Laravel-根据数组同步数据透视表我正在制作一个VueJS表单,用户可以在其中编辑一个步骤。一个步骤可以有许多父产品。逻辑是一个步骤可以属于多个产品。我有一个名为products、product_step(透视表)和steps的表。 当用户第一次加载页面时,该数组将填充此stap的父产品。 此阵列将根据用户决定在前端执行的操作进行更改。假设他们希望产品n不再具有此步骤的访问权限。在这种情况下,产品将从阵列中删除。 我面临的问题是,
-
RegEx同时用于整数和浮点数[closed]
我需要一个regex来匹配这两个整数值和浮点数(而浮点数有一个“.”作为分离器)。这些数字总是在一个括号中,可能有一个前导的“+”。 什么应该是有效的: null 什么应该是无效的: 1.0---因为没有括号 5---因为没有括号 (1,5)---becaue“,”而不是“.” (a)---因为不是一个数字 (1.5)--因为不仅仅是一个数字 (1+5)---因为...嗯...只是失败了 [5]-
-
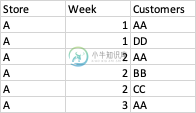 雪花SQL计数与窗口函数不同
雪花SQL计数与窗口函数不同我有一个每周客户和商店信息数据集, 问题-我必须计算的特征,如总独特的客户在最近1,2,3,4,5,6周..等,截至当前的一周。 我在使用count distinct of customers column over window函数时出错- 我尝试了concat函数创建数组,也没有工作-谢谢帮助! 错误-SQL编译错误:distinct不能与窗口框架或订单一起使用。 如何修复此错误? 输入 输出
-
同一数据的多表Cassandra数据建模
表1: 表1的键和数据大小: 我的分区密钥为enterprise_id+campaign_id。每个企业可以有几个活动。datastore可能有几百个活动的数据。每个活动可以有多达200万-300万的记录。因此,在100个企业中可能有3000个分区,每个分区有2-3个miilion记录。 Cassandra查询:查询始终使用分区键+主键直到日期时间。订阅id包含在主键中,以保持每个记录的唯一性,因