
春云:ZUUL Eureka NodeJS

我是SpringBoot(云)的新手,将从事一个新项目
我们的项目架构师设计了这样的新应用程序:
- 一个带有Angulle-2的前端Spring Boot应用程序(也是微服务)。
- 一个尤里卡服务器,其他微服务将连接到该服务器。
- ZUUL代理服务器,它将连接到前端和镜像服务。
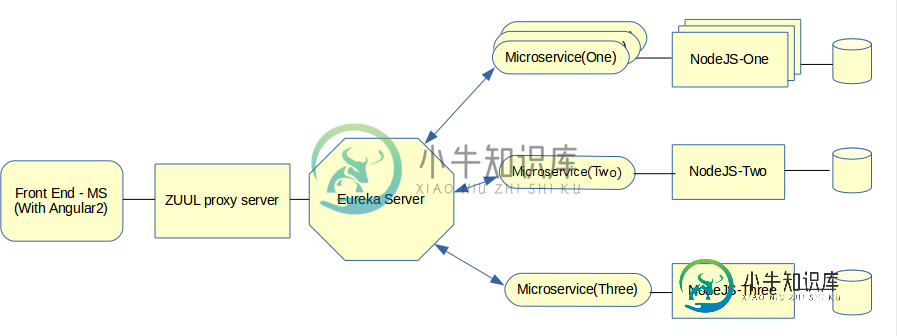
- 我需要单独的ZUUL代理服务器吗?我的意思是,使用与ZUUL服务器相同的前端应用程序的利弊是什么
- MicorService-1将如何与节点的MicroService-1通信?一些博客建议使用侧车。但是,为什么呢?因为我可以直接从Microservice-1调用NodeJS-1的restapi
- (我知道,这很难猜测,但仍然在问)NodeJS服务(不是遗留服务)应该调用一些第三方api或从DB检索数据<现在,我不明白的是为什么我们需要NodeJS代码?为什么我们不能在用Java编写的微服务中做同样的事情
有谁在类似的场景中工作过,能解释一下我的疑问吗?
共有1个答案

我不了解您试图解决的问题的全部背景,因此下面的答案非常笼统,但仍然可能有用:
我需要单独的ZUUL代理服务器吗?我的意思是,使用与ZUUL服务器相同的前端应用程序的利弊是什么?
是的,您需要一个单独的API网关服务,它可以是Zuul(或其他网关,例如tyk.io)。
这里的主要思想是,你可以拥有数百甚至数千个微服务(如亚马逊、Netflix等),它们可以分散在不同的机器或数据中心。强制API使用者(在您的例子中是Angular 2)记住每个微服务的所有可能位置是非常愚蠢的。最好有一个了解其下所有服务的API网关,这样您的客户端就可以调用您的网关并通过一个地方访问底层服务。同时,在您的系统中安装一个将使您的客户机与您的服务分离,因此可以独立地对它们进行改进。
另一个好处是,您可以在一个地方拥有访问控制、日志记录、安全性等。顺便说一句,我认为您的体系结构中还缺少一件东西——授权服务器。构建微服务安全性的常用方法是OAuth2.0。
MicorService-1将如何与节点的MicroService-1通信?一些博客建议使用侧车。但是,为什么呢?因为我可以直接从Microservice-1调用NodeJS-1的restapi。
我想你可以用边车,但我从来没有用过。我认为为什么这个问题与Discovery Service(架构中的Eureka)有关。您不能直接调用微服务NodeJS-1,因为NodeJS-1可能有几个实例,要调用哪个?此外,您无法知道服务在任何给定时间点是关闭还是活动。这就是为什么我们使用尤里卡这样的发现服务——他们处理所有这些。当任何给定的服务启动时,它必须在Eureka中注册。因此,如果您已经启动了几个NodeJS-1实例,它们都将在Eureka中注册,并且每当Microservice-1想要调用NodeJS-1服务时,它都会向Eureka询问NodeJS-1活动实例的位置。然后服务选择调用哪一个。
(我知道,这很难猜测,但仍然在问)NodeJS服务(不是遗留服务)应该调用一些第三方api或从数据库检索数据。现在,我不明白的是为什么我们需要NodeJS代码?为什么我们不能在Java写的微服务中也这样做呢?
我只能假设之所以选择NodeJS,是因为它在IO操作方面具有出色的性能,包括在调用第三方服务时可能出现的HTTP请求。对此,我没有任何其他合理的解释。
总的来说,微服务可以让您用不同的语言编写微服务,这确实很酷,因为每种语言都比另一种语言更好地解决一些问题。另一方面,做出这个决定时应该谨慎,并回答以下问题:“我们真的需要在堆栈中使用一种新的语言来解决问题X吗?”。
-
Spring Cloud Kafka Streams与Spring Cloud Stream、Spring Cloud Function、Spring AMQP和Spring for Apache Kafka有什么区别?
-
我正在使用spring-cloud Brixton.m5进行一些工作,并尝试使AsyncRestTemplate工作,以便将多个微服务调用异步组合到协调服务响应中。我在https://github.com/spencergibb/MyFeed/blob/master/myfeed-core/src/main/java/MyFeed/core中找到了spencer Gibb的MyFeed githu
-
我的一些微服务使用log4j2作为记录器。Spring cloud Sleuth支持logback。在这个场景中,我如何使用Sleuth来获得分布式跟踪。我明白用log4j2使用sleuth,我必须实现某些类。我试过了,但没有运气。请帮忙
-
我用的是Apache Kafka 2.7.0和Spring Cloud Stream Kafka Streams。 在我的Spring Cloud Stream (Kafka Streams)应用程序中,我已经将我的application.yml配置为当输入主题中的消息出现反序列化错误时使用sendToDlq机制: 我启动了我的应用程序,但我看不到这个主题存在。文档指出,如果 DLQ 主题不存在,
-
如何提供一个在条件不匹配时调用的处理程序? 如果我有两个处理程序,第一个有条件,第二个没有条件,当第一个条件匹配时,两个处理程序都被调用。我如何避免这种情况?
-
我有一个关于基于Spring Cloud Netflix(Zuul、Eureka)、Spring Security OAuth和Spring Cloud Security的微服务生态系统之间安全下游调用的问题。 例如,我有WEB应用程序(WEB)和以下微服务:A、B、X、Y、Z。 null null 而我想解决以下问题(困惑的副手问题): 服务A应该不能对服务Z执行任何操作(即使经过身份验证的用户