《分奖金》专题
-
JAVA递归二分法
我正在处理一个递归二分法/算法。我已经把我的递归放在else/else if语句中,不知道我是否错了。它也返回正确的根,而没有递归,但主要问题是用递归。
-
Bulma CSS&child角分量
我决定将我的普通html部分转换成一个组件,并且一切都正常工作,但是子组件不能具有引用,即它在列的引用中。 这里是我的代码,在这里一切都运行良好: 但我决定在组件中转换一些html 如: 我对app-fruits做了none封装,但没有工作,我的2列没有像以前那样对齐。有人帮忙吗?
-
Cassandra:低基数分区
假设我有一张桌子,像这样: 这遵循了所需的Cassandra模式,跨分区分布良好(假设默认的Murmur3哈希分区器)。 但是,我也需要(很少)按时间顺序执行范围查询。这在Cassandra中似乎是不可能的。实际上,我确实需要按组访问数据,所以是可以接受的。由于似乎没有办法让辅助索引有多个列,我想正确的做法是将其反规范化,如下所示: 除了< code>group基数很低,比方说< code>('A
-
RCP e4隐藏部分
我实现了一个e4 RCP应用程序,我想为特殊用户隐藏部分。 在e3中,我知道我可以通过一个实现iPerspectiveFactory的透视类来做到这一点。 我现在的解决办法是: 我在part类中这样做,当我运行应用程序时,我会得到以下injectionexcetion: !Entry org.eclipse.e4.ui.workbench 4 0 201 7-08-01 09:08:06.139!
-
Kafka主题与分区
简单问题: 假设我有一个具有3个分区的主题:Topic:StateEvents P1、P2和P3。 让我们假设生产者生成20条消息: 1, 2, 3, ..........20 我的问题是: 当制作人生成这些消息时: 1)每个消息将只在且仅在1个分区?也就是说,1在P1,2在P2,3在P3,然后4在P1,5在P2,6在P3,以此类推? 2)如果#1为真,当消费者订阅时,它将订阅所有分区,以便获得所
-
角智能表分页
我目前正在使用:“angular smart table”:“2.1.0”“angular”:“1.3.15” 单击智能表格项目时,我的应用程序会在另一个页面中显示项目详细信息。在访问项目页面后,我想回到智能表格页面上的相同页码(屏幕截图上的2):屏幕截图 我的问题: 不知道如何保存currentPage(rootscope、Parameter?) 以下是分页视图,用于管理分页: “智能表插件指令
-
部分解码h264流
我正在尝试获取关于h264位流中帧的信息。特别是宏块的运动矢量。我想,我不得不为它使用ffmpeg代码,但它真的很庞大,很难理解。那么,有没有人可以给我一些从h264流的单帧原始数据中进行部分解码的技巧或Exapms? 谢谢你。
-
货币汇率分配
你好,我在找人帮我做作业!因此,提示如下: “编写一个程序,提示用户输入美元与人民币之间的汇率。提示用户输入0将美元转换为人民币,输入1将人民币转换为美元。提示用户分别输入美元或人民币金额将其转换为人民币或美元。”y、 当用户输入“1”(从元到美元)时,程序应该使用indexOf()和substring()方法提取小数点前的美元金额,以及小数点后的美分。以下是运行示例,用户的输入带有下划线: 输入
-
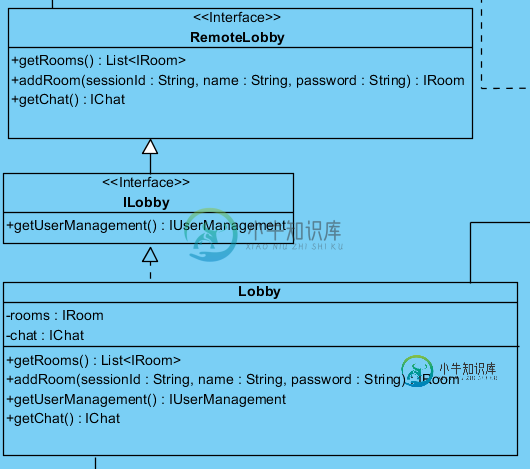 Java RMI分层接口
Java RMI分层接口我想写一个rmi应用程序。 远程调用中的每个方法都会抛出一个远程调用。ILoby中的方法没有。 编译时会出现以下错误: JAVArmi。服务器ExportException:远程对象实现非法远程接口;嵌套异常是: 在类和远程接口之间有接口吗? Ahsous
-
trigger.io分析通知ClassNotFoundException
尝试使用parse.com模块(https://trigger.io/modules/parse/current/docs/index.html)注册接收通知时,我在trigger.io控制台中收到以下错误。我在Linux和OSX上使用了最新的trigger.io和最新的Android SDK。 我是不是漏了配置中的什么东西?
-
在Flink中分裂流
如果我想在Flink中分裂一个流,那么最好的方法是什么?
-
GLEW 1.10.0分段故障
分段错误发生在 运行Glewinfo 运行VisualInfo 测试程序(详细信息如下) 调用glGetProgramInterfaceiv(详细信息如下) 使用gdb实现glewinfo的堆栈跟踪 使用gdb实现visualinfo的堆栈跟踪 下面是使用已安装的GLEW库和glfw3(3.0.3)的测试程序 编译: 运行前。/basic I设置 (否则我会得到分段错误,因为它试图使用安装的GLE
-
Word2vec Gensim精度分析
我正在开发一个NLP应用程序,在那里我有一个文本文件的语料库。我想使用Gensim word2vec算法创建单词向量。 我做了90%的训练和10%的测试。我在适当的集合上训练了模型,但我想在测试集合上评估模型的准确性。 我曾在互联网上浏览过关于准确性评估的任何文档,但我找不到任何允许我这样做的方法。有人知道做精度分析的函数吗? 我处理测试数据的方法是从测试文件夹中的文本文件中提取所有句子,并将其转
-
Spring数据mongo分页
我想用Spring Data Mongo实现分页。有很多教程和文档建议使用PagingAndSorting Repository,如下所示: 因此,因为PagingAndSorting Repository提供了用于分页查询的api,我可以像这样使用它: 我的问题是这里的findAll方法实际上是在哪里实现的?我需要自己编写它的实现吗?实现StoryRepo的StoryRepoImpl需要实现这个
-
特定分组算法
我正在编写一个程序,根据学生和导师的可用性来组建辅导小组。可用性是用字母表示的阻塞时间列表给出的。例如,如果一个学生以[A, C, D]的形式给出他的可用性,那么他在一天的第一、第三和第四个小时都有空。你如何制作一个函数,它接受学生列表和导师列表,并给出一组列表,从而最大限度地增加一组中的学生数量?我在Java工作,但我对算法比对代码本身更感兴趣。更多细节: 小组必须包含3-6名学生和1名导师。