《百度春招》专题
-
 7月25日百度提前批客户端一面
7月25日百度提前批客户端一面面试官很和蔼,循循善诱问的。 先问的Java基础,主要是多线程相关的多,还有垃圾回收机制 然后是Android基础,实现跨线程通信的方式,ContentProvider,sqlite相关 还问了一些Kotlin相关 接着是实际场景题,根据我的实习经历问了我一个实际场景,看我如何实现。 根据我回答的知识点,又问了权限相关,互相调用相关这些。 最后是一道算法题,找到一个字符串中出现次数最少,且最左的字
-
 百度计算机视觉算法研发提前批
百度计算机视觉算法研发提前批今天一面,我感觉大抵是凉了 投的时候看见里面有 3D 视觉岗,就投了,结果是智能创作平台捞的我,我一查发现他们是做生成模型的。虽然感觉凉的概率比较大,但是还是认真准备了 面试时,面试官问了什么是 stable diffusion 目标检测网络知道哪些,详细说下 对抗生成网络说下,大模型微调的策略都有哪些(这些我都答上了,不过其中 stable diffusion 的文本特征和图像特征怎么对齐,这个
-
 百度地图 - C++/PHP/GO 研发工程师 - 一面
百度地图 - C++/PHP/GO 研发工程师 - 一面这次又是面的老东家,全程难度一般,没被问什么刁难的问题,面试体验感拉满。但是面试官没开摄像头,不排除 KPI 面的可能。 Intern & baidu: 了解 bRPC 么 还了解百度哪些中间件和框架 实习期间代码量有多少 Intern & bilibili: 为什么不直接通过 RPC 请求发送任务数据、而要通过 Redis List 暂存数据 B 站内部如何配置 Redis Cluster 项目
-
 百度文心一言日常实习凉经 前端
百度文心一言日常实习凉经 前端把整理过的面经发出来攒攒人品,许愿接一个offer(腾讯云智,腾讯金融科技,淘天,快手还在流程中) 面试时间:5.6下午 面完一天就有点模糊了,主要说说没答好的印象深的 1. `map`和`weakmap`的区别 2. 有了解过别的框架吗,Vue和React的区别 3. CSS画三角形需要设置哪些属性 4. `Promise`有什么属性 5. CSS3有什么新特性 6. `e.target`和`e
-
 9.03百度深圳文心一言大模型一面
9.03百度深圳文心一言大模型一面1. 我重构了一下虚拟试衣项目的逻辑讲了25min 2. 问为什么不可以直接concat人穿衣服,答可以做到mask-free 3. 为什么用clip 衣服细粒度可以保持住吗(不太行,可以考虑dino v2) 4. 既然一直提到clip 手写一下 主要写forward 5. 手写RMSNorm(我都不知道是啥了快,写了一下写错了) 6. 还想要我写,时间到了就没再写 7. 介绍做什么: 音频模态,
-
 百度提前批C++地图公共出行面经
百度提前批C++地图公共出行面经7.10投递 7.11简历筛选过 7.13约面 7.17 上午10:30一面,时长70分钟 前45分钟里问的都是实习期间的项目,挖得很深,还问提了几点改进的方法,自己做的项目就问了webserver的细节。MIT6.824之类的一点没问。 问项目的过程中穿插少量八股:get和post的区别,智能指针介绍,hashmap和map的原理和区别,熟悉的STL容器以及项目中如何用到的。 算法题:反转链表,
-
 百度--Java开发提前批+移动应用开发
百度--Java开发提前批+移动应用开发百度移动开发一面 - 为什么选择做安卓 - 安卓了解多少,技术非技术都可以 - 聊项目,登录采用的redis+cookie的分布式session解决方案,具体聊聊 - 登录过程当中对密码的校验,存储讲讲 - 面向对象的三大特性具体讲解下 - 讲讲java的权限空闲控制(protect继承关系,defualt是包访问权限) - java基本类型的以及占空间大小 - boolean类型占多大内存,in
-
 百度暑期实习前端捞面(一二三面)
百度暑期实习前端捞面(一二三面)一面(5.24上午11点) 1、http缓存机制 2、浏览器缓存机制 3、localstorage和sessionstorage的区别 4、cookie的特点 5、了解事件委托吗 6、为什么会出现跨域问题 7、如何解决跨域问题 8、伪类和伪元素的区别 9、position有哪些属性 10、position的定位方式,相对于谁定位 11、说说你对BFC的理解 12、BFC能解决什么问题 13、单行文
-
 百度数据库云平台研发面经(23 秋招提前批)
百度数据库云平台研发面经(23 秋招提前批)三面挂,具体为啥挂的我也不是很清楚,猜测没hc被排序了 三面(08.09) 实习项目 对云的理解 实习公司的基建的理解 容器与虚拟机的区别 常见的网络攻击 自己的优缺点 有没有其他offer 一共问了30min,面完就挂了,可能hc没几个,排序挂了 二面(07.29) 问了40多min业务问题......(太顶了......) 算法:字典序排序 反问:后续流程还有三面经理面+HR 一面(07.25
-
 2023秋招offer阿里、百度、美团、快手、滴滴、华为面经
2023秋招offer阿里、百度、美团、快手、滴滴、华为面经我面的全都是机器学习/AI/计算机视觉算法岗,拿到了自己满意的offer,菜菜的小孙同学来牛客还愿啦,希望能帮助他其他小伙伴吖,祝愿大家都能拿到心仪的offer哇! 本人本硕985,研究大方向深度学习,小方向应用于计算机视觉的连续学习/增量学习/终身学习,同时涉猎了一点元学习、多任务学习、可解释性机器学习这部分的内容。研究生期间一共完成了三篇工作,一篇nips一作(oral),一篇aaai学生二作
-
春季:休眠+ ehcache
问题内容: 我正在使用hibernate处理spring项目,并希望使用ehcache实现二级缓存。我看到了许多解决方法: 引入注释 一个旨在成为继任者的工具集。 可以很好地集成到休眠本身中,以使用例如注释进行缓存。 使用代理。基于注释的配置迅速变得有限或复杂(例如,注释嵌套的多个级别) 就我个人而言,我认为还不够彻底,因此我可能更愿意考虑发展得更为积极。尽管这似乎是最完整的实现(例如,读取和写入
-
Jackson春靴球衣
如spring boot博客所述 我尝试自定义我的对象序列化。 在我的配置中添加了一个新的配置bean之后 当我尝试输出类用户的实例时,json结果不在CAMEL_CASE_TO_LOWER_CASE_WITH_UNDERSCORES中 也许我需要在我的Jersey配置中注册一些东西来激活我的自定义obejctMapper配置 谢谢
-
春云侦探+log4j2
我的一些微服务使用log4j2作为记录器。Spring cloud Sleuth支持logback。在这个场景中,我如何使用Sleuth来获得分布式跟踪。我明白用log4j2使用sleuth,我必须实现某些类。我试过了,但没有运气。请帮忙
-
春靴骆驼Kafka
我有一个Spring Boot2.25.1应用程序,它使用Camel 2.25.1与camel-kafka,一切都正常工作…在我的Kafka消费者中,我需要添加该功能以按需暂停消费,因此我升级到camel 3.18.1,以便我可以使用可暂停功能。升级到3.18.1后,我收到错误FileNotes与类文件TimeoutAwareAggregationStategy.class. 当我打开camel-
-
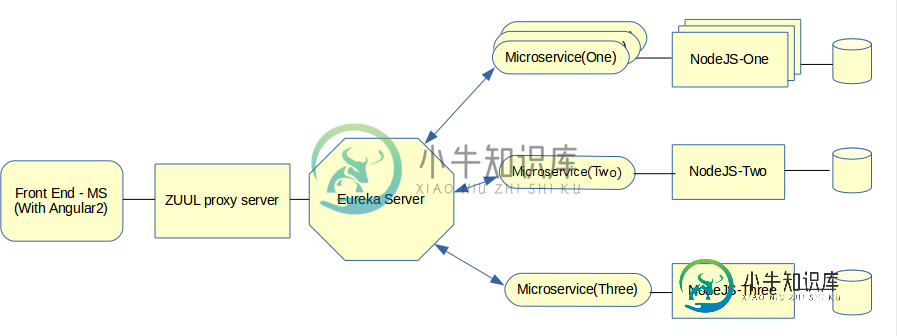 春云:ZUUL Eureka NodeJS
春云:ZUUL Eureka NodeJS我是SpringBoot(云)的新手,将从事一个新项目 我们的项目架构师设计了这样的新应用程序: 一个带有Angulle-2的前端Spring Boot应用程序(也是微服务)。 一个尤里卡服务器,其他微服务将连接到该服务器。 ZUUL代理服务器,它将连接到前端和镜像服务。 我需要单独的ZUUL代理服务器吗?我的意思是,使用与ZUUL服务器相同的前端应用程序的利弊是什么 MicorService-1