
问题:

雪花SQL计数与窗口函数不同
邵璞
我有一个每周客户和商店信息数据集,
问题-我必须计算的特征,如总独特的客户在最近1,2,3,4,5,6周..等,截至当前的一周。
我在使用count distinct of customers column over window函数时出错-
我尝试了concat函数创建数组,也没有工作-谢谢帮助!
SELECT STORE,WEEK,
count(distinct Customers) over (partition by STORE order by WEEK rows between 1 preceding and 1 preceding) as last_1_week_customers,
count(distinct Customers) over (partition by STORE order by WEEK rows between 2 preceding and 2 preceding) as last_2_week_customers
from TEST_TABLE
group by STORE,WEEK
错误-SQL编译错误:distinct不能与窗口框架或订单一起使用。
如何修复此错误?
输入
CREATE TABLE TEST_TABLE (STORE STRING,WEEK STRING,Customers STRING);
INSERT INTO TEST_TABLE VALUES
('A','1','AA'),
('A','1','DD'),
('A','2','AA'),
('A','2','BB'),
('A','2','CC'),
('A','3','AA');
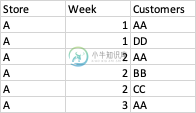
输出

共有1个答案

焦兴为
嗯...我想你根本不需要窗口函数...
首先,我们可以从一个简单的分组开始:
select
store,
week,
count(distinct customers) as cnt
from
test_table
where
week >= [this week's number minus 5]
group by
store, week
这将产生一个简单的表:
类似资料:
-
我在Scala中查看幻灯片函数中的Spark。
-
有没有人知道这样的特性、可能性或变通方法?谢谢!
-
我需要一个窗口函数,该函数按一些键(=列名)进行分区,按另一个列名排序,并返回排名前x的行。 这适用于升序: 但当我试图在第4行中将其更改为或时,我得到了一个语法错误。这里的正确语法是什么?
-
下面是一些示例代码: 这是我希望看到的输出:
-
使用https://stackoverflow.com/a/32407543/5379015中提供的解决方案,我尝试重新创建相同的查询,但使用编程语法代替API,如下所示: 第一个工作正常,但是结果是