《分奖金》专题
-
MySQL计算百分比
我有一个包含4个项的MySQL数据库:(数值)、、和。 在我的中,我需要根据“surveys”中的数字来计算接受调查的“employees”的百分比。 这就是我现在的说法: 下面是表格的原样: 我想根据中的数字计算参加调查的的百分比。即,如上面的数据所示,将为0%,将为95%。
-
ElasticSearch搜索部分url
我正在使用ElasticSearch5,找不到以下问题的解决方案:我想在文档中搜索带斜杠的字符串(url的一部分)。但它不会返回匹配的文档。我读过一些东西,带斜线的字符串被ES拆分,这不是我想要的字段。我尝试用映射在字段上设置“not_analysis”,但似乎无法使其工作。 “创建索引”:Put http://localhost:9200/test “添加文档”:post http://loca
-
SKlearn SGD部分拟合
我在这里做错了什么?我有一个很大的数据集,我想使用SCIKIT-Learn的SGDClassifier对其进行部分拟合 我做以下工作 我得到了错误 回溯(最近的调用为last):文件“/predict.py”,第48行,在sys.exit中(0 if main()else 1)文件“/predict.py”,第44行,在main predict()文件“/predict.py”,第38行,在pre
-
与日期的分离?
我在解析日期格式时出现异常? parseException:不可解析日期:“10-10-2016”
-
分配内存指针
我想知道何时或是否必须删除此对象。下面是一个基本类对象Object.cpp的构造函数: 我知道在分配内存时,你应该在某个时候删除它,但是我在构造函数中分配了内存,并且想再次使用变量1和2,我什么时候删除它们?
-
Apache FOP 2.2->2.3,分页
我在将FOP从2.2版迁移/升级到2.3版时遇到了一个问题。分页器停止工作…这是示例代码: 主要“模板”: 寻呼机1: 分页器2: 我得到的错误是: 严重:序列化页面1时出错。原因:java.io。NotSerializableException:org.apache.fop.fo.pagination。PageSequence java.io。NotSerializableException:o
-
Java 8分区列表
是否可以将纯 Jdk8 中的列表划分为相等的块(子列表)。 我知道使用Guava List类是可能的,但是我们可以用纯Jdk来做吗?我不想在我的项目中添加新罐子,只是为了一个用例。 索鲁顿: tagir-valeev提出了迄今为止最好的解决方案: 我还发现了其他三种可能性,但它们只适用于少数情况: 1.收藏家。partitioningBy()将列表拆分为2个子列表,如下所示: 2.Collecto
-
PHP合并分隔符
我正在尝试以特定的方式合并两个字符串。 基本上,我需要将前两个字符串合并到第三个字符串中,在它们之间有一个管道符号,然后用逗号分隔: 这两个将变成: 我希望这有意义?
-
SQL Server数据分组
SQL Server中分组查询通常用于配合聚合函数,实现分类汇总统计的信息。而其分类汇总的本质实际上就是先将信息排序,排序后相同类别的信息会聚在一起,然后通过需求进行统计计算。 SQL Server中常用的数据分组相关查询如下: GROUP BY - 根据指定列表达式列表中的值对查询结果进行分组。 HAVING - 指定组或聚合的搜索条件。 GROUPING SETS - 生成多个分组集。 CUB
-
 PDFBox分割PDF文档
PDFBox分割PDF文档主要内容:分割PDF文档中的页面,示例在前一章中,我们已经看到了如何将JavaScript添加到PDF文档。 现在来学习如何将给定的PDF文档分成多个文档。 分割PDF文档中的页面 可以使用类将给定的PDF文档分割为多个PDF文档。 该类用于将给定的PDF文档分成几个其他文档。 以下是拆分现有PDF文档的步骤 第1步:加载现有的PDF文档 使用类的静态方法加载现有的PDF文档。 此方法接受一个文件对象作为参数,因为这是一个静态方法,可
-
 Intellij Idea Profiler分析器
Intellij Idea Profiler分析器主要内容:什么是 VisualVM?,配置,监控应用,螺纹测量,抽样申请,CPU采样,内存采样,内存泄漏Profiler 提供了有关我们应用程序性能的准确信息。它通过我们的应用程序测量 CPU、内存和堆使用的性能。它还为我们提供了有关应用程序线程的详细信息。VisualVM 工具用于测量 Java 应用程序分析。 什么是 VisualVM? 它是一个可视化工具,已与 JDK 以及 Java 6 或更高版本捆绑在一起。它适合初学者,并提供有关我们应用程序性能的详细信息。 配置 在 Windows
-
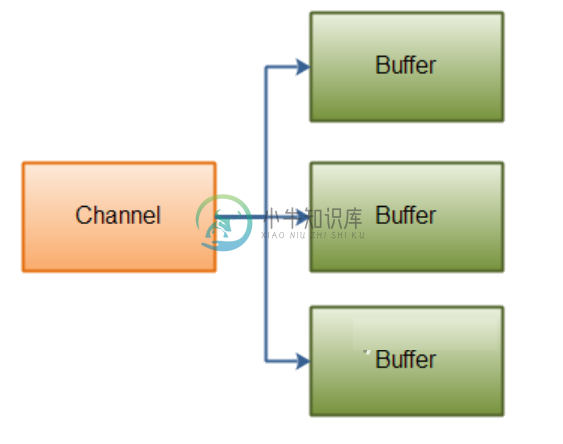 Java NIO 分散/聚集
Java NIO 分散/聚集主要内容:1 分散/聚集的介绍,2 分散读取,3 聚集写入1 分散/聚集的介绍 Java NIO带有内置的分散/聚集功能。分散/聚集是在读取和写入Channel中使用的概念。 从Channel分散读取是将数据读取到多个缓冲区中的读取操作。因此,通道将数据从通道“分散”到多个缓冲区中。 对Channel的聚集写入是一种将来自多个缓冲区的数据写入单个通道的写入操作。因此,通道将来自多个缓冲区的数据“聚集”到一个Channel中。 在需要分别处理传输数据的各个
-
 Java HashMap原理分析
Java HashMap原理分析主要内容:1 什么是哈希(散列)(Hashing),2 HashMap hashCode()方法,3 HashMap equals()方法,4 HashMap 存储桶,5 HashMap的索引计算过程,6 HashMap get()方法,7 HashMap原理分析完整代码本文主要介绍HashMap工作原理,了解哈希算法的计算过程。 1 什么是哈希(散列)(Hashing) 哈希是通过使用方法hashCode() 将对象转换为整数形式的过程。必须正确编写hashCode() 方法,以提高HashM
-
相似度得分-Levenshtein
问题内容: 我用Java实现了Levenshtein算法,现在可以通过算法进行更正,也就是成本。这确实有一点帮助,但并没有太大帮助,因为我希望将结果表示为百分比。 所以我想知道如何计算那些相似点。 我也想知道你们的人民是如何做的以及为什么。 问题答案: 两个字符串之间的Levenshtein距离定义为将一个字符串转换为另一个字符串所需的最小编辑次数,允许的编辑操作为单个字符的插入,删除或替换。(维
-
随机分布均匀
问题内容: 我知道如果我使用Java的Random生成器,并使用nextInt生成数字,则数字将均匀分布。但是,如果我使用2个Random实例,并使用两个Random类生成数字,会发生什么。数字是否会均匀分布? 问题答案: 每个实例生成的数字将均匀分布,因此,如果将两个实例生成的随机数序列组合在一起,则它们也应均匀分布。 请注意,即使结果分布是均匀的,您也可能要注意种子,以避免两个生成器的输出之间