《拼多多面经》专题
-
是否从多对多关系表中删除记录?
我正在使用hibernate多对多的关联。我有3个表(STUDENT,COURSE和STUDENT_COURSE)。在3个表中,2个是主表,1个是提供关系的中间表。当记录从STUDENT中删除时,相应的映射将从Student_Course中删除。我的要求是它甚至应该从课程表中删除记录。考虑以下STUDENT_COURSE条目: 当从学生表中删除101时,上述表中的第一个条目被删除,但课程表中对应于
-
对多对多关系应用级联类型删除
我目前正在开发一个网络票证系统,并有课程来存储我的票证数据。每个票据都可以有多个相关标签,为了管理这些标签,我创建了一个标签编辑器。这很好,只缺少一个删除选项。到目前为止,大多数删除都失败了,原因是该标签仍然被另一个票证引用,这需要先删除它。在寻找解决方案的过程中,我遇到了CascadeType。删除,这似乎正是我想要的。 但是,由于ticket对象包含一组标签,而不是相反,因此每次我删除一张ti
-
与特定级联类型的JPA多对多关系
对于我的任务,我需要使用JPA创建多对多的关系,但是连接表是手动指定的,并带有额外的列。数据结构如下所示: 图书(id、名称、已出版、流派、评级) 作者(身份证、姓名、性别、出生) 图书-作者(id,book-id,author-id) 我创建了这样的实体: 作者: 书: AuthorBook表: 例如,当我删除ID=2的book,它将删除ID=1的author。有没有什么方法可以在不删除已绑定作
-
Spring数据JPA从多对多关系删除问题
在我的项目中,我使用Spring数据jpa。我有多对多关系的表格。我的实体: 和零件: 现在在Controller中,我尝试从表部分中删除一行: 但我有例外: 区分完整性约束冲突:“FK9Y4MKICYBLJWPENACP4298I49:PUBLIC.PARTS外键(ID\u导出)引用PUBLIC.EXPORT(ID)(1)”;SQL语句:/*删除com.aleksandr0412.demo.en
-
当多索引、多类型搜索时,ElasticSearch返回404
我们有一个需要跨多个索引查询的要求,如下所示 我们使用的是ElasticSearch 5.1.1. http://localhost:9200/index1,index2,index3/type1,type2/_search 查询: 但是,我们可能无法预先知道该索引是否存在,如果上述任何一个索引都不存在,我们将得到以下错误。 一个明显的方法是检查索引是否已经存在,但我希望避免额外的调用。 注意:至
-
基于多集条件的jooq多集序结果集
收集了mit Jooq的multiset的第一次经验,我试图弄清楚如何根据multiset的一些标准来排序结果集。考虑一个带有Product表的datastructure,每个产品可以分配任意数量的存储。 使用以下查询获取产品时: 如何根据多集的条件对结果进行排序。 例如,把那些已经分配存储的放在第一位。 给出所需的结果,但对我来说,不清楚实际的排序比较在做什么。 谢谢你的帮助! 问候你,安德烈亚
-
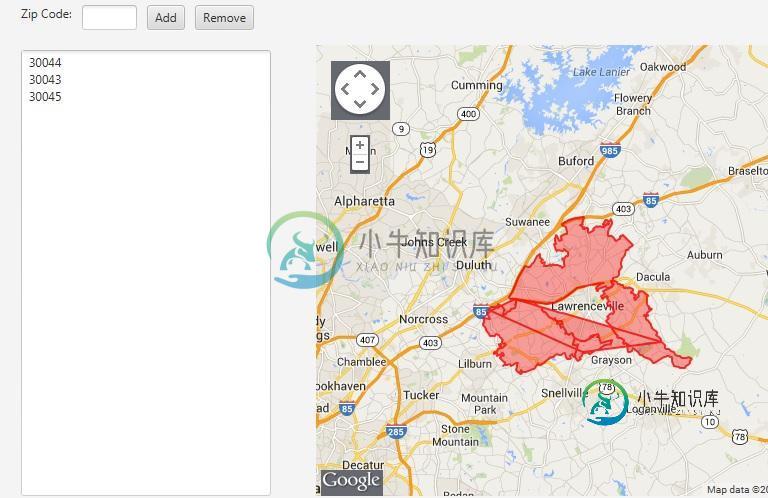 GoogleMaps API V3构建包含多个Zipcode的多边形
GoogleMaps API V3构建包含多个Zipcode的多边形我必须允许用户输入多个邮政编码,从数据库中检索纬度和经度,然后构建一个包含它们的巨大多边形。 我需要在代码中修改什么才能将所有这些较小的多边形变成一个较大的多边形?我在谷歌上搜索过答案,我所能找到的只是逐个构建每个邮政编码的多边形,但这仍然不能给我一个更大、单个多边形的最终结果。 目前,输入邮政编码后,程序从数据库中收集lat和long点,并将它们输入一个巨大的数组(确切地说是字符串[][]),然
-
如何插值多个高速多边形碰撞(2D)?
上下文 我需要在物理模拟中检测高速物体的碰撞。由于网格中数字的截断和对象的数字表示,快速移动的对象很有可能相互穿过或错过。我试图通过模拟“模拟”或现实生活中的运动属性来执行插值碰撞,在这些运动中,物体会通过每一点移动。(现实世界中的物体通常不会在宏观层面上传送到下一个点) 研究和预见我们能够找到投影物体的最终和初始点,时间和速度的位移。我使用每像素碰撞来获得像素映射,所以我们有一个像素簇。目前我解
-
多线程:多个线程与同一个表交互
面试问题 比如说,我们有一个在Employee表中有200万条记录的表,我们需要削减每个员工10%的工资(需要做一些处理),然后将其保存回collection。你怎样才能有效地做到这一点。 我问他,我们可以使用executor框架来创建多个线程,这些线程可以从表中获取值,然后我们可以处理并将其保存到列表中。 然后他问我,你将如何检查一个记录是否已经被处理,我不知道(如何做)。 甚至我也不确定我是否
-
Hibernate:从多个表中获取多个表列结果
我正在使用hibernate 4和Spring 3。 我有5个表,每个表映射一个实体类。现在,如果我必须从1个表中选择列,我将执行以下操作: 此结果中的此值将为EmployeeEntity类型。 或者我也可以使用标准。 现在我的要求是我必须从所有5个表中得到结果。每个表中有1-2列。 早些时候,它是一个1表,所以我得到了一个实体,现在我得到了5个表的结果,所以如何在实体中映射它。 List res
-
如何在Spring Boot库中查询多对多关系
我试图让api返回一个注释列表,通过与标签的多对多关系关联,给定一个标签ID。Spring boot自动创建了一个名为notes_tables的桥接表,其中包含一个notes_id字段和一个labels_id字段。Spring Boot还创建了一个notes表和一个labels表。我尝试了以下步骤: 我只需要让它工作,但我特别好奇我是否能让它与jpa方法查询一起工作。任何查询都可以,只要它可以工作
-
将多个图像路径插入到多个列中
在一个Intranet站点上,我正在将相当多的图像从文件系统移动到MySQL中,并编写了一个小函数来提供帮助。没有错误,但插入的图像也没有错误,因此我需要帮助找出如何在不加载_FILE()的情况下执行此操作,因为它需要更改文件夹和文件权限,而我无法这样做。 请注意,有必要查询相册表,以便将相册表中的主键与图像一起插入,以便显示相册的程序知道要加载哪个图像。 它被称为: 图片表中没有太多内容,但这里
-
基于多列将一行拆分为多行[重复]
我在 spark 中有一个数据帧: 此处,所有列均为字符串数据类型。 如何在多列中使用分解功能,并创建如下所示的新数据框: 在新的数据帧中,所有列都是字符串数据类型。
-
python3 - 多进程大于CPU数量下的多进程?
由于全局解释器锁的存在,python3的多线程是伪并行的。 现在看进程。如果一个CPU仅仅有4个核,我在设置pool的时候,设置Pool(5),此时,有5个并行的进程在同时运行,这个说法不对吧,任何时刻,由于CPU的束缚,仅仅只可以有4个进程并行。 我的理解对吧?
-
使用javascript使用经度和纬度计算多边形面积
https://stackoverflow.com/a/4682656/7924630这是一个非常有用的答案,帮助我解决这个问题 出于某种原因,这返回的区域值很小,我不明白为什么。例如,我在一个矩形区域上测试了这个。面积应该约为45平方米,但它返回0.0137平方米。我尝试了其他的实现,但没有找到任何对本机JavaScript有用的东西。