《排序》专题
-
JavaScript冒泡排序
定义 冒泡排序(英语:Bubble Sort)又称为泡式排序,是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。 冒泡排序之所以叫冒泡排序,是因为使用这种算法进行排序时,数据值会像气泡一样从数组的一端漂浮
-
23 ORDER BY 排序
前面小节介绍了如何查询数据,并且介绍了如何使用 WHERE 条件对查询的数据结果集进行筛选,本小节介绍如何使用 ORDER BY 对查询结果集进行排序,排序在实际业务中非常有必要,可以较好地对结果集数据分析和处理。 1.ASC 从小到大排序 ASC是对结果集按照字段从小到大排序(升序),以 teacher 表为例,将查询出来的所有结果集按照年龄 age 从小到大排序: SELECT * FROM
-
4.6 排序数组
排序(sort)数组(即将数据排成特定顺序,如升序或降序)是一个重要的计算应用。银行按账号排序所有支票,使每个月末可以准备各个银行报表。电话公司按姓氏排序账号清单并在同一姓氏中按名字排序,以便于找到电话号码。几乎每个公司都要排序一些数据,有时要排序大量数据。 排序数据是个复杂问题,是计算机科学中大量研究的课题。本章介绍最简单的排序机制,在本章练习和第15章中,我们要介绍更复杂的机制以达到更高的性能
-
8.5 map 的排序
map 默认是无序的,不管是按照 key 还是按照 value 默认都不排序(详见第 8.3 节)。 如果你想为 map 排序,需要将 key(或者 value)拷贝到一个切片,再对切片排序(使用 sort 包,详见第 7.6.6 节),然后可以使用切片的 for-range 方法打印出所有的 key 和 value。 下面有一个示例: 示例 8.6 sort_map.go: // the tel
-
1.4 程序排错
1.4 程序排错 先说一个坏消息:一旦开始写程序,就免不了要出错。程序设计虽然并不难,但无论是 初学编程者还是经验丰富的专业程序员,程序中出现各种错误都是很常见的。 再说一个好消息:计算机(严格说是编译器或解释器)能够帮助我们发现程序中的很多 错误。 在计算机行话中,程序中的错误被称为“臭虫”(bug),而发现并改正错误的过程称为排 错(debug,或称调试)。 程序中的错误大体可分为三种类型:语
-
4. 归并排序
4. 归并排序 插入排序算法采取增量式(Incremental)的策略解决问题,每次添一个元素到已排序的子序列中,逐渐将整个数组排序完毕,它的时间复杂度是O(n2)。下面介绍另一种典型的排序算法--归并排序,它采取分而治之(Divide-and-Conquer)的策略,时间复杂度是Θ(nlgn)。归并排序的步骤如下: Divide: 把长度为n的输入序列分成两个长度为n/2的子序列。 Conque
-
2. 插入排序
2. 插入排序 插入排序算法类似于玩扑克时抓牌的过程,玩家每拿到一张牌都要插入到手中已有的牌里,使之从小到大排好序。例如(该图出自[算法导论]): 图 11.1. 扑克牌的插入排序 也许你没有意识到,但其实你的思考过程是这样的:现在抓到一张7,把它和手里的牌从右到左依次比较,7比10小,应该再往左插,7比5大,好,就插这里。为什么比较了10和5就可以确定7的位置?为什么不用再比较左边的4和2呢?因
-
13.10 归并排序
在第13.7节,我们见到一个简单的排序算法,结果它不够高效。要排序n个项目,该算法必须遍历向量n次,而且每次遍历花的时间也是与n成比例的。因此,总时间与n2(这里表示n平方,下同)成比例。 本节我们会简单介绍一个更高效的算法——归并排序。要对n个项目进行排序,归并排序消耗的时间与nlogn成比例。这个数字看起来可能不会给人留下深刻印象,但是随着n增大之后,n2和nlogn的差距是巨大的。你可以自己
-
4.5.排序模式
可使用如下模式对搜索结果排序: SPH_SORT_RELEVANCE 模式, 按相关度降序排列(最好的匹配排在最前面) SPH_SORT_ATTR_DESC 模式, 按属性降序排列 (属性值越大的越是排在前面) SPH_SORT_ATTR_ASC 模式, 按属性升序排列(属性值越小的越是排在前面) SPH_SORT_TIME_SEGMENTS 模式, 先按时间段(最近一小时/天/周/月)降序,再按
-
9. 排错指南 - Windows 排错
本章介绍 Windows 容器异常的排错方法。 Windows Pod 一直处于 ContainerCreating 状态 一般有两种可能的原因 Pause 镜像配置错误 容器镜像版本与 Windows 系统不兼容。注意在 Windows Server 1709 上面需要使用 1709 标签的镜像,比如 microsoft/aspnet:4.7.1-windowsservercore-1709 m
-
9. 排错指南 - PV 排错
本章介绍持久化存储异常(PV、PVC、StorageClass等)的排错方法。 一般来说,无论 PV 处于什么异常状态,都可以执行 kubectl describe pv/pvc <pod-name> 命令来查看当前 PV 的事件。这些事件通常都会有助于排查 PV 或 PVC 发生的问题。 kubectl get pv kubectl get pvc kubectl get sc kubectl
-
9. 排错指南 - Pod 排错
本章介绍 Pod 运行异常的排错方法。 一般来说,无论 Pod 处于什么异常状态,都可以执行以下命令来查看 Pod 的状态 kubectl get pod <pod-name> -o yaml 查看 Pod 的配置是否正确 kubectl describe pod <pod-name> 查看 Pod 的事件 kubectl logs <pod-name> [-c <container-name>]
-
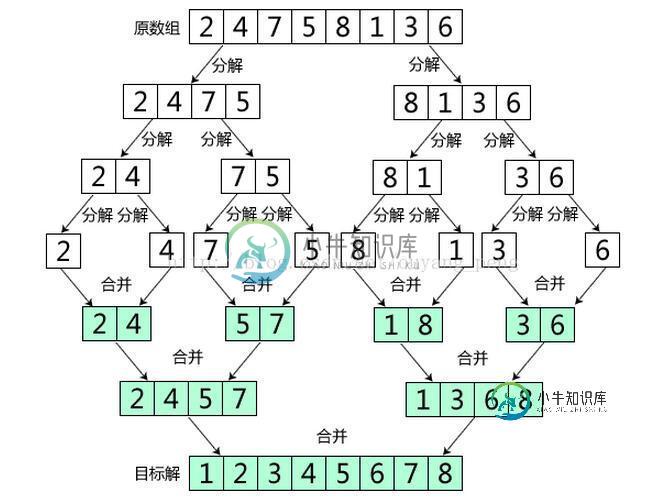 Java经典排序算法之归并排序详解
Java经典排序算法之归并排序详解本文向大家介绍Java经典排序算法之归并排序详解,包括了Java经典排序算法之归并排序详解的使用技巧和注意事项,需要的朋友参考一下 一、归并排序 归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归
-
 Java排序算法之归并排序简单实现
Java排序算法之归并排序简单实现本文向大家介绍Java排序算法之归并排序简单实现,包括了Java排序算法之归并排序简单实现的使用技巧和注意事项,需要的朋友参考一下 算法描述:对于给定的一组记录,首先将每两个相邻的长度为1的子序列进行归并,得到 n/2(向上取整)个长度为2或1的有序子序列,再将其两两归并,反复执行此过程,直到得到一个有序序列。 运行结果看一下: 总结 以上就是本文关于Java排序算法之归并排序简单实现的全部内容,
-
PHP排序算法系列之归并排序详解
本文向大家介绍PHP排序算法系列之归并排序详解,包括了PHP排序算法系列之归并排序详解的使用技巧和注意事项,需要的朋友参考一下 归并排序 归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有