《分奖金》专题
-
Spark中的分区和扣分有什么区别?
我试图优化两个spark dataframes之间的联接查询,让我们将它们称为df1、df2(在公共列“saleid”上联接)。df1非常小(5M),所以我在spark集群的节点中广播它。df2非常大(200米行),所以我尝试通过“saleid”对它进行桶/重新分区。 例如: 分区: 水桶: 我不知道哪一个是正确的技术使用。谢谢。
-
如何将字符串拆分为多个部分?
我有一个字符串和一个ArrayList。字符串中有几个单词,用空格隔开,例如“firstword second third”。我想将字符串拆分为几个部分,并将“piece”字符串添加到ArrayList中。
-
Spark DataFrame重新分区:未保留的分区数
根据Spark 1.6.3的文档,应该保留结果数据表中的分区数: 返回由给定分区表达式分区的新DataFrame,保留现有的分区数 Edit:这个问题并不涉及在Apache Spark中删除空DataFrame分区的问题(例如,如何在不产生空分区的情况下沿列重新分区),而是为什么文档所说的内容与我在示例中观察到的内容不同
-
火花重新分区不均匀分布记录
-
 得物L【95分】商业分析师面试0221~
得物L【95分】商业分析师面试0221~今年第三家面试公司是得物旗下的95分商业分析师。现在看录音回放,感觉当时的回答好糟糕啊!!! 面试得物的是一个超级无敌温柔的商业分析师。感觉就像是小姐姐一样亲切一直引导你,但我还是经验尚浅。准备的不够充分吧。 开头一贯都是先让做自我介绍。 然后接下来就问我目前所在位置+实习能够实习多久之类的问题。 接下来就是扔给我之前HR发我的两道题,一道是有关费米估算问题的求解,另一道是SQL题。 费米估算问题
-
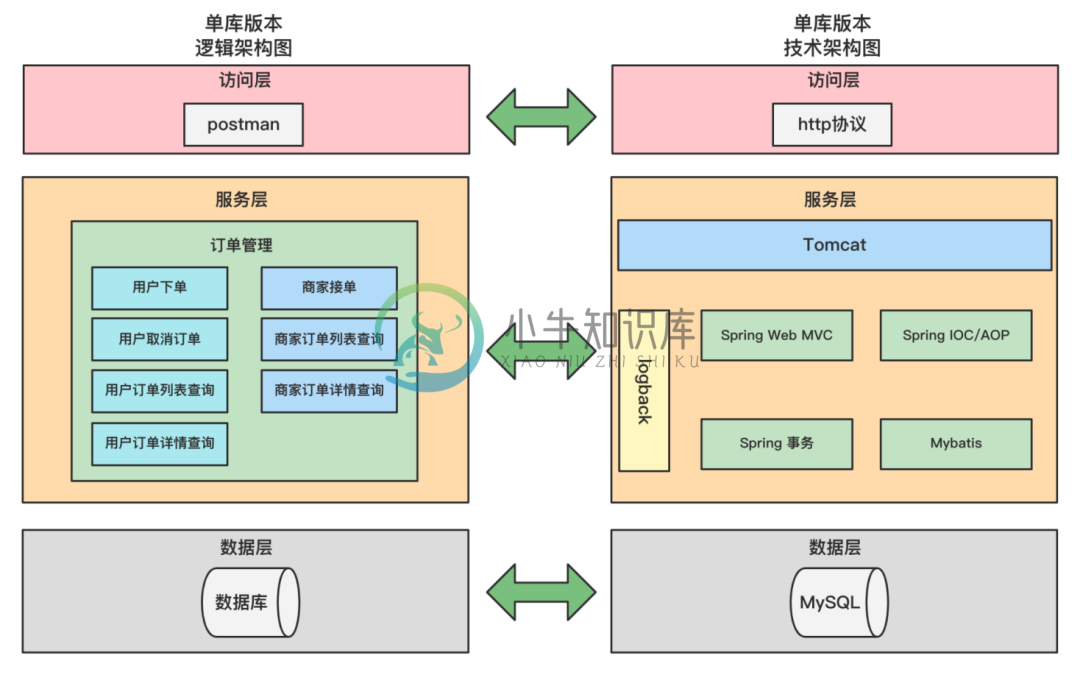 基于订单系统的分库分表实战
基于订单系统的分库分表实战主要内容:前 言,认识一下单库版本的订单系统,业务快速增长,驱动系统架构不断演进,来看一下分库分表版本的订单系统架构,结束语前 言 各位读者朋友,大家好,这是分库分表实战的第一篇文章,首先介绍一下"基于ShardingSphere的分库分表实战"的设计思路及内容。 本实战的重点是分库分表实战,比较适合1~3年工作经验的程序员朋友。实战主要以外卖APP中的外卖订单来作为本次实战的核心业务。 基于外卖订单业务,儒猿技术团队开发了一个外卖订单项目,通过该项目逐步分析随着订单数据量逐步增加,系统将遇到什
-
乐观模式下分库分表合并迁移
本文介绍了 DM 提供的乐观模式下分库分表的合并迁移功能,此功能可用于将上游 MySQL/MariaDB 实例中结构相同/不同的表迁移到下游 TiDB 的同一个表中。 注意: 在没有深入了解乐观模式的原理和使用限制的情况下不建议使用该模式,否则可能造成迁移中断甚至数据不一致的严重后果。 背景 DM 支持在线上执行分库分表的 DDL 语句(通称 Sharding DDL),默认使用“悲观模式”,即当
-
悲观模式下分库分表合并迁移
本文介绍了 DM 提供的悲观模式(默认模式)下分库分表合并迁移功能。此功能用于将上游 MySQL/MariaDB 实例中结构相同的表迁移到下游 TiDB 的同一个表中。 使用限制 DM 在悲观模式下进行分表 DDL 的迁移有以下几点使用限制: 在一个逻辑 sharding group(需要合并迁移到下游同一个表的所有分表组成的 group)内,所有上游分表必须以相同的顺序执行相同的 DDL 语句(
-
分布式部署 - 为什么分布式部署
1、成倍提高系统承载能力并降低成本 单机遇到资源瓶颈时,要想支持更大的用户量,一般是优化业务和增加服务器配置。然而这么做只能是杯水车薪,成本巨大并且效果非常有限。 GatewayWorker支持分布式部署,你可以利用多台价格低廉的普通服务器,组成一个庞大的服务器集群,成倍的增加系统承载能力,这不管在资金成本上还是人力成本上都是最划算的方案。 2、提高系统稳定性 单机对外提供服务,则风险很大,服务器
-
二分查找 - *旋转后的二分查找[H]
Suppose a sorted array is rotated at some pivot unknown to you beforehand. (i.e., 0 1 2 4 5 6 7 might become 4 5 6 7 0 1 2). You are given a target value to search. If found in the array return its in
-
4.14 基于分水岭算法的图像分割
目标 在这一章当中, 我们将学习使用基于标记的分水岭算法来进行图像分割 我们将看到:cv2.watershed() 理论基础 任何灰度图像可以被看作是一个地形表面,其中高强度表示峰和山,而低强度表示山谷。你开始用不同颜色的水(标签)填充每个孤立的山谷(局部最小值)。随着水位上升,根据附近的山峰(梯度),来自不同山谷的水,明显不同的颜色将开始合并。为了避免这种情况,你在水合并的地方建立障碍。你继续填
-
Spring 工具分类-依据组织形式分类
下面是几种常见的Spring工具的类型 : – 静态工具方法类 通常以作为类名后缀 类的成员函数定义为 一般不通过创建类实例方式使用,而是通过直接被使用 一般完全无状态,(即使有状态,也一般是维护类静态成员属性static member field ) 工具方法命名通常可以"望文知意",可以知道其目的 – "某某"配置器 – "某某"增强器 – "某某"加载器 – "某某"后置处理器 – "某某"
-
六、监督学习第二部分:回归分析
在回归中,我们试图预测连续输出变量 - 而不是我们在之前的分类示例中预测的标称变量。 让我们从一个简单的玩具示例开始,其中包含一个特征维度(解释性变量)和一个目标变量。 我们将使用一些噪声从正弦曲线创建数据集: x = np.linspace(-3, 3, 100) print(x) rng = np.random.RandomState(42) y = np.sin(4 * x) + x +
-
分布式缓存
问题内容: 我正在寻找Java分布式缓存解决方案。我们希望功能喜欢: 我们已经分析了Terracotta这样的框架,它似乎是缓存框架中我们想要的一切……但是,似乎需要一个中央缓存节点,这成为我们的单点故障。 除了推出我们自己的解决方案之外,还有其他想法吗? 问题答案: 我建议使用JBossCache或EhCache(使用分布式缓存侦听器)。我都用过,我都喜欢,它们都适合您的要求。
-
分页在java中?
问题内容: 我希望数字以这种格式显示。 1 2 3 4 5 ^ 如果我按5,则应该显示5到10 5 6 7 8 9 10 直到最大记录可用。我只想知道如何显示数字。 问题答案: 通常,您希望数据库为分页和排序工作繁重。例如,使用MySQL,您可以通过添加以下内容按日期对结果页面进行排序 到SQL查询的末尾。如果您使用休眠模式,则可以使用标准API以独立于供应商的方式执行此操作: 要显示分页导航,您