《分奖金》专题
-
Redis分布式锁
主要内容:Redis分布式锁介绍,Redis分布式锁命令在分布式系统中,当不同进程或线程一起访问共享资源时,会造成资源争抢,如果不加以控制的话,就会引发程序错乱。此时使用分布式锁能够非常有效的解决这个问题,它采用了一种互斥机制来防止线程或进程间相互干扰,从而保证了数据的一致性。 提示:如果对分布式系统这一概念不清楚,可参考百度百科《分布式系统》,简而言之,它是一种架构、一种模式。 Redis分布式锁介绍 分布式锁并非是 Redis 独有,比如 MySQ
-
Redis分区技术
主要内容:分区的优势,分区常用方法,分区技术的不足,分区技术问题解决Redis 分区技术(又称 Redis Partition)指的是将 Redis 中的数据进行拆分,然后把拆分后的数据分散到多个不同的 Redis 实例(即服务器)中,每个实例仅存储数据集的某一部分(一个子集),我们把这个过程称之为 Redis 分区操作。 Redis 实例指的是一台安装了 Redis 服务器的计算机。 分区(Partition)不仅是 Redis 中的概念,几乎所有数据库管理系统
-
MySQL过滤分组
在 MySQL 中,可以使用 HAVING 关键字对分组后的数据进行过滤。 使用 HAVING 关键字的语法格式如下: HAVING <查询条件> HAVING 关键字和 WHERE 关键字都可以用来过滤数据,且 HAVING 支持 WHERE 关键字中所有的操作符和语法。 但是 WHERE 和 HAVING 关键字也存在以下几点差异: 一般情况下,WHERE 用于过滤数据行,而 HAVING 用
-
MySQL分组查询
主要内容:GROUP BY单独使用,GROUP BY 与 GROUP_CONCAT() ,GROUP BY 与聚合函数,GROUP BY 与 WITH ROLLUP在 MySQL 中, GROUP BY 关键字可以根据一个或多个字段对查询结果进行分组。 使用 GROUP BY 关键字的语法格式如下: GROUP BY <字段名> 其中,“字段名”表示需要分组的字段名称,多个字段时用逗号隔开。 GROUP BY单独使用 单独使用 GROUP BY 关键字时,查询结果会只显示每个分组的第一条记录。
-
 C++面经分享
C++面经分享#面经# #秋招# 游戏开发类: 1.自我介绍 2.介绍一个你觉得最难的数据结构或者算法 3.字符串哈希在游戏开发中的应用 4.C++多态的实现(函数重载 虚函数) 5.函数重载编译时的细节(返回类型,函数名,6.函数参数决定编译后的函数名) 7.中断时需要保存的上下文有哪些 8.TCP和UDP的区别 9.游戏本来采用TCP,后改为UDP,后续有哪些地方可以优化 10.数据库需要查找5000-1
-
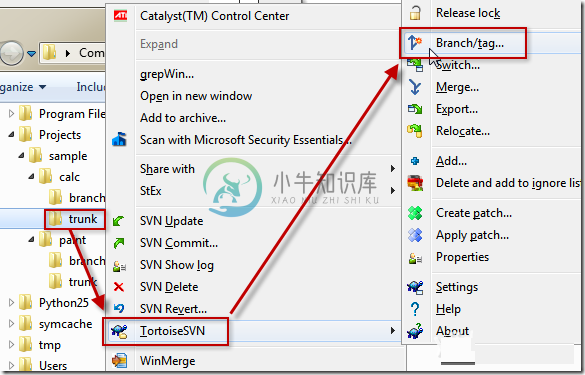 TortoiseSVN-分支管理
TortoiseSVN-分支管理主要内容:一、分支与合并的概念,二、 SVN分支的意义,三、 如何创建分支与合并分支一、分支与合并的概念 分支:版本控制系统的一个特性是能够把各种修改分离出来放在开发品的一个分割线上。这条线被称为分支。分支经常被用来试验新的特性,而不会对开发有编译错误的干扰。当新的特性足够稳定之后,开发品的分支就可以混合回主分支里(主干线)。 合并:分支用来维护独立的开发支线,在一些阶段,你可能需要将分支上的修改合并到最新版本,或者将最新版本的修改合并到分支。 二、 SVN分支的意义 简单说,分
-
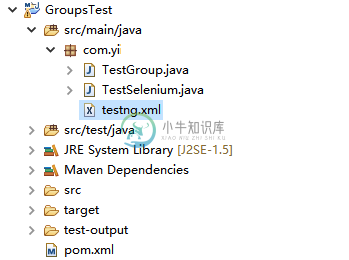 TestNG分组测试
TestNG分组测试主要内容:1. 在方法上的分组,2. 在类上的分组,3. 其它分组分组测试是TestNG中的一个新的创新功能,它在JUnit框架中是不存在的。 它允许您将方法调度到适当的部分,并执行复杂的测试方法分组。 您不仅可以声明属于某个分组的方法,还可以指定包含其他组的组。 然后调用,并要求其包含一组特定的组(或正则表达式),同时排除另一个分组。 组测试提供了如何分区测试的最大灵活性,如果您想要背靠背运行两组不同的测试,则不需要重新编译任何内容。 使用标记在文件中指定分组
-
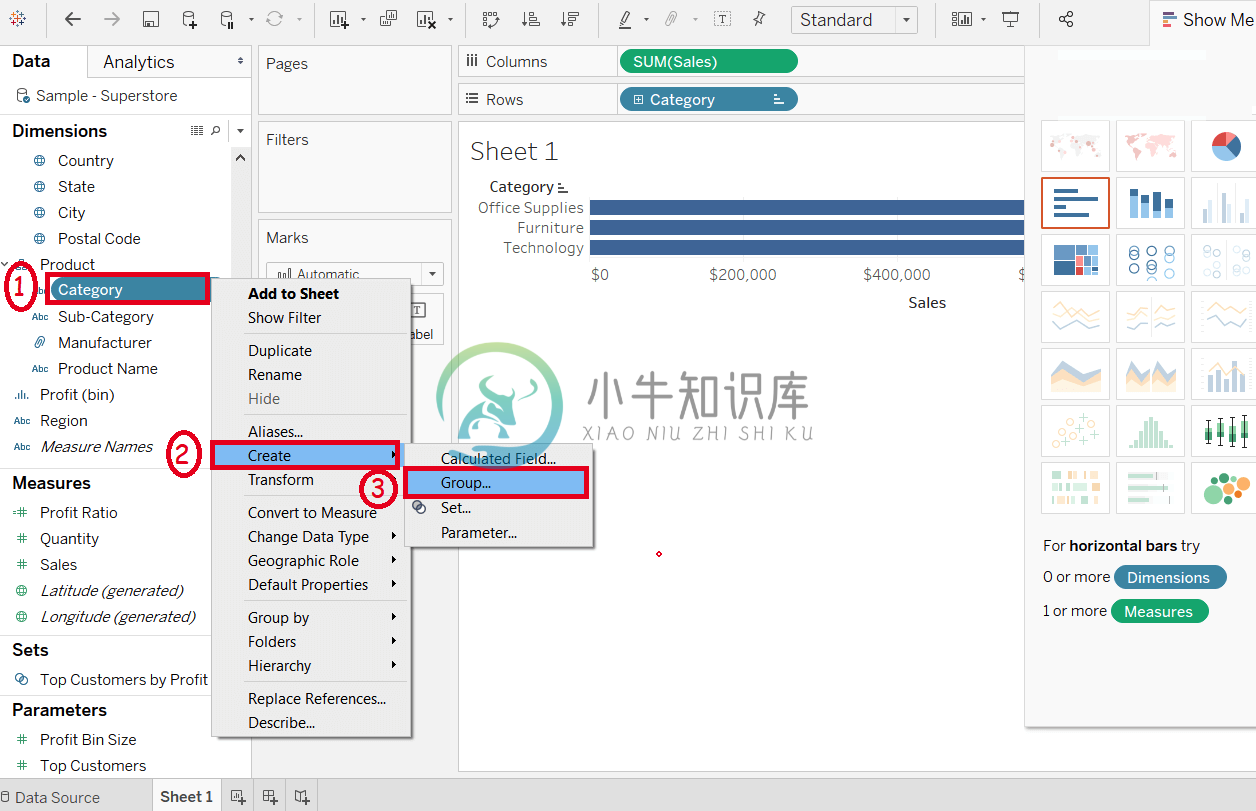 Tableau构建分组
Tableau构建分组创建一个分组来组合该领域的相关成员。如果您使用视图,并且希望将特定字段分组以创建重要类别。 例如,考虑数据源(例如sample-superstore),然后拖动行架中的Sales字段和行架中的Category字段,然后按升序对它们进行排序(在Tableau排序数据中讨论)。 家具(Furniture)和办公用品(Office Supplies)的总价值可以通过使用分组获得。 组建完成后,家具(Fu
-
 GitLab周期分析
GitLab周期分析Cycle Analytics指定团队花费多少时间完成工作流程的每个阶段,并允许GitLab将开发工作数据存储在一个中央数据存储中。 周期分析页面可以在Overview 部分下找到。 步骤(1): 登录到您的GitLab帐户并转到您的项目: 步骤(2): 单击Overview 选项卡下的Cycle Analytics 选项,将打开如下所示的屏幕: 周期分析包含以下阶段: 问题: 它指定了多少时间来
-
 GitLab分叉项目
GitLab分叉项目主要内容:创建一个分支分支是独立的线路和开发过程的一部分。 分支的创建包括以下步骤。 创建一个分支 步骤(1): 登录到您的GitLab帐户并转到项目部分下的项目。 步骤(2): 要创建分支,请单击“Repository” 部分下的 Branches 选项,然后单击“New branch” 按钮。 步骤(3): 在New branch 界面中,输入分支的名称,然后单击 Create branch 按钮。 步骤(4):
-
 GitLab分叉项目
GitLab分叉项目主要内容:分叉项目分叉(Fork)是原始存储库的一个副本,您可以在不影响原始项目的情况下进行更改。 分叉项目 步骤(1): 要分叉一个项目,请项目详细下面单击按钮,以上节中创建的项目为例,如下所示: 步骤(2): 在分叉项目之后,需要通过单击将分叉的项目添加到分支组: 注意:如果提示没有命名空间权限(namespace),可以先创建一个分组后,再创建分叉。 步骤(3): 接下来,它将开始处理项目一段时间。 步骤(4
-
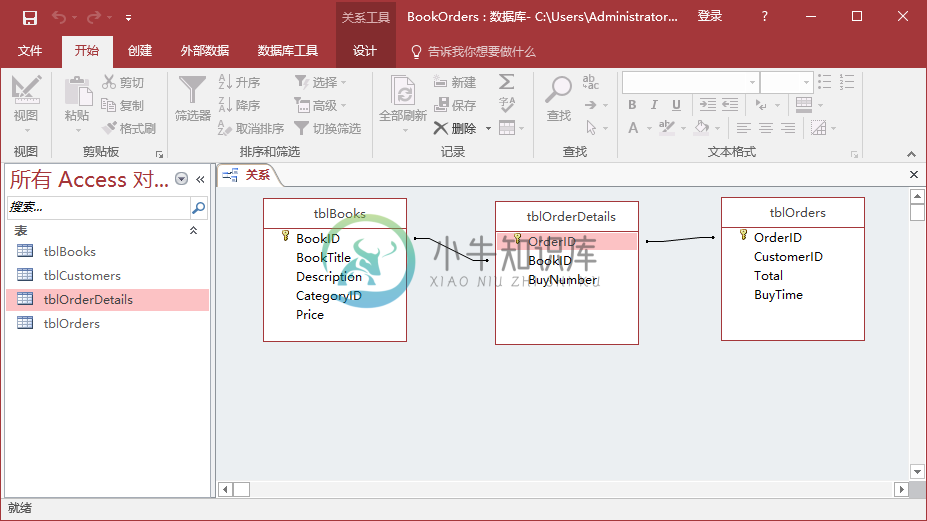 Access分组数据
Access分组数据主要内容:聚合查询,Access中的连接,示例在本章中,我们将介绍Access中如何计算如何分组记录。 我们创建了一个按行计算或按记录计算的字段来创建行总计或小计字段,但是如果想通过分组记录而不是单个记录来计算,那该怎么办呢? 可以通过创建聚合查询来实现这一点。 聚合查询 聚合查询也称为总计或汇总查询是总和,质量或组的详细信息。它可以是总金额或总金额或记录的组或子集。 聚合查询可以执行许多操作。下面是一个简单的表格,列出了分组记录中总的方法。
-
Junit4 分类测试
主要内容:1 Junit分类测试的介绍,2 在Maven中进行分类测试,3 在Gradle中进行分类测试,4 在SBT中进行分类测试,5 分类测试的典型用法1 Junit分类测试的介绍 从给定的一组测试类中,类别运行器仅运行用@IncludeCategory批注指定的类别或该类别的子类型进行批注的类和方法。类或接口都可以用作类别。子类型有效,因此,如果您说@IncludeCategory(SuperClass.class),则会运行标记为@Category({SubClass.class})的测
-
KMALLOC大小分配
问题内容: KMALLOC是仅在页面大小的内存中分配还是可以分配较少的内存?kmalloc可以分配多少大小?我在哪里可以找到它的描述,因为到处看都没有真正说出它分配了多少内存?我想知道KMALLOC分配的实际大小是多少。是否分配2的幂的大小?它只是从准备就绪的缓存中查找可用对象吗? 问题答案: 我的理解如下:内核正在处理系统的物理内存,仅在页面大小的块中可用;因此,在调用时,您将仅获得某些预定义的
-
分叉与线程
问题内容: 我以前在应用程序中使用过线程,并且对线程的概念非常了解,但是最近在我的操作系统讲座中,我遇到了fork()。这类似于线程。 我用谷歌搜索了它们之间的区别,我知道: Fork只是一个看起来与旧流程或父流程完全相似的新流程,但它仍然是具有不同流程ID并拥有自己内存的不同流程。 线程是轻量级进程,具有较少的开销 但是,我仍然有一些疑问。 什么时候应该更喜欢fork()而不是线程? 如果我想以