《分奖金》专题
-
TensorFlow分布式计算
本章将重点介绍如何开始使用分布式TensorFlow。目的是帮助开发人员了解重复出现的基本分布式TF概念,例如TF服务器。我们将使用Jupyter Notebook来评估分布式TensorFlow。使用TensorFlow实现分布式计算如下所述 - 第1步 - 为分布式计算导入必需的模块 - 第2步 - 使用一个节点创建TensorFlow集群。让这个节点负责一个名称为“worker”的作业,并在
-
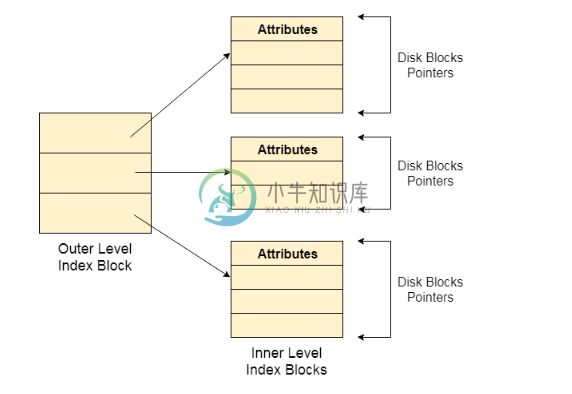 链接索引分配
链接索引分配主要内容:多级索引分配单级链接索引分配 在索引分配中,文件大小取决于磁盘块的大小。 要允许大文件,我们必须将几个索引块链接在一起。在链接索引分配中, 提供文件名称的小标题 前100个块地址的集合 指向另一个索引块的指针 对于较大的文件,索引块的最后一个条目是一个指向另一个索引块的指针。 这也被称为链接模式。 优点: 它消除了文件大小限制 缺点: 随机访问变得有点困难 多级索引分配 在多级指数分配中,有各种索引级别。 有
-
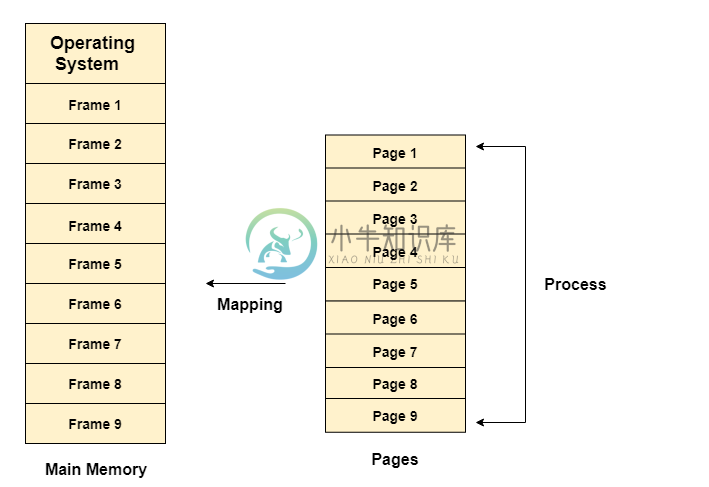 分页技术实例
分页技术实例主要内容:内存管理单元在操作系统中,分页是一种存储机制,用于以页面形式从辅助存储器检索进程到主内存中。 分页背后的主要思想是以页面的形式划分每个进程。 主存也将以帧的形式分割。 进程的一页将被存储在存储器的一个帧中。 分页可以存储在内存的不同位置,但优先级始终是查找连续的帧或空洞。 进程页面只有在需要时才会被带入主内存,否则它们将驻留在辅助存储中。 不同的操作系统定义不同的帧大小。 每个帧的大小必须相等。 考虑到页面被
-
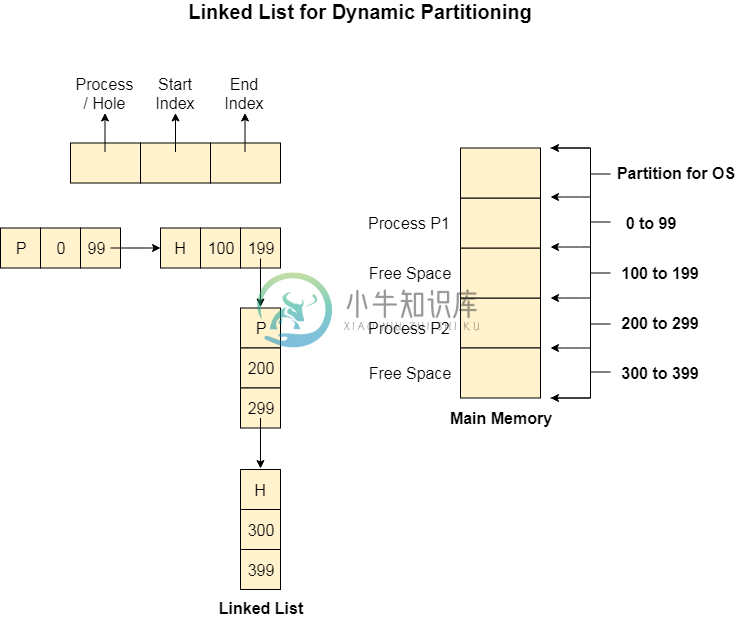 链表动态分区
链表动态分区跟踪自由或填充分区的更好和最流行的方法是使用链表。 在这种方法中,操作系统维护一个链表,每个节点代表每个分区。 每个节点都有三个字段。 节点的第一个字段存储一个标志位,该标志位显示该分区是一个洞还是某个进程在里面。 第二个字段存储分区的起始索引。 第三个字段存储分区的结束索引。 如果某个分区在某个时间点被释放,那么该分区将与其相邻的空闲分区合并,而不会做任何额外的工作。 在使用这种方法时需要注意一
-
YAML缩进和分离
主要内容:YAML的缩进,分离字符串当学习任何编程语言时,缩进和分离是两个主要概念。本章详细讨论了与YAML相关的这两个概念。 YAML的缩进 YAML不包括任何强制性空格。此外,没有必要保持一致。有效的YAML缩进如下所示 - 在YAML中使用缩进时,应该记住以下规则:流块必须至少包含一些具有周围当前块级别的空格。 YAML的流含量跨越多条线。流内容以或开头。 阻止列表项包括与周围块级相同的缩进,因为 符号被视为缩进的一部分。 预
-
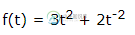 Matlab微分和导数
Matlab微分和导数主要内容:基本微分规则的验证,指数,对数和三角函数的导数,计算高阶导数,查找曲线的最大和最小值,求解微分方程MATLAB提供用于计算符号导数的命令。 以最简单的形式,将要微分的功能传递给命令作为参数。 例如,计算函数的导数的方程式 - 例子 创建脚本文件并在其中键入以下代码 - 执行上面示例代码,得到以下结果 - 以下是使用Octave 计算的写法 - 执行上面示例代码,得到以下结果 - 基本微分规则的验证 下面简要说明微分规则的各种方程或规则,并验证这些规则。 为此,我们将写一个第一阶导数和二
-
 5.3 Verilog 时钟分频
5.3 Verilog 时钟分频主要内容:实例,实例,实例,实例,实例关键词:偶数分频,奇数分频,半整数分频,小数分频 初学 Verilog 时许多模块都是由计数器与分频器组成的,例如 PWM 脉宽调制、频率计等。分频逻辑也往往通过计数逻辑完成。本节主要对偶数分频、奇数分频、半整数分频以及小数分频进行简单的总结。 偶数分频 采用触发器反向输出端连接到输入端的方式,可构成简单的 2 分频电路。 以此为基础进行级联,可构成 4 分频,8 分频电路。 电路实现如下图所示,
-
SQLite 分离数据库
主要内容:语法,实例SQLite 的 DETACH DATABASE 语句是用来把命名数据库从一个数据库连接分离和游离出来,连接是之前使用 ATTACH 语句附加的。如果同一个数据库文件已经被附加上多个别名,DETACH 命令将只断开给定名称的连接,而其余的仍然有效。您无法分离 main 或 temp 数据库。 如果数据库是在内存中或者是临时数据库,则该数据库将被摧毁,且内容将会丢失。 语法 SQLite 的 DET
-
 二分查找算法
二分查找算法主要内容:二分查找算法的实现思路,二分查找算法的具体实现二分查找又称 折半查找、 二分搜索、 折半搜索等,是在 分治算法基础上设计出来的查找算法,对应的时间复杂度为 。 二分查找算法仅适用于有序序列,它只能用在升序序列或者降序序列中查找目标元素。 二分查找算法的实现思路 在有序序列中,使用二分查找算法搜索目标元素的核心思想是:不断地缩小搜索区域,降低查找目标元素的难度。 以在升序序列中查找目标元素为例,二分查找算法的实现思路是: 初始状态下,将整个序列
-
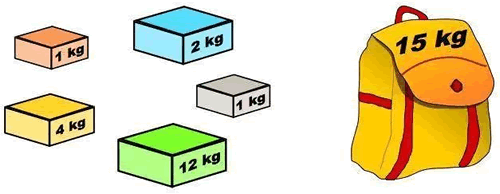 部分背包问题
部分背包问题主要内容:贪心算法解决部分背包问题在限定条件下,如何从众多物品中选出收益最高的几件物品,这样的问题就称为背包问题。 图 1 背包问题 举个简单的例子,商店的货架上摆放着不同重量和价值的商品,一个小偷在商店行窃,他携带的背包只能装固定重量的商品,选择哪些商品才能获得最大的收益呢?这个问题就属于背包问题,限定条件是背包的承重,最终目标是令背包中存放的物品的总收益最高。 根据不同的限定条件,背包问题还可以有更细致的划分: 0-1 背
-
Python Pandas分层索引
主要内容:创建分层索引,应用分层索引,分层索引切片取值,聚合函数应用,局部索引,行索引层转换为列索引,列索引实现分层,交换层和层排序分层索引(Multiple Index)是 Pandas 中非常重要的索引类型,它指的是在一个轴上拥有多个(即两个以上)索引层数,这使得我们可以用低维度的结构来处理更高维的数据。比如,当想要处理三维及以上的高维数据时,就需要用到分层索引。 分层索引的目的是用低维度的结构(Series 或者 DataFrame)更好地处理高维数据。通过分层索引,我们可以像处理二维数据
-
Python Pandas分类对象
主要内容:对象创建,获取统计信息,获取类别属性,重命名类别,追加新类别,删除类别,分类对象比较通常情况下,数据集中会存在许多同一类别的信息,比如相同国家、相同行政编码、相同性别等,当这些相同类别的数据多次出现时,就会给数据处理增添许多麻烦,导致数据集变得臃肿,不能直观、清晰地展示数据。 针对上述问题,Pandas 提供了分类对象(Categorical Object),该对象能够实现有序排列、自动去重的功能,但是它不能执行运算。本节,我们了解一下分类对象的使用。 对象创建 我们可以通过多种
-
Pandas groupby分组操作
主要内容:创建DataFrame对象,创建groupby分组对象,查看分组结果,遍历分组数据,应用聚合函数,组的转换操作,组的数据过滤操作在数据分析中,经常会遇到这样的情况:根据某一列(或多列)标签把数据划分为不同的组别,然后再对其进行数据分析。比如,某网站对注册用户的性别或者年龄等进行分组,从而研究出网站用户的画像(特点)。在 Pandas 中,要完成数据的分组操作,需要使用 groupby() 函数,它和 SQL 的 操作非常相似。 在划分出来的组(group)上应用一些统计函数,从而达到
-
MySQL日志及分类
日志是数据库的重要组成部分,主要用来记录数据库的运行情况、日常操作和错误信息。 在 MySQL 中,日志可以分为二进制日志、错误日志、通用查询日志和慢查询日志。对于 MySQL 的管理工作而言,这些日志文件是不可缺少的。分析这些日志,可以帮助我们了解 MySQL 数据库的运行情况、日常操作、错误信息和哪些地方需要进行优化。 下面简单介绍 MySQL 中 4 种日志文件的作用。 二进制日志:该日志文
-
Java分割字符串
String 类的 split() 方法可以按指定的分割符对目标字符串进行分割,分割后的内容存放在字符串数组中。该方法主要有如下两种重载形式: 其中它们的含义如下: str 为需要分割的目标字符串。 sign 为指定的分割符,可以是任意字符串。 limit 表示分割后生成的字符串的限制个数,如果不指定,则表示不限制,直到将整个目标字符串完全分割为止。 使用分隔符注意如下: 1)“.”和“|”都是转