《tplink深圳软开》专题
-
 虹软科技 C++ 一面
虹软科技 C++ 一面虹软科技 C++ 一面 30分钟。感觉大概率要寄了 1.自我介绍 2.介绍项目 3.线程池请求队列是用什么实现的?(链表) 4.线程池中的线程是怎么运作的?(应该是想让我回答互斥锁+条件变量) 5.注册登陆的用户名和密码存在哪里?(数据库) 6.客户端资源下载到一半突然网络中断怎么办,有进行处理吗? 7.有进行过压力测试吗? 8.讲讲内存管理,不管理会怎么样(回答的很乱,加上紧张、很多方面没说清楚
-
 新华三软测面试
新华三软测面试一面 计算机网络 1.同一个局域网内两个计算机怎么通信?/ARP协议 IP MAC地址转换 2.在网页上搜索得到页面如何通信/HTTP协议 3.TCP/IP类 Linux SQL 测试的一些基本框架 反问 培训制度:6个月试用期 正常工资 导师一对一进行技术/思想学习集中培训一周对公司的业务规章 产品模块进行熟悉 工作内容:主要偏向于黑盒测试,包括自动化测试和手工测试 1.硬件测试:单片机类;软件
-
查找二叉搜索树的深度时超过最大递归深度
这是我的代码: 首先,我从一个列表中做一个二叉查找树,并检查它是否是一个二叉查找树。 给定列表的第一个元素是根节点,后续元素成为子节点。到叶节点。 例如,调用 的结果为: 结果是二叉搜索树,因为左子节点小于父节点,右子节点大于父节点。因此,调用<code>bst_child</code>的结果是<code>True</code>。 然后我添加了寻找二叉查找树深度的代码。通过对第一个列表排序,我制作
-
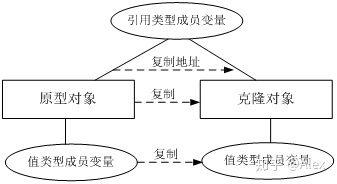 C# 中浅克隆与深克隆(浅拷贝与深拷贝)的区别?
C# 中浅克隆与深克隆(浅拷贝与深拷贝)的区别?本文向大家介绍C# 中浅克隆与深克隆(浅拷贝与深拷贝)的区别?相关面试题,主要包含被问及C# 中浅克隆与深克隆(浅拷贝与深拷贝)的区别?时的应答技巧和注意事项,需要的朋友参考一下 (1)浅克隆 在浅克隆中,如果原型对象的成员变量是值类型,将复制一份给克隆对象;如果原型对象的成员变量是引用类型,则将引用对象的地址复制一份给克隆对象,也就是说原型对象和克隆对象的成员变量指向相同的内存地址。简单来说,在
-
如何从帧深度缓冲区访问其他帧深度缓冲区?
我在游戏中使用延迟渲染器。因此,第一个渲染过程是使用多个渲染rarget创建反照率和法线缓冲区,并填充深度缓冲区。所有这些缓冲区实际上都是纹理。 现在我想从其他渲染通道访问深度缓冲区,从而访问其他帧缓冲区,而不改变深度纹理。我只想读取深度值。对于这些通道,我主要绘制全屏四边形,我不希望他们更新深度纹理并将其消隐为深度值0。 如何将一个给定的深度纹理附加到另一个帧缓冲区,并确保它是只写的?
-
 9.22 深信服python开发工程师一面
9.22 深信服python开发工程师一面Python: 为什么使用 if a is None 而不是a == None 列表底层实现以及append过程 字典底层实现以及哈希冲突解决方式 代码: 列表根据元素内部顺序排序方法 两个栈实现队列 八股: 怎样是一个好的程序 Linux 调试方法 正则表达式检测16进制 HTTP和https 如何防止遭受黑客攻击或者注入代码 反问 算法题两个ez 八股问了特别多东西,我是一点都不会,要
-
 深信服 测试开发 一面 铁凉凉
深信服 测试开发 一面 铁凉凉太拉太不自信了,不应该露怯的,应该自信的说“会”“了解” 。 0.自我介绍。说下实习内容。 1.最大连续子数组和。 2.说下算法复杂度。 3.不用Math.max实现。 看你有两个项目,还记得吗?不太记得了。。。 这个你会吗?会一点。。。 这个你了解吗?了解一点。 。。。 4.Hadoop的架构说一下。 5.Kafka的生产者和消费者说一下。 6.OSI模型说一下。 7.每层都有哪些协议。 #深信
-
 9.1 深信服go开发工程师笔试
9.1 深信服go开发工程师笔试选择题9+多选题1+填空题3+编程题3 我自己是javaer,只看过一点点go语法,然而选择填空全是go的,不太会。 编程题(纯纯送分...估计又是业务筛选卡人了) 第一题 核酸防控封锁出入口 思路:遍历每一个格子,如果当前格子为1,则统计四周为0的数量。对这个数量求和就是答案。 第二题 核酸方案数 思路:斐波拉契数列... 第三题 局部反转链表 lc原题 #深信服##秋招##校招##笔试##笔经
-
 深信服测开线下面试一面凉
深信服测开线下面试一面凉学的后端Java技术栈,投的测开 10分钟问了下实习、项目 10分钟写了个easy讲思路 10分钟问了两个开放题, 1、用户使用app时出现了异常,不能看代码怎么解决?说了两种方式,面试官说我是从开发的角度讲的,让我从测试角度讲。不懂怎么从测试角度讲,测试工具什么的也没学过不知道是不是考这个 2、囚徒困境怎么解决?随便讲了两种,面试官只有一句话,还有吗。 反问几分钟 全程35分钟,下楼hr通知面试
-
 深信服 测开 一面 二面 hr面经
深信服 测开 一面 二面 hr面经10.19 一面 10.20 二面 10.23 HR面 1、自我介绍 2、为什么没有实习 3、为什么从数学转到计算机 4、你比较有成就的一件事 5、你为什么选择测开 6、反问:培养方式 7、谈薪 8、反问:什么时候会有面试结果 10.26已出结果
-
 面经深度解析:百度测试开发
面经深度解析:百度测试开发👥面试题目 java多线程的线程状态,多线程用什么库比较多 考察的知识点: Java多线程基础:理解Java线程生命周期的状态及其转换。 多线程编程技术:熟悉Java中用于实现多线程编程的技术栈。 并发工具类:掌握java.util.concurrent包中提供的高级并发工具类。 线程安全性和效率:了解如何在保证线程安全性的同时提高程序效率。 需要从哪些方面来作答: 线程状态:解释Java线程的
-
 深信服Python测开实习一面凉经
深信服Python测开实习一面凉经32min 1、自我介绍 2、你在公司负责什么 3、能单独说一下你独自负责业务板块的流程吗 4、几道python算法,说出输出结果 5、osi模型、tcp/ip、网络协议、 6、学校那边有跟python相关的课程吗 7、元组和集合的区别 8、电梯井,怎么控制,试着从安全因素方面去考虑 9、详细讲讲icmp传输过程 10、linus常用命令--显示硬盘容量 11、还有什么想问的吗 第8题请大佬们评论
-
软件包包含对象和具有相同名称的软件包
问题内容: 我在用Maven或Eclipse编译一些Scala时遇到问题,我尝试从Java jar导入一个包含名称空间和同名类的类。 我可以用编译。 例如,Java项目(jar)包含: 编译器抱怨: 在Scala 2.9.0.1(和)中使用Maven 3.0.03 / Eclipse 3.7.1 。 我遇到问题的jar是-它肯定包含几个实例,其中存在同名的名称空间和对象。 我正在尝试在Scala中
-
Anaconda:永久包含外部软件包(例如PYTHONPATH中的软件包)
问题内容: 我知道如何使用Anaconda安装软件包,以及如何安装PyPi上的软件包,如手册中所述。 但是,如何才能将软件包/文件夹永久包含在Anaconda环境中,以便可以导入当前正在使用的代码,并且在重新启动后仍然可用? 我当前的方法是使用: 这不是很方便。 有什么提示吗? 提前致谢! 问题答案: 我在Anaconda论坛中找到了两个问题的答案: 1.)将模块放入站点包中,即始终位于的目录中。
-
导入numpy和Scipy软件包的模块/子软件包的差异
问题内容: 我正在通过Anaconda 2.1.0发行版使用scipy和numpy。我使用Spyder作为我的Python IDE。 当我运行时 ,我无法通过以下方式访问子包,例如optimize,linalg,cluster等。 但是,运行时,我可以通过访问所有子包,例如linalg,random,matrixlib,多项式,测试等。 两种进口的工作方式不同,是否有原因?为什么不将所有scipy